
目前CSDN,博客園,簡書同步發表中,更多精彩歡迎訪問我的gitee pages HDFS NN,2NN,DN及HDFS2.x新特性 NameNode和SecondaryNameNode(重點) NN和2NN工作機制 第一階段:NameNode啟動 第一次啟動NameNode格式化後,創建fsima ...
目前CSDN,博客園,簡書同步發表中,更多精彩歡迎訪問我的gitee pages
目錄
HDFS NN,2NN,DN及HDFS2.x新特性
NameNode和SecondaryNameNode(重點)
NN和2NN工作機制

- 第一階段:NameNode啟動
- 第一次啟動NameNode格式化後,創建fsimage和edits文件。如果不是第一次啟動,直接載入編輯日誌和鏡像文件到記憶體。
- 客戶端對元數據進行增刪改的請求。
- NameNode記錄操作日誌,更新滾動日誌。
- NameNode在記憶體中對數據進行增刪改。
- 第二階段:Secondary NameNode工作
- Secondary NameNode詢問NameNode是否需要CheckPoint。直接帶回NameNode是否檢查結果。
- Secondary NameNode請求執行CheckPoint。
- NameNode滾動正在寫的Edits日誌。
- 將滾動前的編輯日誌和鏡像文件拷貝到Secondary NameNode。
- Secondary NameNode載入編輯日誌和鏡像文件到記憶體,併合並。
- 生成新的鏡像文件fsimage.chkpoint。
- 拷貝fsimage.chkpoint到NameNode。
- NameNode將fsimage.chkpoint重新命名成fsimage。
NN和2NN工作機制詳解
Fsimage:NameNode記憶體中元數據序列化後形成的文件。
Edits:記錄客戶端更新元數據信息的每一步操作(可通過Edits運算出元數據)。
NameNode啟動時,先滾動Edits並生成一個空的edits.inprogress,然後載入Edits和Fsimage到記憶體中,此時NameNode記憶體就持有最新的元數據信息。Client開始對NameNode發送元數據的增刪改的請求,這些請求的操作首先會被記錄到edits.inprogress中(查詢元數據的操作不會被記錄在Edits中,因為查詢操作不會更改元數據信息),如果此時NameNode掛掉,重啟後會從Edits中讀取元數據的信息。然後,NameNode會在記憶體中執行元數據的增刪改的操作。
由於Edits中記錄的操作會越來越多,Edits文件會越來越大,導致NameNode在啟動載入Edits時會很慢,所以需要對Edits和Fsimage進行合併(所謂合併,就是將Edits和Fsimage載入到記憶體中,照著Edits中的操作一步步執行,最終形成新的Fsimage)。SecondaryNameNode的作用就是幫助NameNode進行Edits和Fsimage的合併工作。
SecondaryNameNode首先會詢問NameNode是否需要CheckPoint(觸發CheckPoint需要滿足兩個條件中的任意一個,定時時間到和Edits中數據寫滿了)。直接帶回NameNode是否檢查結果。SecondaryNameNode執行CheckPoint操作,首先會讓NameNode滾動Edits並生成一個空的edits.inprogress,滾動Edits的目的是給Edits打個標記,以後所有新的操作都寫入edits.inprogress,其他未合併的Edits和Fsimage會拷貝到SecondaryNameNode的本地,然後將拷貝的Edits和Fsimage載入到記憶體中進行合併,生成fsimage.chkpoint,然後將fsimage.chkpoint拷貝給NameNode,重命名為Fsimage後替換掉原來的Fsimage。NameNode在啟動時就只需要載入之前未合併的Edits和Fsimage即可,因為合併過的Edits中的元數據信息已經被記錄在Fsimage中。
Fsimage和Edits解析
- 概念

-
oiv查看Fsimage文件
-
查看oiv和oev命令
[atguigu@hadoop101 current]$ hdfs oiv apply the offline fsimage viewer to an fsimage oev apply the offline edits viewer to an edits file -
基本語法
hdfs oiv -p 文件類型 -i鏡像文件 -o 轉換後文件輸出路徑 -
案例實操
[atguigu@hadoop101 current]$ pwd /opt/module/hadoop-2.7.2/data/tmp/dfs/name/current [atguigu@hadoop101 current]$ hdfs oiv -p XML -i fsimage_0000000000000000025 -o /opt/module/hadoop-2.7.2/fsimage.xml [atguigu@hadoop101 current]$ cat /opt/module/hadoop-2.7.2/fsimage.xml查看xml文件,部分顯示結果如下
