
前言 最近在實習,在公司看到前輩的一些代碼,發現有很多值得我學習的地方,其中有一部分就是對集合使用Stream流式操作,覺得很優美且方便。所以學習一些Stream流,在這裡記錄一下。 Stream是什麼 Stream 是Java 8中出現的新特性,極大增強了集合對象的功能,專註於對集合對象進行方便、 ...
前言
最近在實習,在公司看到前輩的一些代碼,發現有很多值得我學習的地方,其中有一部分就是對集合使用Stream流式操作,覺得很優美且方便。所以學習一下Stream流,在這裡記錄一下。
Stream是什麼
Stream是Java 8中出現的新特性,極大增強了集合對象的功能,專註於對集合對象進行方便、高效的聚合操作。另外可以配合Lambda表達式,讓代碼更加容易理解。另外Stream提供串列和並行兩種操作方式,並行操作可以很方便的寫出高性能的併發程式。
Stream像是一個高級版本的Iterator,使用Iterator只能顯式地遍歷一個個元素對其執行某些操作;使用Stream,我們只需要指定對集合包含的元素執行什麼操作,例如“只獲取性別為男的用戶”、“獲取每個用戶姓名的姓氏”等,Stream會幫我們完成隱式的遍歷操作,並轉換數據。
與Iterator不同的是,Iterator只能串列操作,每次操作完一個元素再去下一個元素。Stream支持串列、並行操作,Stream的並行操作依賴Java 7的Fork/Join框架(JSR166y)來拆分任務和加速處理過程。
Stream就像是一條流水線,單向,不可回頭,只能遍歷一次,之後就不能再使用了。
使用一個Stream流,一般分為三個步驟:1. 獲取數據源-> 2. 中間操作(Intermediate)-> 3. 終端操作(Terminal)。
中間操作:一個流可以有0或多個中間操作,對數據進行轉換、過濾等操作,一個接著一個,這些操作是lazy的,中間操作是還沒有開始真正的遍歷。
終端操作:一個流只能有一個終端操作,使用終端操作之後就會返回結果,不能再使用這個流了。終端操作時,才真正開始遍歷。
在Stream中一個流的多次中間操作不是每一次都進行一次遍歷的,中間操作是lazy 的,多個中間操作是最終聚合到終端操作的時候進行的,只進行一次遍歷迴圈。可以理解為每個中間操作被當做一個判斷條件加入到終端操作迴圈中,完成每個元素的數據轉換。
下麵是一些Stream流操作方法的分類:
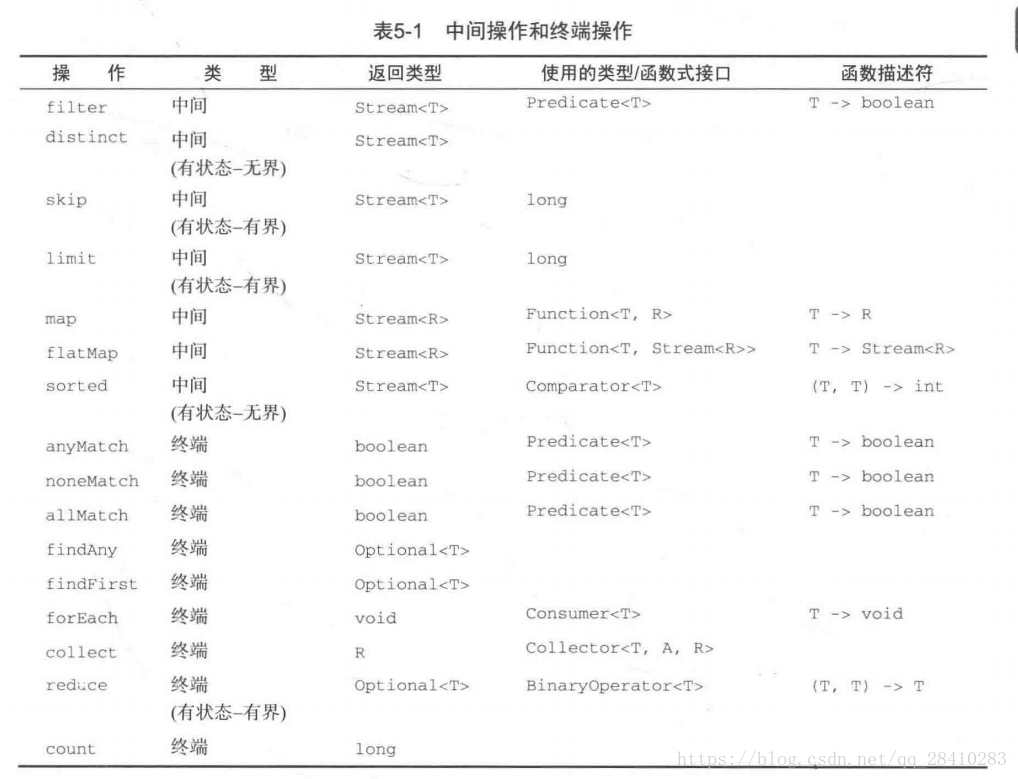
Stream流的創建方式
數組
- Arrays.stream(T array);
- stream.of(array)
- Arrays.stream(T array);
- Collection
- Collection.stream()
- Collection.parallelStream()
- BufferedReader
- java.io.BufferedReader.lines()
靜態工廠
- java.util.stream.IntStream.range()
- java.nio.file.Files.walk()
- 自己構建
- java.util.Spliterator
- 其他
- Random.ints()
- BitSet.stream()
- Pattern.splitAsStream(java.lang.CharSequence)
- JarFile.stream()
創建示例
//數組
String[] array = new String[]{"1","2","3"};
Arrays.stream(array);
Stream.of(array);
Stream.of(1, 2, 3);
//集合
List<String> list = Arrays.asList(array);
list.stream();
list.parallelStream();
//數值,目前只支持IntStream、LongStream、DoubleStream三種
IntStream.of(new int[]{1,2,3}).forEach(System.out::println);
IntStream.range(1,3).forEach(System.out::println);
IntStream.rangeClosed(1, 3).forEach(System.out::println);流轉換為其它數據結構
Stream stream = Stream.of("1","2","3");
//Array
String[] array2=(String[]) stream.toArray(String[]::new);
//Collection
List<String> list1=(List)stream.collect(Collectors.toList());
List<String> list2=(List)stream.collect(Collectors.toCollection(ArrayList::new));
Set set=(Set)stream.collect(Collectors.toSet());
Stack stack=(Stack)stream.collect(Collectors.toCollection(Stack::new));
//String
String str = stream.collect(Collectors.joining()).toString();經典用法
1. 將一個List中元素的某一屬性取出來作為一個list,並做過濾
List<Long> names= users.stream().filter(Objects::nonNull).map(User::getId).collect(Collectors.toList());
//或者
List<Long> names1=
