
要實現這個示例,必須先安裝好hadoop和hive環境,環境部署可以參考我之前的文章: 大數據Hadoop原理介紹+安裝+實戰操作(HDFS+YARN+MapReduce) 大數據Hadoop之——數據倉庫Hive 【流程圖如下】 【示例代碼如下】 #!/usr/bin/env python # - ...
要實現這個示例,必須先安裝好hadoop和hive環境,環境部署可以參考我之前的文章:
大數據Hadoop原理介紹+安裝+實戰操作(HDFS+YARN+MapReduce)
大數據Hadoop之——數據倉庫Hive
【流程圖如下】
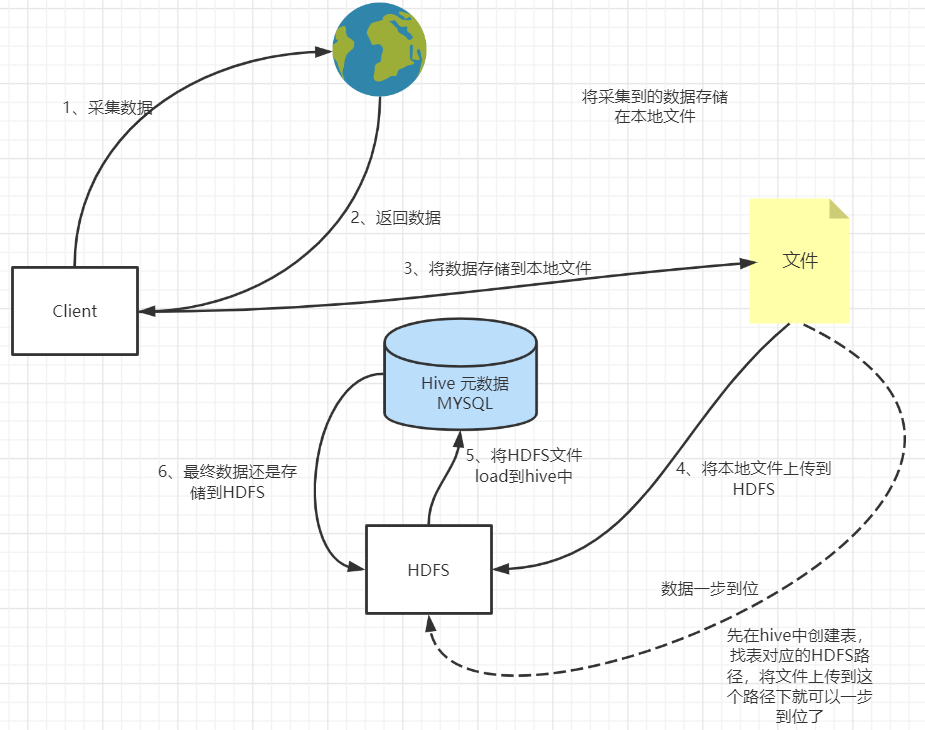
【示例代碼如下】
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author : liugp
# @File : Data2HDFS.py
"""
# pip install sasl可能安裝不成功
pip install sasl
# 可以選擇離線安裝
https://www.lfd.uci.edu/~gohlke/pythonlibs/#sasl
pip install sasl-0.3.1-cp37-cp37m-win_amd64.whl
pip install thrift
pip install thrift-sasl
pip install pyhive
pip install hdfs
"""
from selenium import webdriver
from pyhive import hive
from hdfs import InsecureClient
class Data2HDFS:
def __init__(self):
# 第一個步,連接到hive
conn = hive.connect(host='192.168.0.113', port=11000, username='root', database='default')
# 第二步,建立一個游標
self.cursor = conn.cursor()
self.fs = InsecureClient(url='http://192.168.0.113:9870/', user='root', root='/')
"""
採集數據
"""
def collectData(self):
try:
driver = webdriver.Edge("../drivers/msedgedriver.exe")
# 爬取1-3頁數據,可自行擴展
id = 1
local_path = './data.txt'
with open(local_path, 'w', encoding='utf-8') as f:
for i in range(1, 2):
url = "https://ac.qq.com/Comic/index/page/" + str(i)
driver.get(url)
# 模擬滾動
js = "return action=document.body.scrollHeight"
new_height = driver.execute_script(js)
for i in range(0, new_height, 10):
driver.execute_script('window.scrollTo(0, %s)' % (i))
list = driver.find_element_by_class_name('ret-search-list').find_elements_by_tag_name('li')
data = []
for item in list:
imgsrc = item.find_element_by_tag_name('img').get_attribute('src')
author = item.find_element_by_class_name("ret-works-author").text
leixing_spanlist = item.find_element_by_class_name("ret-works-tags").find_elements_by_tag_name(
'span')
leixing = leixing_spanlist[0].text + "," + leixing_spanlist[1].text
neirong = item.find_element_by_class_name("ret-works-decs").text
gengxin = item.find_element_by_class_name("mod-cover-list-mask").text
itemdata = {"id": str(id), 'imgsrc': imgsrc, 'author': author, 'leixing': leixing, 'neirong': neirong,
'gengxin': gengxin}
print(itemdata)
line = itemdata['id'] +"," + itemdata['imgsrc'] +"," + itemdata['author'] + "," + itemdata['leixing'] + "," + itemdata['neirong'] + itemdata['gengxin'] + "\n"
f.write(line)
id+=1
data.append(itemdata)
# 上傳文件,
d2f.uplodatLocalFile2HDFS(local_path)
except Exception as e:
print(e)
"""創建hive表"""
def createTable(self):
# 解決hive表中文亂碼問題
"""
mysql -uroot -p
use hive資料庫
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
commit;
:return:
"""
self.cursor.execute("CREATE TABLE IF NOT EXISTS default.datatable (\
id INT COMMENT 'ID',\
imgsrc STRING COMMENT 'img src',\
author STRING COMMENT 'author',\
leixing STRING COMMENT '類型',\
neirong STRING COMMENT '內容',\
gengxin STRING COMMENT '更新'\
)\
ROW FORMAT DELIMITED\
FIELDS TERMINATED BY ','\
COLLECTION ITEMS TERMINATED BY '-'\
MAP KEYS TERMINATED BY ':'\
LINES TERMINATED BY '\n'")
"""
將本地文件推送到HDFS上
"""
def uplodatLocalFile2HDFS(self, local_path):
hdfs_path = '/tmp/test0508/'
self.fs.makedirs(hdfs_path)
# 如果文件存在就必須先刪掉
self.fs.delete(hdfs_path + '/' + local_path)
print(hdfs_path, local_path)
self.fs.upload(hdfs_path, local_path)
"""
將HDFS上的文件load到hive表
"""
def data2Hive(self):
# 先清空表
self.cursor.execute("truncate table datatable")
# 載入數據,這裡的路徑就是HDFS上的文件路徑
self.cursor.execute("load data inpath '/tmp/test0508/data.txt' into table datatable")
self.cursor.execute("select * from default.datatable")
print(self.cursor.fetchall())
if __name__ == "__main__":
d2f = Data2HDFS()
# 收集數據
d2f.collectData()
# 創建hive表
# d2f.createTable()
# 將數據存儲到HDFS
d2f.data2Hive()
【溫馨提示】hiveserver2的預設埠是10000,我是上面寫的11000埠,是因為我配置文件里修改了,如果使用的是預設埠,記得修改成10000埠,還有就是修改成自己的host地址。這個只是一種實現方式,還有其它方式。
如果小伙伴有疑問的話,歡迎給我留言,後續會更新更多關於大數據的文章,請耐心等待~