<inode> <id>16386</id> <type>DIRECTORY</type> <name>user</name> <mtime>1512722284477</mtime> <permission>atguigu:supergroup:rwxr-xr-x</permission> <nsquota>-1</nsquota> <dsquota>-1</dsquota> </inode> <inode> <id>16387</id> <type>DIRECTORY</type> <name>atguigu</name> <mtime>1512790549080</mtime> <permission>atguigu:supergroup:rwxr-xr-x</permission> <nsquota>-1</nsquota> <dsquota>-1</dsquota> </inode> <inode> <id>16389</id> <type>FILE</type> <name>wc.input</name> <replication>3</replication> <mtime>1512722322219</mtime> <atime>1512722321610</atime> <perferredBlockSize>134217728</perferredBlockSize> <permission>atguigu:supergroup:rw-r--r--</permission> <blocks> <block> <id>1073741825</id> <genstamp>1001</genstamp> <numBytes>59</numBytes> </block> </blocks> </inode >-
思考:可以看出,Fsimage中沒有記錄塊所對應DataNode,為什麼?
在集群啟動後,要求DataNode上報數據塊信息,並間隔一段時間後再次上報。
-
-
-
oev查看Edits文件
-
基本語法
hdfs oev -p 文件類型 -i編輯日誌 -o 轉換後文件輸出路徑 -
案例實操
[atguigu@hadoop101 current]$ hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-2.7.2/edits.xml [atguigu@hadoop101 current]$ cat /opt/module/hadoop-2.7.2/edits.xml查看xml文件
<?xml version="1.0" encoding="UTF-8"?> <EDITS> <EDITS_VERSION>-63</EDITS_VERSION> <RECORD> <OPCODE>OP_START_LOG_SEGMENT</OPCODE> <DATA> <TXID>129</TXID> </DATA> </RECORD> <RECORD> <OPCODE>OP_ADD</OPCODE> <DATA> <TXID>130</TXID> <LENGTH>0</LENGTH> <INODEID>16407</INODEID> <PATH>/hello7.txt</PATH> <REPLICATION>2</REPLICATION> <MTIME>1512943607866</MTIME> <ATIME>1512943607866</ATIME> <BLOCKSIZE>134217728</BLOCKSIZE> <CLIENT_NAME>DFSClient_NONMAPREDUCE_-1544295051_1</CLIENT_NAME> <CLIENT_MACHINE>192.168.1.5</CLIENT_MACHINE> <OVERWRITE>true</OVERWRITE> <PERMISSION_STATUS> <USERNAME>atguigu</USERNAME> <GROUPNAME>supergroup</GROUPNAME> <MODE>420</MODE> </PERMISSION_STATUS> <RPC_CLIENTID>908eafd4-9aec-4288-96f1-e8011d181561</RPC_CLIENTID> <RPC_CALLID>0</RPC_CALLID> </DATA> </RECORD> <RECORD> <OPCODE>OP_ALLOCATE_BLOCK_ID</OPCODE> <DATA> <TXID>131</TXID> <BLOCK_ID>1073741839</BLOCK_ID> </DATA> </RECORD> <RECORD> <OPCODE>OP_SET_GENSTAMP_V2</OPCODE> <DATA> <TXID>132</TXID> <GENSTAMPV2>1016</GENSTAMPV2> </DATA> </RECORD> <RECORD> <OPCODE>OP_ADD_BLOCK</OPCODE> <DATA> <TXID>133</TXID> <PATH>/hello7.txt</PATH> <BLOCK> <BLOCK_ID>1073741839</BLOCK_ID> <NUM_BYTES>0</NUM_BYTES> <GENSTAMP>1016</GENSTAMP> </BLOCK> <RPC_CLIENTID></RPC_CLIENTID> <RPC_CALLID>-2</RPC_CALLID> </DATA> </RECORD> <RECORD> <OPCODE>OP_CLOSE</OPCODE> <DATA> <TXID>134</TXID> <LENGTH>0</LENGTH> <INODEID>0</INODEID> <PATH>/hello7.txt</PATH> <REPLICATION>2</REPLICATION> <MTIME>1512943608761</MTIME> <ATIME>1512943607866</ATIME> <BLOCKSIZE>134217728</BLOCKSIZE> <CLIENT_NAME></CLIENT_NAME> <CLIENT_MACHINE></CLIENT_MACHINE> <OVERWRITE>false</OVERWRITE> <BLOCK> <BLOCK_ID>1073741839</BLOCK_ID> <NUM_BYTES>25</NUM_BYTES> <GENSTAMP>1016</GENSTAMP> </BLOCK> <PERMISSION_STATUS> <USERNAME>atguigu</USERNAME> <GROUPNAME>supergroup</GROUPNAME> <MODE>420</MODE> </PERMISSION_STATUS> </DATA> </RECORD> </EDITS >思考:NameNode如何確定下次開機啟動的時候合併哪些Edits?
