
1、Hive概念: hive是數據倉庫,由解釋器、優化器和編譯器組成;運行時,元數據存儲在關係型資料庫中。 2、Hive的架構: (1)用戶介面主要有三個:CLi、Client和WUI。其中最常用的是CLi,CLi啟動時候,會啟動一個Hive副本。Client是hive的客戶端,用戶連接至Hive ...
1、Hive概念:
hive是數據倉庫,由解釋器、優化器和編譯器組成;運行時,元數據存儲在關係型資料庫中。
2、Hive的架構:
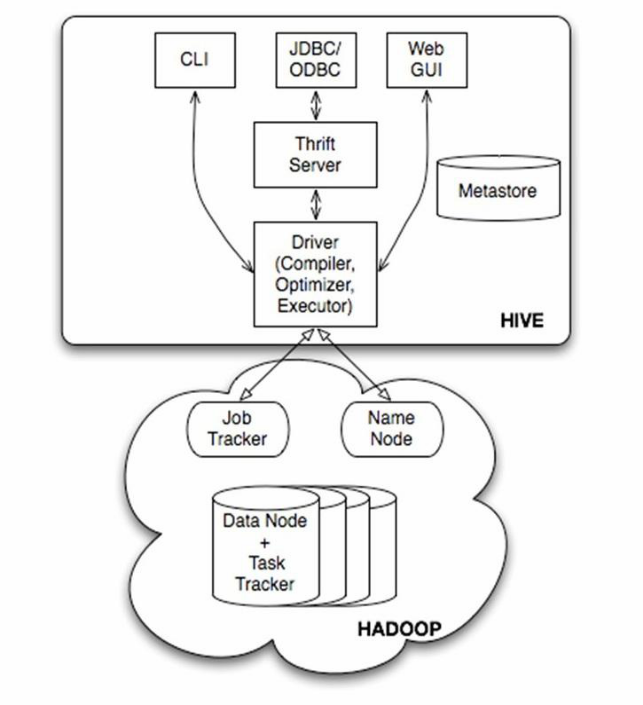
(1)用戶介面主要有三個:CLi、Client和WUI。其中最常用的是CLi,CLi啟動時候,會啟動一個Hive副本。Client是hive的客戶端,用戶連接至Hive Server。在啟動Client模式的時候,需要指出Hive Server所在的節點,並且在該節點啟動Hive Server;WEBUI是通過瀏覽器訪問hive;
(2)Hive元數據存儲在資料庫中,如MySQL、Derby。Hive中的元數據包括表的名字,表的列和分區及其屬性,表的屬性(是否為外部表等),表的數據所在的目錄等;
(3)解釋器、編譯器、優化器完成HQL查詢語句從詞法解析、語法分析、編譯、優化以及查詢計劃的產生。生成的查詢計劃存儲在HDFS中,併在隨後有MapReduce調用執行。
(4)Hive數據存儲在HDFS中,大部分的查詢、計算由Mapreduce完成(包含 * 的查詢,比如select * from table不會產生mapreduce任務)
3、Hive的三種模式
(1)local模式,一般用於Unit Test
(2)單用戶模式,通過網路連接到一個資料庫中,是最經常使用的模式
(3)多用戶模式,用於非java客戶端訪問元資料庫,在伺服器端啟動MetaStoreServer,客戶端利用Thrift協議通過MetaStoreServer訪問元資料庫
4、Hive建表
建表語句見官網:https://cwiki.apache.org/confluence/display/Hive/LanguageManual
創建內部表:
create table psn( id int, name string, likes ARRAY <string>, address MAP <string,string> ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' COLLECTION ITEMS TERMINATED BY '-' MAP KEYS TERMINATED BY ':';
註:插入數據不建議用insert語句,因為它會轉成MapReduce,執行時間較長
LOAD DATA [LOCAL] INPATH '/data_path' INTO TABLE psn
創建外部表
create EXTERNAL table psn2( id int, name string, likes ARRAY <string>, address MAP <string,string> ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' COLLECTION ITEMS TERMINATED BY '-' MAP KEYS TERMINATED BY ':' LOCATION '/user/psn2';
EXTERNAL 表示創建外部表
LOCATION 表示數據存放在hdfs上的路徑
刪除表
drop table psn; #內表 drop table psn2; #外表
註:外部表不會刪除數據
創建分區表
create table psn3( id int, name string, likes ARRAY <string>, address MAP <string,string> ) PARTITIONED BY(sex string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' COLLECTION ITEMS TERMINATED BY '-' MAP KEYS TERMINATED BY ':';
註:分區表的欄位不能是表中的欄位,分區欄位不存值
分區表插入數據
LOAD DATA LOCAL INPATH '/root/data_path' INTO TABLE psn3 partition (sex='boy');
導入數據第二種方式
from psn insert into table psn2 select id,name,likes,address;
動態分區
靜態分區:固定的,通過路徑(hdfs來標識)
動態分區:不固定的,可變的(對於一個文件中分區欄位有不同的值,導入表的同時分區)
動態分區參數配置 set hive.exec.dynamic.partition=true; #是否開啟動態分區 預設false set hive.exec.dynamic.partition.mode=nostrict; #設置非嚴格模式 預設strict(至少有一個是靜態分區) set hive.exec.max.dynamic.partitions.pernode; #每個執行的mr節點上,允許創建的動態分區的最大數量(100) set hive.exec.max.dynamic.partitions; #所有執行的mr節點上,允許創建的所有動態分區的最大數量(1000) set hive.exec.max.created.files; #所有的mr job允許創建的文件的最大數量(100000)
註:動態分區導入數據不使用load data...
