
如果想直接看結論,可直接跳轉到 快速生成方法在ToB的項目裡面,總免不了處理樹相關的數據,比如多級部門列表,比如多級分銷列表等等,凡是有上下級關聯的級聯數據,總免不了生成樹結構的數據。樹結構的數據在後端有很多種存儲方法,最常見的就是parent_id這種上下級關聯表。當然還有其它的例如左右值樹表等存... ...
如果想直接看結論,可直接跳轉到 快速生成方法
在ToB的項目裡面,總免不了處理樹相關的數據,比如多級部門列表,比如多級分銷列表等等,凡是有上下級關聯的級聯數據,總免不了生成樹結構的數據。
樹結構的數據在後端有很多種存儲方法,最常見的就是parent_id這種上下級關聯表。當然還有其它的例如左右值樹表等存儲結構。
本文暫時只討論parent_id關聯的這種樹結構,這時候後端範圍的數據為所有樹節點的list數據。
準備-測試數據生成代碼
為了方便測試,先寫一段隨機生成parent_id關聯list數據的代碼
代碼
// genTestData.js
function getRandomByRange(start, end) {
let length = end - start
return start + (Math.random() * length) >>> 0
}
function getRandomCode() {
return Math.random().toString(36).slice(2)
}
function getRandomCodeByData(data) {
return data[getRandomByRange(0, data.length)].code
}
export default function() {
let data = []
// 隨機生成 20-30 個一級節點
for (let i = 0, l = getRandomByRange(20, 30); i < l; i++) {
data.push({