-
CheckPoint時間設置
-
預設設置為SecondaryNameNode每隔一小時執行一次.
[hdfs-default.xml]
<property> <name>dfs.namenode.checkpoint.period</name> <value>3600</value> </property> -
或者一分鐘檢查一次操作次數,當操作次數達到1百萬時,SecondaryNameNode執行一次。
<property> <name>dfs.namenode.checkpoint.txns</name> <value>1000000</value> <description>操作動作次數</description> </property> <property> <name>dfs.namenode.checkpoint.check.period</name> <value>60</value> <description>1分鐘檢查一次操作次數</description> </property>
NameNode故障處理
NameNode故障後,可以採用如下兩種方法恢複數據。
-
方法一:將SecondaryNameNode中數據拷貝到NameNode存儲數據的目錄;
-
kill -9 NameNode進程
-
刪除NameNode存儲的數據(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
[atguigu@hadoop101 hadoop-2.7.2]$ rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/* -
拷貝SecondaryNameNode中數據到原NameNode存儲數據目錄
[atguigu@hadoop101 dfs]$ scp -r atguigu@hadoop103:/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary/* ./name/ -
重新啟動NameNode
-
-
方法二:使用-importCheckpoint選項啟動NameNode守護進程,從而將SecondaryNameNode中數據拷貝到NameNode目錄中。
-
修改hdfs-site.xml中的
<property> <name>dfs.namenode.checkpoint.period</name> <value>120</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp/dfs/name</value> </property> -
kill -9 NameNode進程
-
刪除NameNode存儲的數據(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
[atguigu@hadoop102 hadoop-2.7.2]$ rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/* -
如果SecondaryNameNode不和NameNode在一個主機節點上,需要將SecondaryNameNode存儲數據的目錄拷貝到NameNode存儲數據的平級目錄,並刪除in_use.lock文件
[atguigu@hadoop101 dfs]$ scp -r atguigu@hadoop103:/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary ./ [atguigu@hadoop101 namesecondary]$ rm -rf in_use.lock [atguigu@hadoop101 dfs]$ pwd /opt/module/hadoop-2.7.2/data/tmp/dfs [atguigu@hadoop101 dfs]$ ls data name namesecondary -
導入檢查點數據(等待一會ctrl+c結束掉)
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs namenode -importCheckpoint -
啟動NameNode
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
-
集群安全模式
- 概述

- 當NN中所保存的所有塊的最小副本數(預設為1) / 塊的總數 > 99.9%時,NN會在30秒之後自動離開安全模式!
