
Spark 是一個快速、通用、可擴展的大數據計算引擎,具有高性能、易用、容錯、可以與 Hadoop 生態無縫集成、社區活躍度高等優點。在實際使用中,具有廣泛的應用場景: · 數據清洗和預處理:在大數據分析場景下,數據通常需要進行清洗和預處理操作以確保數據質量和一致性,Spark 提供了豐富的 API ...
Spark 是一個快速、通用、可擴展的大數據計算引擎,具有高性能、易用、容錯、可以與 Hadoop 生態無縫集成、社區活躍度高等優點。在實際使用中,具有廣泛的應用場景:
· 數據清洗和預處理:在大數據分析場景下,數據通常需要進行清洗和預處理操作以確保數據質量和一致性,Spark 提供了豐富的 API,可以對數據進行清洗、過濾、轉換等操作
· 批處理分析:Spark 適用於各種應用場景下的批處理任務,包括統計分析、數據挖掘、特征提取等,用戶可以利用 Spark 強大的 API 和內置庫進行複雜的數據處理和分析,從而挖掘數據中的內在價值
· 互動式查詢:Spark 提供了支持 SQL 查詢的 Spark SQL 模塊,用戶可以使用標準的 SQL 語句進行互動式查詢和大規模數據分析
Spark 在袋鼠雲的使用
在袋鼠雲數棧離線開發平臺,我們提供了三種使用 Spark 的方式:
● 創建 Spark SQL 任務
用戶可以直接通過編寫 SQL 的方式實現自己的業務邏輯。這種方式是目前數棧離線平臺使用 Spark 最廣泛的方式,也是最為推薦的一種方式。
● 創建 Spark Jar 任務
用戶需要在 IDEA 上使用 Scala 或者 Java 語言實現業務邏輯,然後對該項目進行編譯打包,並將得到的 Jar 包上傳到離線平臺,隨後在創建 Spark Jar 任務的時候引用這個 Jar 包,最後將任務提交到調度運行即可。
對於使用 SQL 難以實現或表達的需求,或者用戶有其他更深層次的需求,Spark Jar 任務無疑給用戶提供了一種更為靈活的使用 Spark 的方式。
● 創建 PySpark 任務
用戶可以直接編寫對應的 Python 代碼。在我們的客戶群體中,有相當一部分客戶,他們除了 SQL 之外,Python 可能是他們的主力語言。特別是針對有一定數據分析基礎、演算法基礎的用戶,他們往往會對處理好的數據進行更深層的分析,此時 PySpark 任務自然是他們的不二之選。
Spark 在袋鼠雲數棧離線開發平臺發揮著重要的作用,因此,我們內部對 Spark 做了也不少的優化,使客戶在使用 Spark 提交任務時更加方便。我們還基於 Spark 做了一些工具來增強整個數棧離線開發平臺的功能。
除此之外,在數據湖場景下,Spark 也發揮著相當重要的作用。在袋鼠雲的湖倉一體模塊中,已經支持了 Iceberg 和 Hudi 兩大數據湖,用戶可以使用 Spark 對湖表進行讀寫,湖表的治理底層也是通過使用 Spark 調用不同的存儲過程實現。
下文就將從引擎側和 Spark 本身兩個方面來闡述袋鼠雲內部所做的優化。
引擎端優化
袋鼠雲內部引擎端的功能主要是用於任務提交、任務狀態獲取、任務日誌獲取、停止任務、語法校驗等。每個功能點我們都做了不同程度的優化,下文通過兩個例子進行簡單介紹。
Spark on Yarn 提交速度提升