建議使用 from tablle2 insert overwrite table table1 partition(age, sex) select id, name, age, sex, likes, address distribute by age, sex;
5、創建自定義函數
官網網址:https://cwiki.apache.org/confluence/display/Hive/HivePlugins
package com.example.hive.udf; import org.apache.hadoop.hive.ql.exec.UDF; import org.apache.hadoop.io.Text; public final class Lower extends UDF { public Text evaluate(final Text s) { if (s == null) { return null; } return new Text(s.toString().toLowerCase()); } }重點:寫完之後打成jar上傳至hiverserver上,而不是客戶端,進入hive客戶端添加jar包 add jar地址 path:hiverserver主機的地址,而不是hdfs地址; 實踐證明上傳至客戶端有效,只要創建成功,只要不退出本次會話,即使刪除本地的jar,創建的臨時函數也是有效的
hive> add jar /root/example.jar #後面為jar包上傳的路徑 hive> create temporary function example as 'com.example.hive.udf.Lower'; #創建臨時函數 example為hive sql執行的函數名;字元串為類路徑 hive> select id,name,example(name),likes from psn1; #運行 hive> drop temporary function example; #刪除臨時函數
6、分桶
-----分桶表是對列值取hash的方式,將不同數據放到不同文件中存儲
-----對於hive表中每一個表、分區都可以進一步進行分桶
-----由列的hash值除以桶的個數來決定每條數據劃分在哪個桶中
使用場景:數據抽樣(simaple)、mapjoin
首先要開啟支持分桶
set hive.enforce.bucketing=true; #預設為flase;設置之後,MR運行時會根據桶的個數自動分配reduce task個數
註:一次作業產生的桶(文件數量)和reduce task個數一致
創建分桶表
CREATE TABLE psnbucket( id INT, name STRING, sex string) CLUSTERED BY (id) INTO 4 BUCKETS ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';

查看創建的分桶表
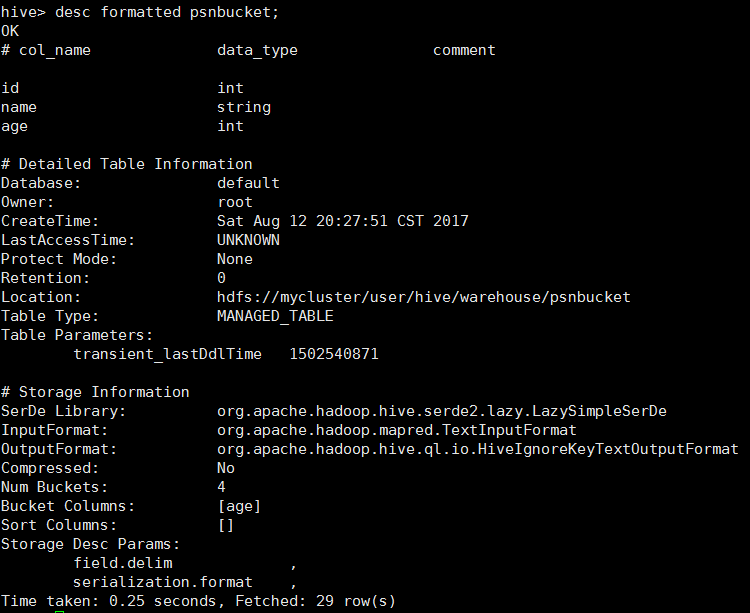
載入數據
1.insert [into/overwrite] table psnbucket select id, name, sex from psn6; 2.from psn6 insert into psnbucket select id,name,sex;
桶的數量對應執行了4個reduce任務

桶表抽樣查詢
TABLESAMPLE(BUCKET x OUT OF y)
x:表示從哪個bucket開始抽取數據
y:必須為該表總bucket數的倍數或因數
example:
select id,name,age from bucket_table tablesample(bucket 1 out of 4 on id);
計算抽取哪些數據:
當表總bucket數為32(total)時 TABLESAMPLE(BUCKET 2 OUT OF 16),抽取哪些數據? 共抽取2(32/16)個bucket的數據,抽取第2、第18(16+2)個bucket的數據if(total /y >0){ 抽取第 x、y+ ( total /y )桶的數據 }else if(total /y < 0){ 抽取第x桶的( total /y )的數據 }else{ x、y數量有問題 }
7、Hive索引
hive創建索引後如需使用的話必須先重建索引,索引才能生效
8、Hive優化
核心思想:把Hive SQL當做MapReduce程式去優化
一下SQL不會轉成MapReduce來執行
- select僅查詢本表欄位
- where僅對本表欄位做條件過濾
(1)Explain顯示執行計劃
EXPLAIN [EXTENDED] sql語句
(2)Hive的運行方式:本地模式和集群模式
開啟本地模式:
set hive.exec.mode.local.auto=true;
註意:hive.exec.mode.local.auto.inputbytes.max預設值為128M ,表示載入文件的最大值,若大於該配置仍會以集群方式來運行!