-
基本語法
集群處於安全模式,不能執行重要操作(寫操作)。集群啟動完成後,自動退出安全模式。
- bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式狀態)
- bin/hdfs dfsadmin -safemode enter (功能描述:進入安全模式狀態)
- bin/hdfs dfsadmin -safemode leave (功能描述:離開安全模式狀態)
- bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式狀態)
-
案例
模擬等待安全模式
-
查看當前模式
[atguigu@hadoop101 hadoop-2.7.2]$ hdfs dfsadmin -safemode get Safe mode is OFF -
先進入安全模式
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfsadmin -safemode enter -
創建並執行下麵的腳本
[atguigu@hadoop101 hadoop-2.7.2]$ touch safemode.sh [atguigu@hadoop101 hadoop-2.7.2]$ vim safemode.sh #!/bin/bash hdfs dfsadmin -safemode wait hdfs dfs -put /opt/module/hadoop-2.7.2/README.txt / [atguigu@hadoop101 hadoop-2.7.2]$ chmod 777 safemode.sh [atguigu@hadoop101 hadoop-2.7.2]$ ./safemode.sh -
再打開一個視窗,執行
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfsadmin -safemode leave -
觀察
-
再觀察上一個視窗
Safe mode is OFF
-
HDFS集群上已經有上傳的數據了
-
即等待模式輸入的命令(寫操作)會在安全模式關閉後執行.
-
NameNode多目錄配置
-
NameNode的本地目錄可以配置成多個,且每個目錄存放內容相同,增加了可靠性
-
具體配置如下
-
在hdfs-site.xml文件中增加如下內容
<property> <name>dfs.namenode.name.dir</name> <value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2</value> </property> -
停止集群,刪除data和logs中所有數據。
[atguigu@hadoop102 hadoop-2.7.2]$ xcall rm -rf data/ logs/ -
格式化集群並啟動。
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs namenode –format [atguigu@hadoop101 hadoop-2.7.2]$ sbin/start-dfs.sh -
查看結果
[atguigu@hadoop102 dfs]$ ll 總用量 12 drwx------. 3 atguigu atguigu 4096 12月 11 08:03 data drwxrwxr-x. 3 atguigu atguigu 4096 12月 11 08:03 name1 drwxrwxr-x. 3 atguigu atguigu 4096 12月 11 08:03 name2
-
DataNode(重點)
DataNode工作機制
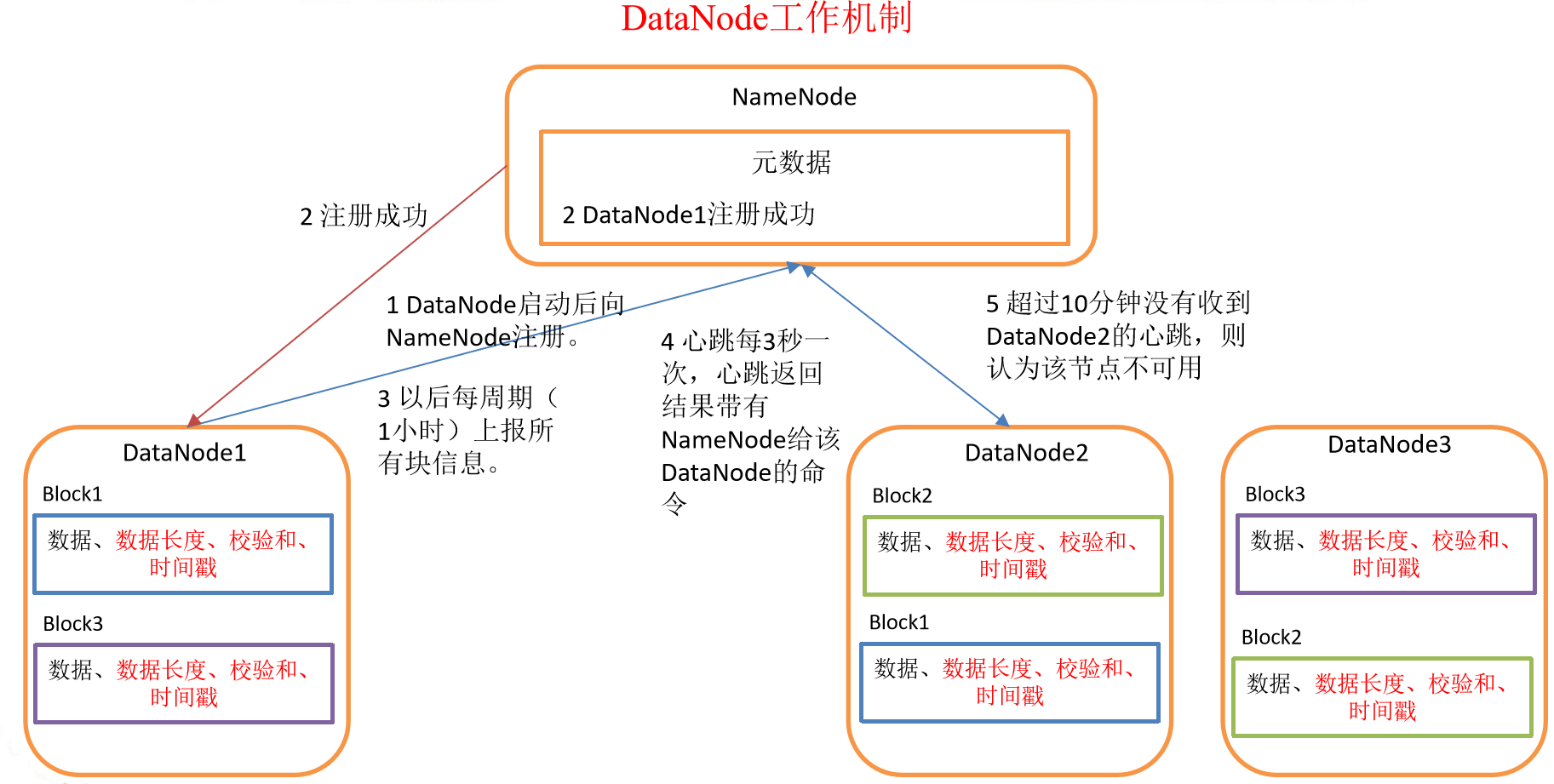