users.stream().filter(Objects::nonNull).map(u->u.getId()).collect(Collectors.toList());
//遍歷list
names.forEach(System.out::println);2. 將List轉換成Map
//key:id value:name
Map<Long, String> map = users.stream().collect(Collectors.toMap(p -> p.getId(), p -> p.getName()));
//或者,第三個參數表示如果key重覆保留k1,捨棄k2。
Map<Long, String> map2 = users.stream().collect(Collectors.toMap(User::getId,User::getName,(k1,k2)->k1));
//key:id value:user
Map<Long, User> map3 = users.stream().collect(Collectors.toMap(p -> p.getId(), p->p));
//遍歷map,包括k,v。map.values.forEach()不能遍歷Key
map3.forEach((k,v)-> System.out.println("k:v="+k+":"+v));3. 使用sorted對List排序
//降序,預設是升序
List<User> list=
users.stream().sorted(Comparator.comparing(User::getId).reversed()).collect(Collectors.toList());
//遍歷list
list.forEach(System.out::println);Comparator.comparing(User::getId)表示以id作為排序的數據。
4. 對List分組存入一個Map
//按照性別分組
Map<String,List<User>> map=users.stream().collect(Collectors.groupingBy(User::getSex));
map.forEach((k,v)-> System.out.println("k:v="+k+":"+v));5. 使用map轉換大寫
List<String> list1 = new ArrayList<>();
list1.add("a");
list1.add("b");
list1.add("c");
List<String> list2 = list1.stream().map(String::toUpperCase).collect(Collectors.toList());6. flatMap和map
//map
List<String> str = Arrays.asList("a,b,c", "d,e", "f");
List<String[]> list1 = str.stream().map(s -> s.split(",")).collect(Collectors.toList());
list1.forEach(p-> System.out.print(Arrays.toString(p)+","));//[a, b, c],[d, e],[f]
//flatMap
List<String> list2 = str.stream().map(s -> s.split(",")).flatMap(Arrays::stream).sorted(Comparator.comparing(p->p.toString()).reversed()).collect(Collectors.toList());
System.out.println(list2);//[f, e, d, c, b, a]flatMap與map的區別在於 flatMap是將一個流中的每個元素都轉成一個個流,flatMap之後得到的是每個流中元素的總的集合,即對每個流進行了二次遍歷取出其中的元素,融合到總的集合中。
7. reduce
//求和 sum=11,第一個參數1為初始值(種子),第二個參數為運算規則(BinaryOperator)。1+1+2+3+4=11
Integer sum = Stream.of(1, 2, 3, 4).reduce(1, Integer::sum);
//concat="ABCD";
String concat = Stream.of("A", "B", "C").reduce("", String::concat);
//求和,reduce方法無初始值,返回類型為Optional,需要調用get()方法取值。
Integer sum2 = Stream.of(1, 2, 3, 4).reduce(Integer::sum).get();
//取最大值,max=2.0。
Double max = Stream.of(1.0, 2.0, -1.0, 1.5).reduce(Double.MIN_VALUE, Double::max);optional也是Java 8中的新特性,可以存儲null或者實例,有機會再深入講吧。
8. limit和skip
List<Long> ids=users.stream().map(User::getId).limit(5).skip(2).collect(Collectors.toList());
ids.forEach(System.out::println);//0-9 輸出了 2 3 4limit(5)限制只要前五條,skip(2)跳過前兩條。特別註意如果limit和skip配合sorted使用,需先進行limit和skip。
生命不息,學習不止。還需繼續努力。20191210