(3)並行計算
set hive.exec.parallel=true;
註意:hive.exec.parallel.thread.number (一次SQL計算中允許並行執行的job個數的最大值)
(4)嚴格模式
set hive.mapred.mode=strict; #(預設為:nonstrict非嚴格模式)查詢限制: 1、對於分區表,必須添加where對於分區欄位的條件過濾; 2、order by語句必須包含limit輸出限制; 3、限制執行笛卡爾積的查詢。 (5)Hive排序 Order By - 對於查詢結果做全排序,只允許有一個reduce處理 (當數據量較大時,應慎用。嚴格模式下,必須結合limit來使用) Sort By - 對於單個reduce的數據進行排序 Distribute By - 分區排序,經常和Sort By結合使用 Cluster By - 相當於 Sort By + Distribute By (Cluster By不能通過asc、desc的方式指定排序規則; 可通過 distribute by column sort by column asc|desc 的方式) (6)Hive Join Join計算時,將小表(驅動表)放在join的左邊,因為先載入左邊(讓它優先載入小表) Map Join:在Map端完成Join 兩種實現方式: 1、SQL方式,在SQL語句中添加MapJoin標記(mapjoin hint) 語法: SELECT /*+ MAPJOIN(smallTable) */ smallTable.key, bigTable.value FROM smallTable JOIN bigTable ON smallTable.key = bigTable.key; 2、開啟自動的MapJoin
set hive.auto.convert.join = true; #該參數為true時,Hive自動對左邊的表統計量,如果是小表就加入記憶體,即對小表使用Map join
相關配置參數:
hive.mapjoin.smalltable.filesize; #大表小表判斷的閾值,如果表的大小小於該值則會被載入到記憶體中運行 hive.ignore.mapjoin.hint; #預設值:true;是否忽略mapjoin hint 即mapjoin標記 hive.auto.convert.join.noconditionaltask; #預設值:true;將普通的join轉化為普通的mapjoin時,是否將多個mapjoin轉化為一個mapjoin hive.auto.convert.join.noconditionaltask.size; #將多個mapjoin轉化為一個mapjoin時,其表的最大值
(7)Map-Side聚合
set hive.map.aggr=true;
hive.groupby.mapaggr.checkinterval #map端group by執行聚合時處理的多少行數據(預設:100000) hive.map.aggr.hash.min.reduction #進行聚合的最小比例(預先對100000條數據做聚合,若聚合之後的數據量/100000的值大於該配置0.5,則不會聚合) hive.map.aggr.hash.percentmemory #map端聚合使用的記憶體的最大值 hive.map.aggr.hash.force.flush.memory.threshold #map端做聚合操作是hash表的最大可用內容,大於該值則會觸發flush hive.groupby.skewindata #是否對GroupBy產生的數據傾斜做優化,預設為false
(8)控制hive中的Map以及Reduce數量
Map數量相關的參數
mapred.max.split.size #一個split的最大值,即每個map處理文件的最大值 mapred.min.split.size.per.node #一個節點上split的最小值 mapred.min.split.size.per.rack #一個機架上split的最小值
Reduce數量相關的參數
mapred.reduce.tasks #強制指定reduce任務的數量 hive.exec.reducers.bytes.per.reducer #每個reduce任務處理的數據量 hive.exec.reducers.max #每個任務最大的reduce數
(9)Hive--JVM重用
適用場景: 1、小文件個數過多 2、task個數過多set mapred.job.reuse.jvm.num.tasks=n # 來設置(n為task插槽個數)缺點:設置開啟之後,task插槽會一直占用資源,不論是否有task運行,直到所有的task即整個job全部執行完成時,才會釋放所有的task插槽資源!