隨著引擎端 Spark 插件上新功能的不斷開發和完善,引擎端提交 Spark 任務所需的時間也在相應的增加,因此需要對提交 Spark 任務相關的代碼進行優化,以縮短 Spark 任務提交的時長,提升用戶體驗。
為此,我們做了以下工作,對於一些公用的配置文件,如 core-site.xml、yarn-site.xml、keytab 文件、spark-sql-application.jar 等,原來每次提交任務都需要預先從伺服器下載並提交這些配置文件。現在經過優化後,上述文件僅僅需要在客戶端 SparkYarnClient 初始化的時候下載一次,然後上傳到指定的 HDFS 路徑,後續提交 Spark 任務只需要通過參數的方式指定到對應的 HDFS 路徑即可。通過這種方式大大縮短了每次 Spark 任務的提交時間。
在新版本的數棧中,對於臨時查詢,我們還會根據自定義的規則判斷待執行 SQL 的複雜度,將複雜度不高的 SQL 發送到引擎端啟動的 SparkSQLEngine 運行,以加快運行速度。這個內部的 SparkSQLEngine 在以前僅僅用於語法校驗,現在也承擔了一部分 SQL 執行的功能,並且 SparkSQLEngine 還可以根據運行的整體情況,動態擴縮資源,實現資源的有效利用。
語法校驗
在較老的數棧版本,對於 SQL 進行語法校驗,引擎端會先把 SQL 發送到 Spark Thrift Server。這個 Spark Thrift Server 是以 local 模式部署,不僅僅需要用於語法校驗,其他平臺上所有元數據的獲取都是通過發送 SQL 到這個 Spark Thrift Server 執行來獲取。這種方式弊端較大,為此我們做了一些優化。在 Engine 端以 local 模式啟動了一個 Spark 任務,在進行語法校驗的時候不再將 SQL 發送到 Spark Thrift Server,而是內部維護了一個 SparkSession,直接對 SQL 進行語法校驗。
這種方式雖然可以不需要再跟外部的 Spark Thrift server 強關聯,但是會給調度組件帶來一定的壓力,在實現的過程中 Engine-Plugins 的整體複雜度也增大了不少。
為了優化以上問題,我們做了更進一步的優化,調度組件在啟動的時候,提交了一個 Spark 任務 SparkSQLEngine 到 Yarn 上。可以理解為是一個遠程的運行在 Yarn 上的 Spark Thrift Server,引擎端時刻監控這個 SparkSQLEngine 的健康狀態。這樣,每次執行語法校驗的時候,引擎端將 SQL 通過 JDBC 的形式發送給 SparkSQLEngine 進行語法校驗。
通過上述的優化,使得離線開發平臺與 Spark Thrift Server 解耦合,EasyManager 不需要額外部署 Spark Thrift Server,使部署更輕量化。調度側也不用維護一個 local 模式的 Spark 常駐進程。也為離線開發平臺上 Spark SQL 任務互動式查詢增強做鋪墊。
離線開發平臺與 EasyManager 部署的 Spark Thrift Server 解耦合後會有以下好處:
· 能夠真正意義上的實現 Spark 多集群多版本共存