facode: '0',
code: getRandomCode()
})
}
// 隨機生成 100-120 個隨機關聯節點
for (let i = 0, l = getRandomByRange(100, 120); i < l; i++) {
data.push({
facode: getRandomCodeByData(data),
code: getRandomCode()
})
}
return data.sort(() => (Math.random() - 0.5))
}
可修改 getRandomByRange 的參數,生成不同數量的測試數據
測試
測試生成效果如下
// demo.js
import genTestData from './genTestData.js'
const oriData = genTestData()
console.table(oriData)
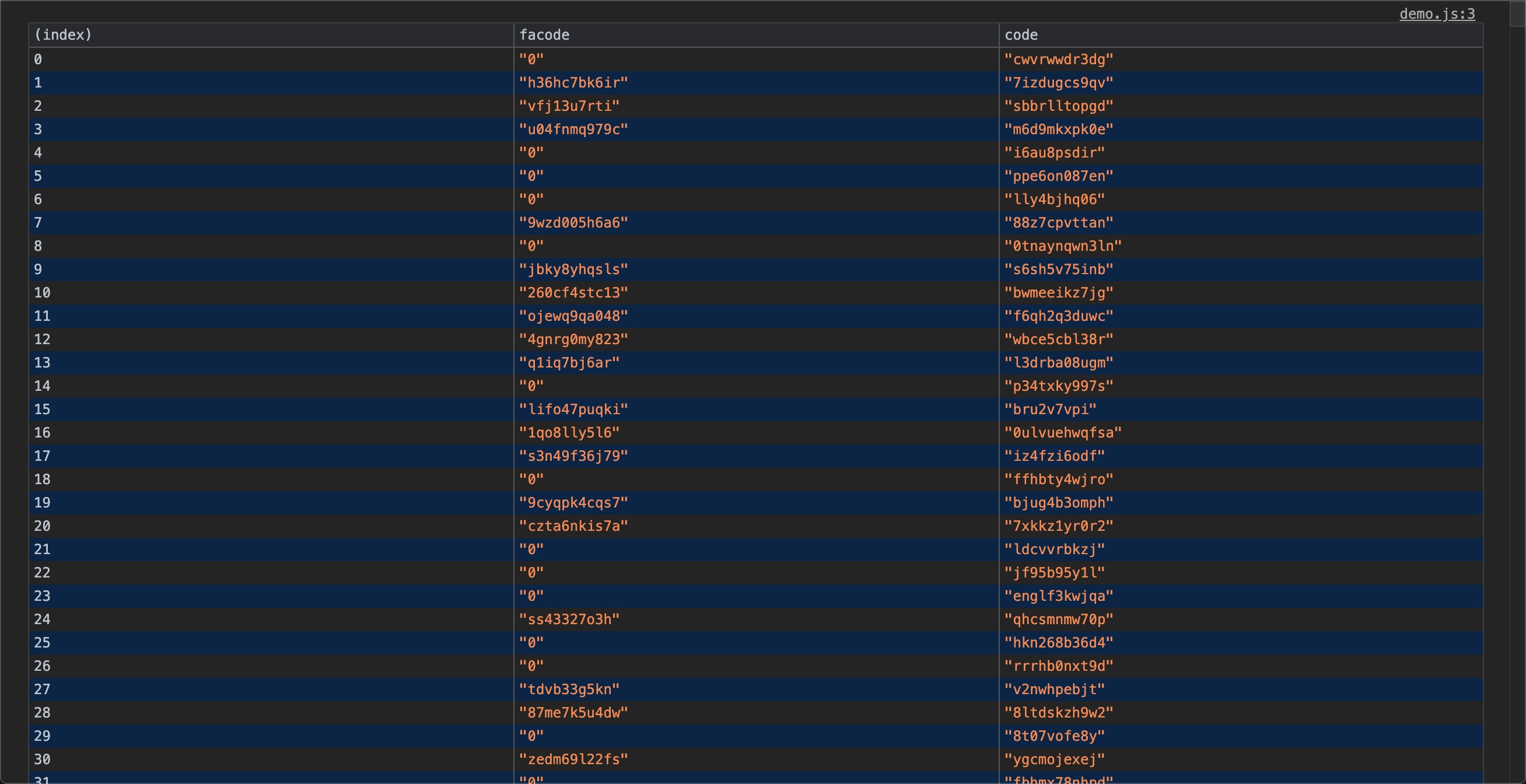
這時候有了測試數據,現在開始進入正題
常規生成方法
思路
從根節點開始,遍曆數據源,每次找到當前節點的子節點,掛到當前節點的 children 上,然後遞歸調用
代碼
// tree.js
export class TreeCreate {
constructor(treeNode, treeConfig) {
this.treeNode = treeNode
this.treeConfig = Object.assign({
fId: 'pid', // 關聯的 parent_id 欄位名
id: 'id', // 關聯的 parent_id 的 id 欄位名
rootId: '0', // 開始的 根節點關聯的 parent_id 對應的 欄位名
}, treeConfig)
this.treeData = [] // 樹數據
}
// 樹生成, 遞歸調用
