
idea中使用scala運行spark出現: 查看build.sbt: 你需要確保 spark所使用的scala版本與你系統scala的版本一致 你也可以這樣: 那怎樣確認你的版本是否一致呢: 1 .首先查看你代碼使用的版本,這個就是從pom.xml中或者sbt配置文件中查看 確定你的使用版本 2. ...
idea中使用scala運行spark出現:
Exception in thread "main" java.lang.NoClassDefFoundError: scala/collection/GenTraversableOnce$class
查看build.sbt:

name := "ScalaSBT" version := "1.0" scalaVersion := "2.11.8" libraryDependencies += "org.apache.spark" % "spark-core_2.11" % "1.6.1"
你需要確保 spark所使用的scala版本與你系統scala的版本一致
你也可以這樣:
libraryDependencies += "org.apache.spark" %% "spark-core" % "1.6.1"
那怎樣確認你的版本是否一致呢:
1 .首先查看你代碼使用的版本,這個就是從pom.xml中或者sbt配置文件中查看
確定你的使用版本
2.查看你的spark的集群,spark使用的scala的版本
a. 運行spark-shell ,在啟動結束會顯示版本

b.進入spark的安裝目錄查看jars目錄下,scala中的類庫版本號
ls /usr/local/spark/jars | grep scala
顯示如下:
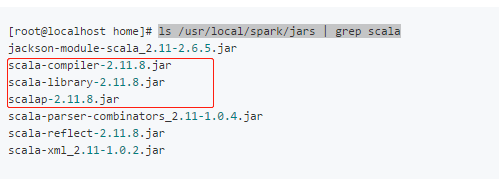
然後你就可以修改你使用的scala版本號了
問題解決