· EasyManager 標準部署可以去除 Spark Thrift Server,為一線運維減負
· Spark SQL 語法校驗變得更輕量,不用緩存 SparkContext,減少 Engine 的資源占用
Spark 功能優化
隨著業務的發展深入,我們發現開源的 Spark 在一些場景並沒有對應的功能實現。因此我們在開源 Spark 的基礎上開發了更多新的插件,以支持數棧更多的功能應用。
任務診斷
首先,我們對 Spark 的 metric sink 做了增強。Spark 內部提供了各種 Sink,除了 ConsoleSink 之外,還有 CSVSink、JmxSink、MetricsServlet、GraphiteSink、Slf4jSink、StatsdSink 等。在 Spark3.0 之後還新增了 PrometheusServlet,但這些還不能滿足我們的需求。
在開發任務診斷功能的時候,我們需要通過把 Spark 內部的指標統一推送到 PushGateway,由 Prometheus Server 周期性的從 PushGateway 中拉取指標,最後通過調用 Prometheus 提供的查詢介面可以近實時地查詢到 Spark 內部的指標。

但是 Spark 並沒有實現將內部指標 sink 到 PushGateway。因此我們新增了 spark-prometheus-sink 插件,並且自定義了 PrometheusPushGatewaySink 用於將 Spark 內部的指標 push 到 PushGateway。
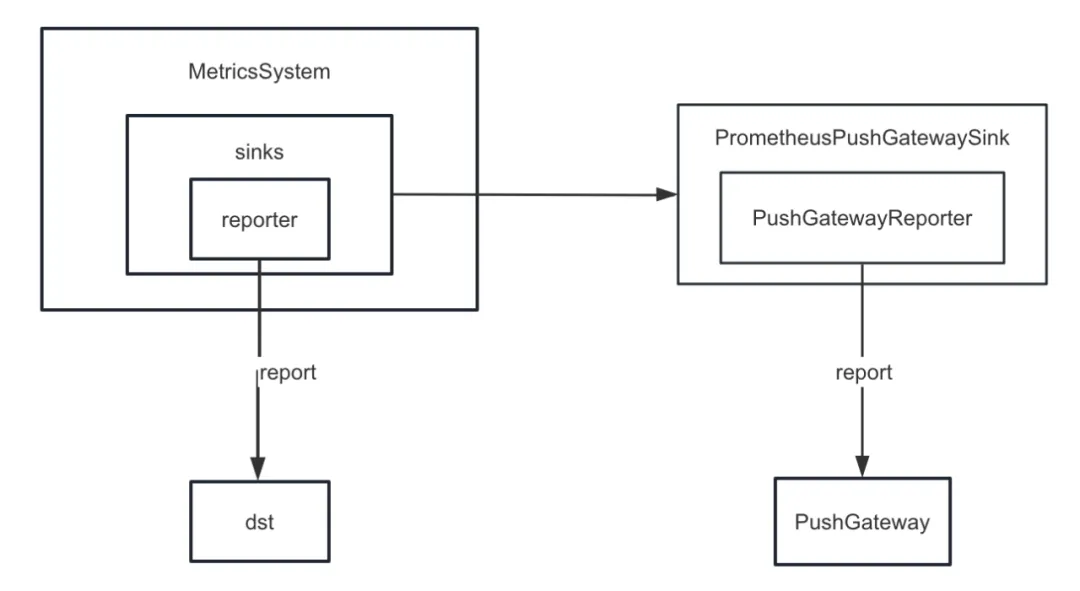
除此之外,我們還自定義了一個新的指標用來描述 Spark SQL 臨時查詢展示任務執行進度。具體步驟如下:
· 通過自定義 JobProgressSource 來新增用於描述離線任務進度的指標,將該指標註冊到 Spark 內部管理系統中的指標管理系統中
· 自定義 JobProgressListener,並將 JobProgressListener 註冊到 Spark 內部管理系統中的 ListenerBus。其中,JobProgressListener 的 onJobStart 方法的邏輯是計算當前 Job 下所有的 Task 數量;onTaskEnd 方法的邏輯是在每個 Task 完成後計算並更新當前離線任務進度;onJobEnd 方法的邏輯是在每個 Job 完成後計算並更新當前離線任務進度
對接商業版 Hadoop 集群
隨著袋鼠雲客戶越來越多,客戶的環境也是各不相同。有的客戶使用的是開源版本的 Hadoop 集群,也有相當一部分客戶使用的是 HDP、CDH、CDP、TDH 等。我們在對接這些客戶的集群的時候,開發側往往需要進行新的適配,運維側每次部署升級的時候也需要配置額外的參數或者有其他額外的操作。
以 HDP 為例,在對接 HDP 的時候,我們使用的 Spark 是 HDP 自帶的 Spark2.3,並且我們還需要在運維側新增一些參數,並將 HDP 自帶的 Spark 的所有 Jar包 移動到指定目錄。這些操作其實會給運維帶來一定的困惑和麻煩,不同類型的集群,運維需要維護不同的運維文檔,部署的過程也比較容易出錯。並且我們其實對 Spark 的源碼做了功能增強和 bug 的修複,如果使用的是 HDP 自帶的 Spark,那麼就享受不到我們內部維護的 Spark 帶來的所有好處。