createTree(data, parent = null) {
let config = this.treeConfig
let TreeNode = this.treeNode
let treeData, pid, i, l, val, children
treeData = []
for (i = 0, l = data.length; i < l; i++) {
val = data[i]
if (parent === null) {
pid = config.rootId
} else {
pid = parent[config.id]
}
if (val[config.fId] === pid) {
let t = {}
TreeNode.call(t, val)
children = this.createTree(data, Object.assign(t, val))
treeData.push(t)
treeData[treeData.length - 1].children = children
}
}
return treeData
}
// 生成樹
create(data) {
this.treeData = this.createTree(data)
}
// 獲取樹狀的樹數據(深拷貝)
getTreeData() {
// 演示簡易處理,無法處理迴圈引用對象,如果樹節點需要保留父級引用,則需要改為可以處理迴圈引用的深拷貝方法
return JSON.parse(JSON.stringify(this.treeData))
}
}
使用方式
treeNode 傳入樹節點數據生成函數,不能使用箭頭函數,this為當前節點,預設空對象。 接受參數item為原始數據對象,根據需要為this對象賦值欄位。如果簡單需要全欄位的,可以通過Object.keys遍歷參數的所有欄位,然後全部賦值到this的對應欄位上。
treeConfig 為配置參數
FId關聯的 parent_id 欄位名Id關聯的 parent_id 的 id 欄位名rootId開始的 根節點關聯的 parent_id 對應的 欄位名
測試性能
import genTestData from './genTestData.js'
import { TreeCreate } from './tree.js'
// 測試數據
const oriData = genTestData()
console.log(`樹節點數量 ${oriData.length}`)
// 樹
let demoTree = new TreeCreate(function(item) {
for (let key of Object.keys(item)) {
this[key] = item[key]
}
}, { fId: 'facode', id: 'code', rootId: '0' })
console.time('生成樹時間')
demoTree.create(oriData, true)
console.timeEnd('生成樹時間')
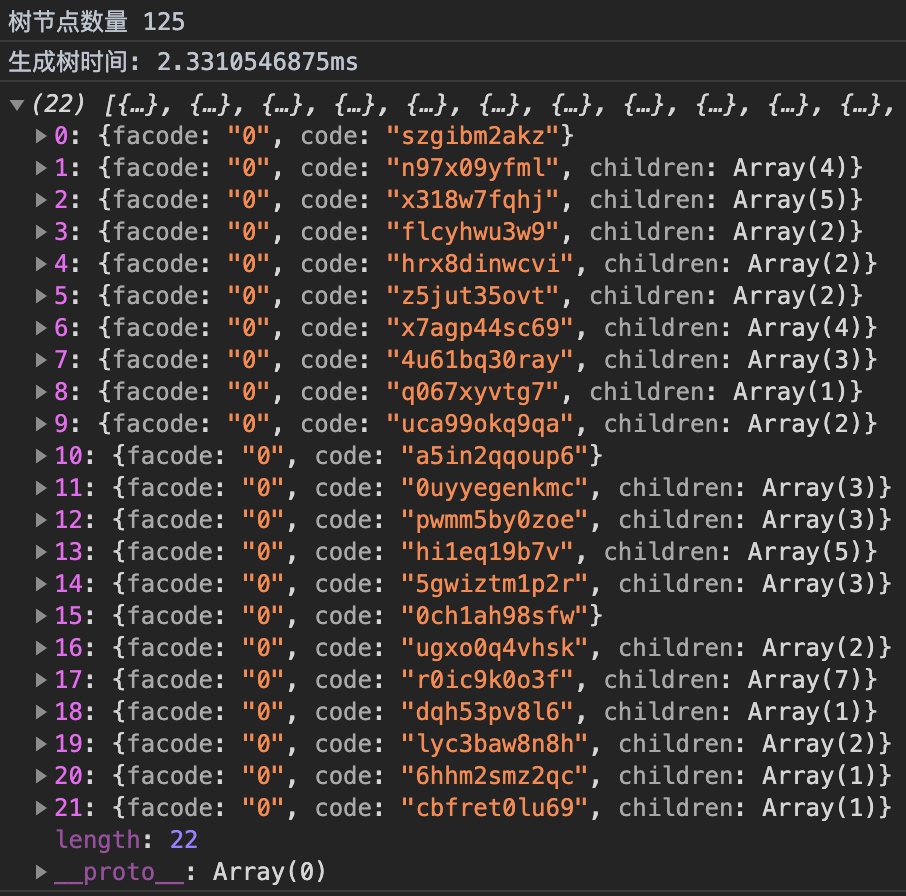
讓我們測試下性能
百級數據
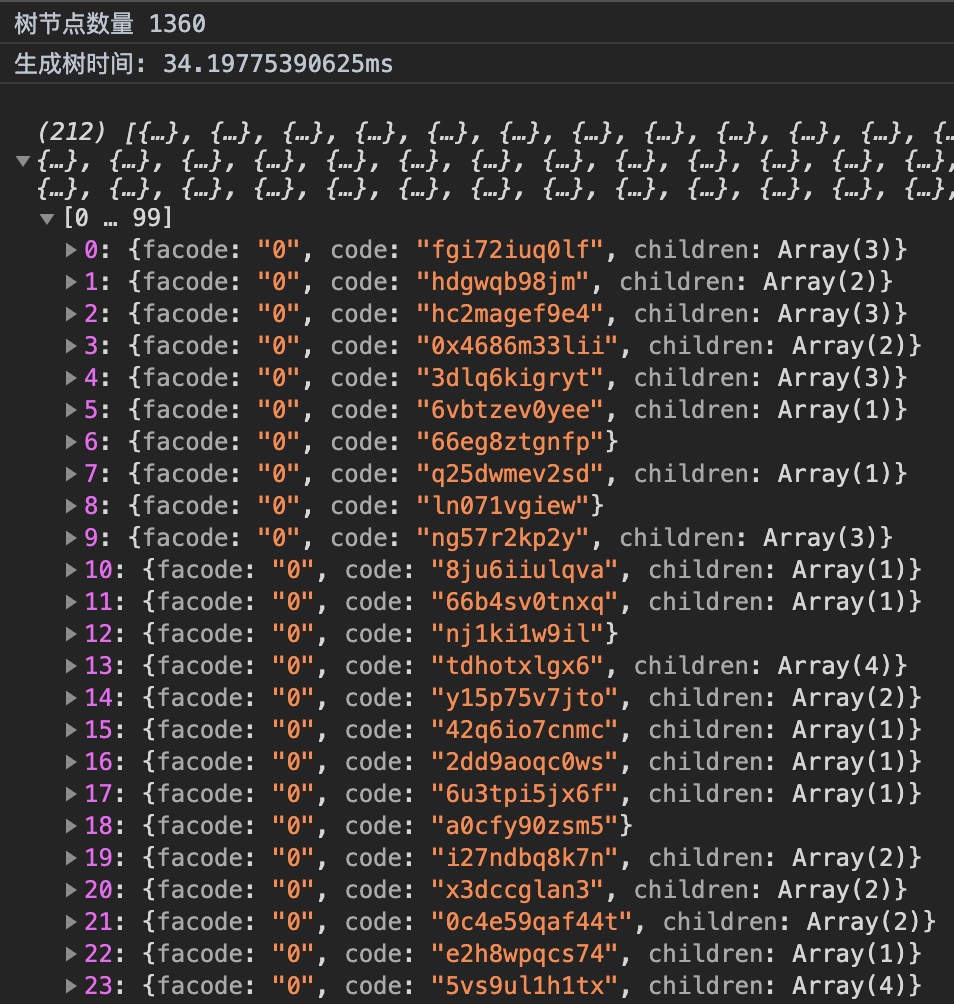
千級數據
可以看到性能已經有了明顯的下降
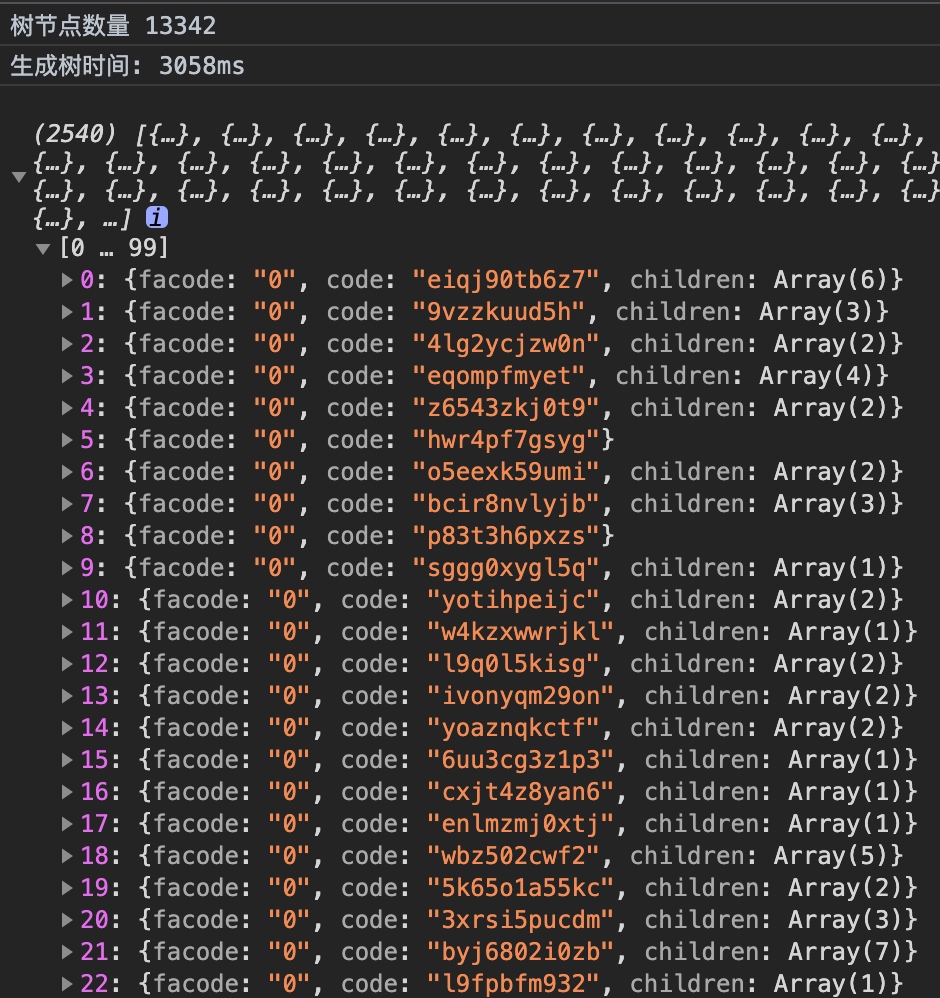
萬級數據
耗時將近3s多,會明顯造成頁面卡頓
這時候我們來找下原因,為什麼會讓生成函數隨著n的增加下降這麼嚴重。
如果仔細想想剛纔的演算法,不難發現其實其時間複雜度基本為O(n²),會隨著n的增加快速增加。
如果數據量改為十萬級,基本處於頁面卡死的狀態,當然正常情況下不會出現前端需要處理十萬級的數據,肯定是後端偷懶了,不過正常萬級的數據還是有可能需要處理的。
如何優化