- 一個數據塊在DataNode上以文件形式存儲在磁碟上,包括兩個文件,一個是數據本身,一個是元數據包括數據塊的長度,塊數據的校驗和,以及時間戳。
- DataNode啟動後向NameNode註冊,通過後,周期性(1小時)的向NameNode上報所有的塊信息。
- 心跳是每3秒一次,心跳返回結果帶有NameNode給該DataNode的命令如複製塊數據到另一臺機器,或刪除某個數據塊。如果超過10分鐘沒有收到某個DataNode的心跳,則認為該節點不可用。
- 集群運行中可以安全加入和退出一些機器。
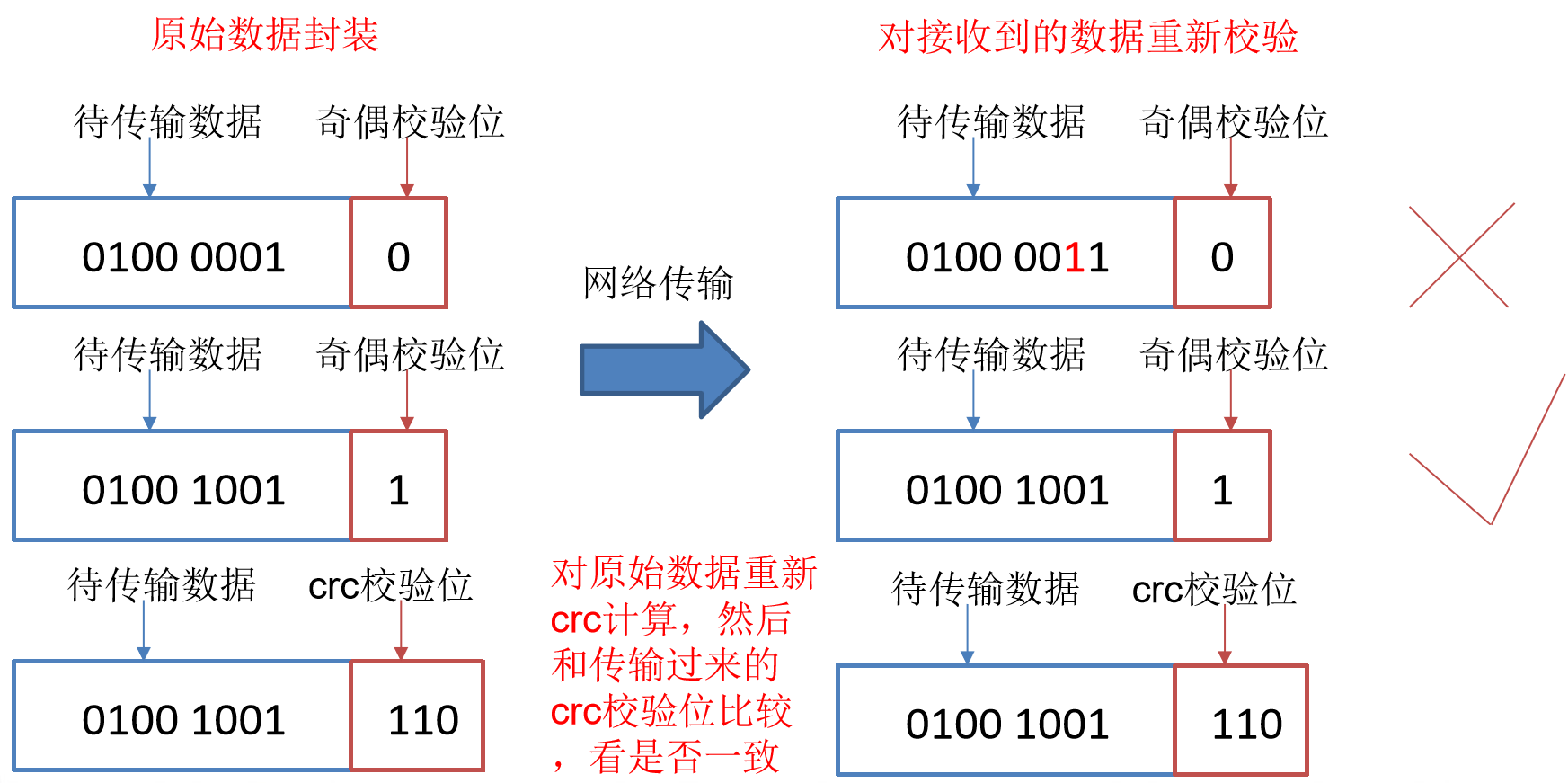
數據完整性
-
當DataNode讀取Block的時候,它會計算CheckSum。
-
如果計算後的CheckSum,與Block創建時值不一樣,說明Block已經損壞。
-
Client讀取其他DataNode上的Block。
-
DataNode在其文件創建後周期驗證CheckSum,如圖所示。
掉線時限參數設置

需要註意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的單位為毫秒,dfs.heartbeat.interval的單位為秒。
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name> dfs.heartbeat.interval </name>
<value>3</value>
</property>
服役新數據節點
隨著公司業務的增長,數據量越來越大,原有的數據節點的容量已經不能滿足存儲數據的需求,需要在原有集群基礎上動態添加新的數據節點。
-
環境準備
-
在hadoop103主機上再克隆一臺hadoop104主機
-
修改IP地址和主機名稱
-
刪除原來HDFS文件系統留存的文件(/opt/module/hadoop-2.7.2/data 和log)
-
source 一下配置文件
[atguigu@hadoop104 hadoop-2.7.2]$ source /etc/profile
-
-
服役新節點具體步驟
-
直接啟動DataNode,即可關聯到集群
[atguigu@hadoop104 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode [atguigu@hadoop104 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager -
在hadoop104上上傳文件
[atguigu@hadoop104 hadoop-2.7.2]$ hadoop fs -put /opt/module/hadoop-2.7.2/LICENSE.txt / -
如果數據不均衡,可以用命令實現集群的再平衡
[atguigu@hadoop101 sbin]$ ./start-balancer.sh starting balancer, logging to /opt/module/hadoop-2.7.2/logs/hadoop-atguigu-balancer-hadoop101.out Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
-
退役舊數據節點
添加白名單
添加到白名單的主機,都允許訪問NameNode,不在白名單的主機,都會被退出。
配置白名單的具體步驟如下:
-
在NameNode的/opt/module/hadoop-2.7.2/etc/hadoop目錄下創建dfs.hosts文件(文件名稱隨意,路徑隨意)
[atguigu@hadoop101 hadoop]$ pwd /opt/module/hadoop-2.7.2/etc/hadoop [atguigu@hadoop101 hadoop]$ touch dfs.hosts [atguigu@hadoop101 hadoop]$ vi dfs.hosts添加如下主機名稱(不添加hadoop104)