為瞭解決上面這些問題,我們內部的 Spark 對現有市場上已有的、常見的發行商都做了適配。換句話來說,我們內部的 Spark 可以在所有不同的 Hadoop 集群上運行。這樣,無論對接哪一種類型的 Hadoop 集群,運維只需要部署同一個 Spark 即可,這大大減輕了運維部署的壓力。更重要的是,客戶可以直接使用我們內部的 Spark 穩定版本,享受到更多的新特性和更大的性能提升。
Spark3.2 新特性-AQE
較老的數棧版本中,預設的 Spark 版本是 2.1.3,後來我們將 Spark 的版本升級到 2.4.8,從數棧6.0開始,Spark3.2 也可以使用了。這裡著重介紹一下 AQE,這也是 Spark3.x 中最重要的新特性。
AQE 概述
Spark3.2 之前,AQE 預設是關閉的,需要通過將 spark.sql.adaptive.enabled 設置為 true,才能開啟 AQE。Spark3.2 之後,AQE 預設是開啟的,任務在運行過程中只要滿足 AQE 的觸發條件,即可享受 AQE 帶來的優化。
需要註意的是,AQE 的優化只會發生在 shuffle 階段,如果 SQL 在運行過程中並沒有涉及到 shuffle 操作,那麼即使 spark.sql.adaptive.enabled 的值為 true,AQE 也不會發揮作用。更準確來說,只有物理執行計劃包含 exchange 節點或者包含子查詢,AQE 才會生效。
AQE 在運行期間,會收集 shuffle map 階段所生成的中間文件的信息,並將這些信息進行統計,結合已有的規則動態的調整尚未執行的 Optimized Logical Plan 和 Spark Plan,從而對原來的 SQL 語句進行運行時優化。
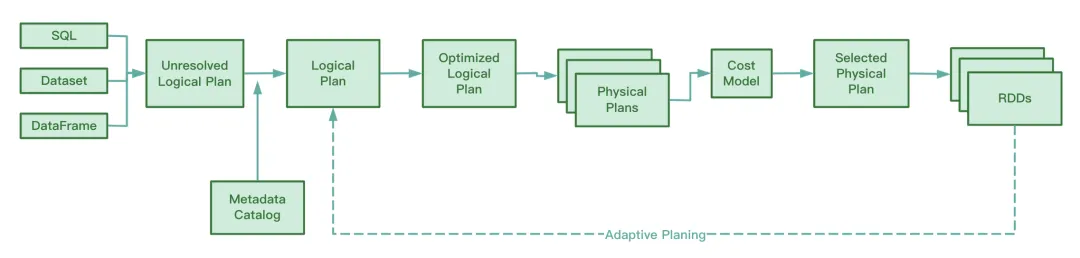
從 Spark 源碼來看,AQE 涉及到以下4個優化規則:
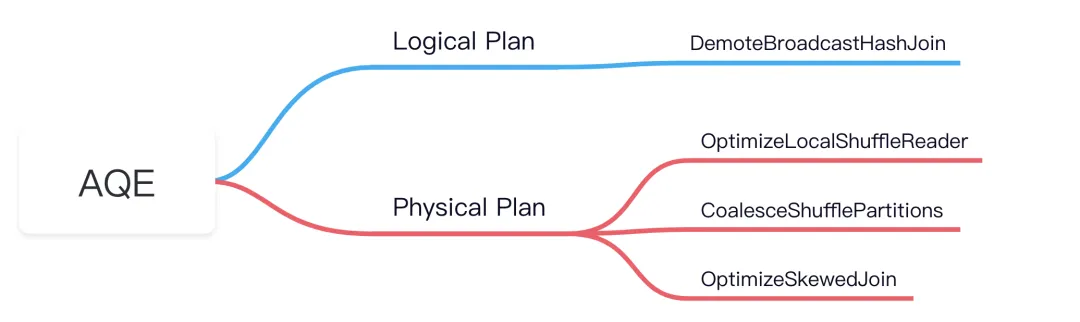
我們知道,RBO 是根據一系列的規則(rule)來對 SQL 進行優化,包括謂詞下推、列剪枝、常量替換等。這些靜態規則本身已經內置在 Spark 中,Spark 在執行 SQL 的過程中,這些 rule 會一一作用到 SQL 中。
AQE 的優勢
CBO 這個特性是 Spark2.2 之後才有的,相比於 RBO,CBO 會結合表的統計信息,並根據這些統計信息和代價模型(Cost Model)選擇出較為優化的執行計劃。
但是,CBO 僅僅支持註冊到 Hive Metastore 的表。對於存儲在分散式文件系統的 parquet、orc 等文件,CBO 是不支持的。並且,如果 Hive 表缺少元數據信息,CBO 收集統計信息的時候就會收集不到,這可能會導致 CBO 失效。
CBO 的另外一個劣勢在於 CBO 在優化之前需要先執行 ANALYZE TABLE COMPUTE STATISTICS 來收集統計信息。該語句在執行過程中如果碰到大表則會較為耗時,收集效率較低。