仔細思考代碼重覆跑的地方,發現每次找某個節點的children的時候,會遍歷全部的數據源去判斷是否是當前節點的children。
這時候第一反應的優化點就是,當A節點已經是B節點的children的時候,就從數據源中刪除A節點,下次去查找C節點的children的時候就不會遍歷到A節點了。
這個可以自己嘗試下,有效果,不明顯,因為沒有改變某個節點被多次遍歷的本質,例如A節點是最後一個節點的children,那麼前面的children生成,還是每次會遍歷到A節點,A節點還是會被遍歷到多次。
而且從數據源中移除某個節點,其實也是耗時操作。
綜上所述,耗時是因為節點被無效的多次遍歷造成的,那麼能不能只遍歷一次然後用空間換時間的常規操作來優化遍歷呢。
這時候我們就會想到js的map對象,hash存儲,通過key可以直接得到value。
如果用fId作為key,存儲所有children信息作為value,那這樣每次查找當前節點的children的時候就從遍歷查找變成了從map中取值,因為hash存儲的關係,基本是忽略不計的取值時間。
快速生成方法
思路
思路上面的優化裡面已經說了,用js的map的key-value的特性,遍歷一次查找好所有的父子關係,然後遞歸的地方只管生成就行了
代碼
// tree.js
export class TreeCreateFast {
constructor(treeNode, treeConfig) {
this.treeNode = treeNode
this.treeConfig = Object.assign({
fId: 'pid', // 關聯的 parent_id 欄位名
id: 'id', // 關聯的 parent_id 的 id 欄位名
rootId: '0', // 開始的 根節點關聯的 parent_id 對應的 欄位名
}, treeConfig)
this.treeData = [] // 樹狀的樹數據
}
// 按 fId 分組