hadoop101
hadoop102
hadoop103
-
在NameNode的hdfs-site.xml配置文件中增加dfs.hosts屬性
<property> <name>dfs.hosts</name> <value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts</value> </property> -
配置文件分發
[atguigu@hadoop101 hadoop]$ xsync hdfs-site.xml -
刷新NameNode
atguigu@hadoop101 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes -
更新ResourceManager節點
[atguigu@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes -
如果數據不均衡,可以用命令實現集群的再平衡
[atguigu@hadoop101 sbin]$ ./start-balancer.sh starting balancer, logging to /opt/module/hadoop-2.7.2/logs/hadoop-atguigu-balancer-hadoop101.out Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
黑名單退役
在黑名單上面的主機都會被強制退出。
-
在NameNode的/opt/module/hadoop-2.7.2/etc/hadoop目錄下創建dfs.hosts.exclude文件(名稱路徑隨意)
[atguigu@hadoop101 hadoop]$ pwd /opt/module/hadoop-2.7.2/etc/hadoop [atguigu@hadoop101 hadoop]$ touch dfs.hosts.exclude [atguigu@hadoop101 hadoop]$ vi dfs.hosts.exclude添加如下主機名稱(要退役的節點)
hadoop104 -
在NameNode的hdfs-site.xml配置文件中增加dfs.hosts.exclude屬性
<property> <name>dfs.hosts.exclude</name> <value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts.exclude</value> </property> -
刷新NameNode、刷新ResourceManager
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes Refresh nodes successful [atguigu@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes 17/06/24 14:55:56 INFO client.RMProxy: Connecting to ResourceManager at hadoop102/192.168.1.102:8033 -
檢查Web瀏覽器,退役節點的狀態為decommission in progress(退役中),說明數據節點正在複製塊到其他節點
-
等待退役節點狀態為decommissioned(所有塊已經複製完成),停止該節點及節點資源管理器。註意:如果副本數是3,服役的節點小於等於3,是不能退役成功的,需要修改副本數後才能退役
stopping datanode
[atguigu@hadoop104 hadoop-2.7.2]$ sbin/hadoop-daemon.sh stop datanodestopping nodemanager