無論是 CBO 還是 RBO,它們都屬於靜態優化。在物理執行計劃提交後,如果任務在運行過程中,數據量、數據分佈情況發生變化,CBO 也不會對已有的物理執行計划進行優化。
與 CBO、RBO 不同的是,AQE 在運行過程中,會對 shuffle map 過程中所產生的中間文件進行分析,動態的調整並優化尚未開始執行的邏輯執行計劃和物理執行計劃,相對靜態優化的 CBO 和 RBO 而言,AQE 的處理能得到更加優化的物理執行計劃。
AQE 三大特性
● 自動分區合併
Shuffle 過程分為 Map 階段和 Reduce 兩個階段,Reduce 階段會將 Map 階段產生的中間臨時文件拉取到對應的 Executor 下,如果 Map 階段所處理的數據分佈非常不均勻,有很多 key 其實僅僅只有幾條數據,數據經過處理後可能會形成比較多的小文件。
為了避免上述情況,可以開啟 AQE 的自動分區合併功能,可以避免啟動過多的 reduce task 去拉取 Map 階段生成的小文件。
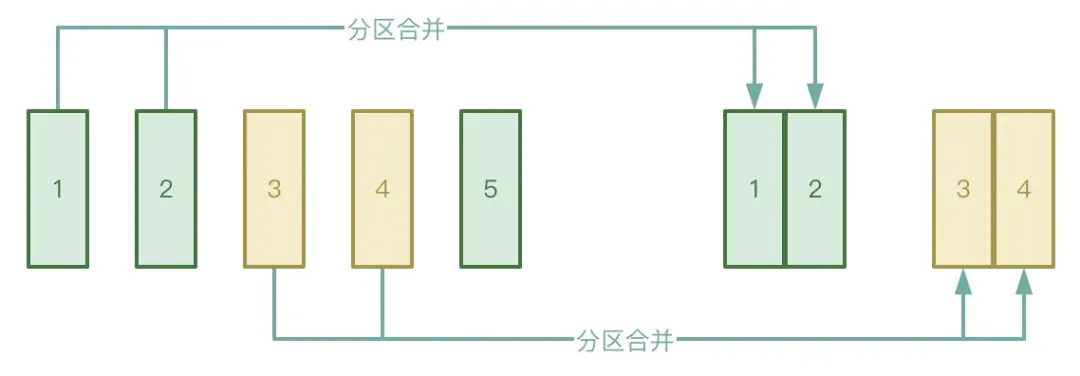
● 自動數據傾斜處理
應用場景主要在 Data Joins 中,當發生數據傾斜,AQE 能夠自動檢測到傾斜分區,並對傾斜分區按照一定的規則進行拆分。目前,在 Spark3.2 中,對 SortMergeJoin 和 ShuffleHashJoin 都支持自動數據傾斜處理。
● Join 策略調整
AQE 會動態的將 Hash Join、Sort Merge Join,降級調整為 Broadcast Join。
我們知道,Spark 任務一旦開始執行,並行度就已經確定。比如說,shuffle map 階段,並行度為分區的個數;shuffle reduce 階段並行度則為 spark.sql.shuffle.partitions 的值,預設為200。如果 Spark 任務在運行的過程中數據量變小導致大部分的分區的大小變小,這時如果仍然啟動那麼多的線程去處理小的數據集就會導致資源的浪費。
而 AQE 在執行過程會根據 shuffle 後生成的中間臨時結果,在一定條件下,通過應用 CoalesceShufflePartitions 規則,結合用戶提供的參數自動合併分區,其實就是調整 reducer 的數量。原來一個 reduce 線程只會拉取一個處理後的分區的數據,現在一個 reduce 線程會根據實際情況拉取更多的分區的數據,這樣就能減少資源的浪費,提高任務執行效率。
《行業指標體系白皮書》下載地址:https://www.dtstack.com/resources/1057?src=szsm
《數棧產品白皮書》下載地址:https://www.dtstack.com/resources/1004?src=szsm
《數據治理行業實踐白皮書》下載地址:https://www.dtstack.com/resources/1001?src=szsm
想瞭解或咨詢更多有關大數據產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠雲官網:https://www.dtstack.com/?src=szbky