groupBy(data) {
let config = this.treeConfig
let group = []
data.forEach(v => {
let key = v[config.fId]
if (!group.hasOwnProperty(key)) {
group[key] = [v]
} else {
group[key].push(v)
}
})
return group
}
// 樹生成, 遞歸調用
createTree(data, parent = null) {
let config = this.treeConfig
let TreeNode = this.treeNode
let treeData, pid, children
treeData = []
if (parent === null) {
pid = config.rootId
} else {
pid = parent[config.id]
}
if (data.hasOwnProperty(pid)) {
data[pid].forEach(val => {
let t = {}
TreeNode.call(t, val)
children = this.createTree(data, Object.assign(t, val))
treeData.push(t)
treeData[treeData.length - 1].children = children
})
}
return treeData
}
// 生成樹
create(data) {
this.treeData = this.createTree(this.groupBy(data))
}
// 獲取樹狀的樹數據(深拷貝)
getTreeData() {
// 演示簡易處理,無法處理迴圈引用對象,如果樹節點需要保留父級引用,則需要改為可以處理迴圈引用的深拷貝方法
return JSON.parse(JSON.stringify(this.treeData))
}
}
使用方式
使用方式跟常規的樹生成函數一致
測試性能
import genTestData from './genTestData.js'
import { TreeCreateFast } from './tree.js'
// 測試數據
const oriData = genTestData()
console.log(`樹節點數量 ${oriData.length}`)
// 樹
let demoTree = new TreeCreateFast(function(item) {
for (let key of Object.keys(item)) {
this[key] = item[key]
}
}, { fId: 'facode', id: 'code', rootId: '0' })
console.time('生成樹時間')
demoTree.create(oriData, true)
console.timeEnd('生成樹時間')
測試下性能,直接從萬級開始
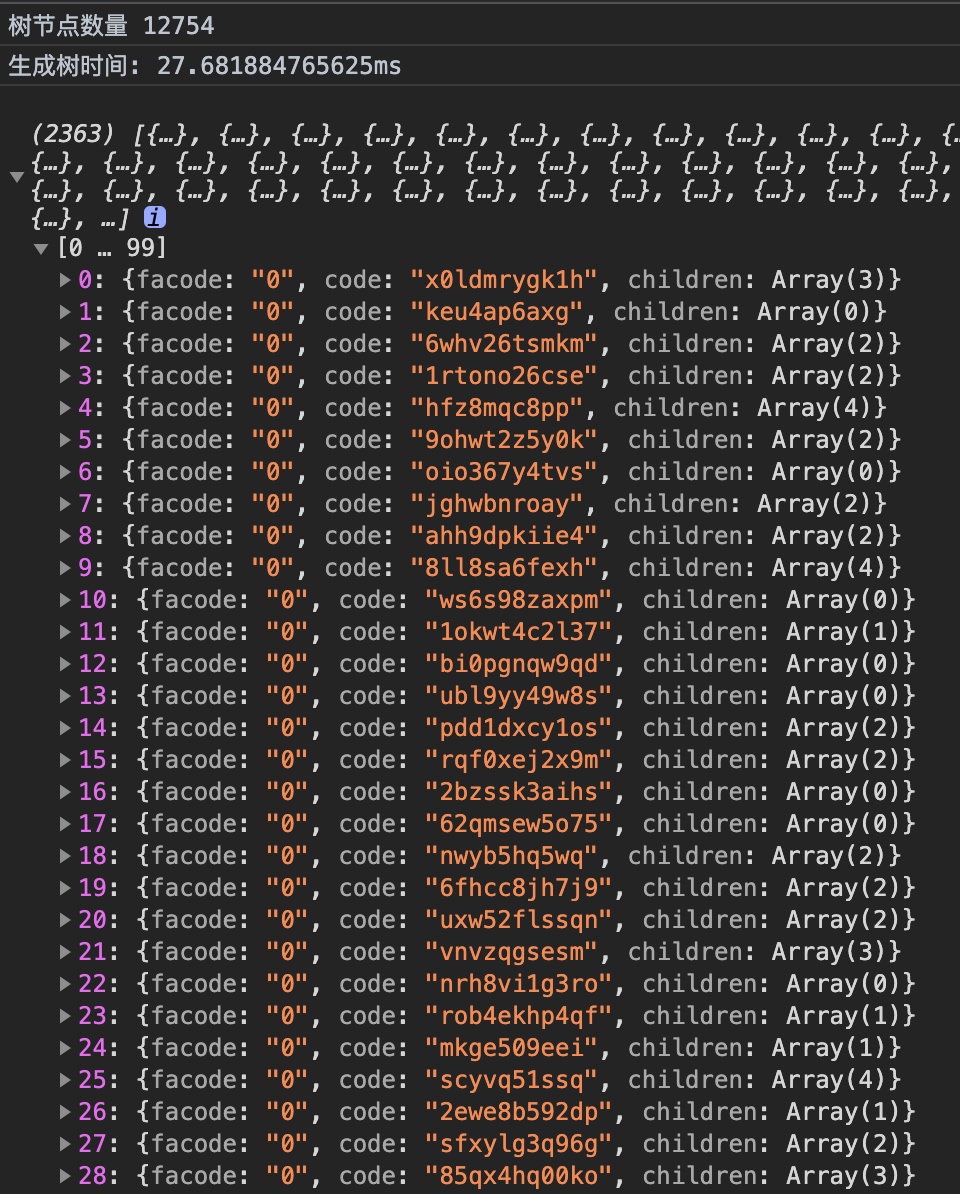
萬級數據
在常規項目能接觸的數據量上,已經處於無感了,基本就會卡個一幀
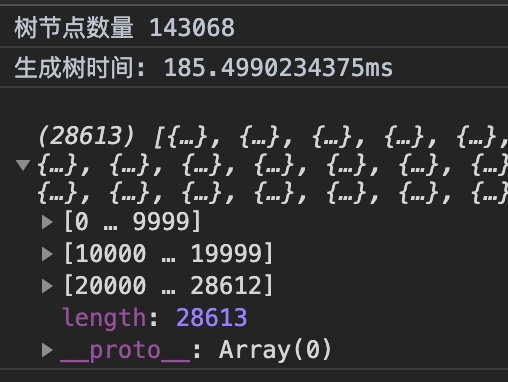
十萬級數據
處於可以接受的範圍,畢竟不可能有十萬級的數據需要處理的
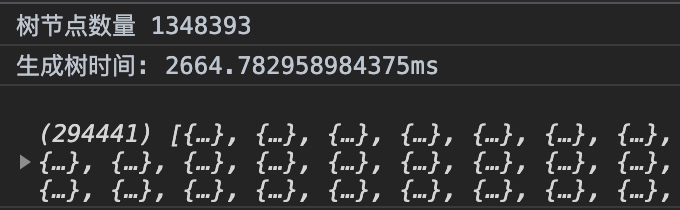
挑戰下百萬級
就玩玩試試,沒任何實際意義
總結
通過map優化了遍歷之後,解決多次重覆的無用遍歷之後,性能提升非常明顯,基本常規項目使用場景下不會造成任何瀏覽器卡頓。
當然如果再使用 Web Worker 優化的話可以讓用戶在獲得流暢的訪問體驗上,快速看到所需的數據。
才疏學淺。如有疏漏歡迎指正,有建議敬請提出。歡迎各位大佬一起討論。