[atguigu@hadoop104 hadoop-2.7.2]$ sbin/yarn-daemon.sh stop nodemanager -
如果數據不均衡,可以用命令實現集群的再平衡
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/start-balancer.sh starting balancer, logging to /opt/module/hadoop-2.7.2/logs/hadoop-atguigu-balancer-hadoop101.out Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved註意:不允許白名單和黑名單中同時出現同一個主機名稱。
Datanode多目錄配置
-
DataNode也可以配置成多個目錄,每個目錄存儲的數據不一樣。即:數據不是副本
-
具體配置如下
hdfs-site.xml
<property> <name>dfs.datanode.data.dir</name> <value>file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2</value> </property>
HDFS 2.X新特性
集群間數據拷貝
-
scp實現兩個遠程主機之間的文件複製
scp -r hello.txt root@hadoop102:/user/atguigu/hello.txt// 推 pushscp -r root@hadoop102:/user/atguigu/hello.txt hello.txt// 拉 pullscp -r root@hadoop102:/user/atguigu/hello.txt root@hadoop103:/user/atguigu//是通過本地主機中轉實現兩個遠程主機的文件複製;如果在兩個遠程主機之間ssh沒有配置的情況下可以使用該方式。 -
採用distcp命令實現兩個Hadoop集群之間的遞歸數據複製
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hadoop distcp hdfs://haoop101:9000/user/atguigu/hello.txt hdfs://hadoop102:9000/user/atguigu/hello.txt
Hadoop存檔

案例實操
-
需要啟動YARN進程
[atguigu@hadoop102 hadoop-2.7.2]$ start-yarn.sh -
歸檔文件
把/user/atguigu/input目錄裡面的所有文件歸檔成一個叫input.har的歸檔文件,並把歸檔後文件存儲到/user/atguigu/output路徑下。
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hadoop archive -archiveName input.har –p /user/atguigu/input /user/atguigu/output -
查看歸檔
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -lsr /user/atguigu/output/input.har [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -lsr har:///user/atguigu/output/input.har -
解歸檔文件
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -cp har:/// user/atguigu/output/input.har/* /user/atguigu


