
一、ZooKeeper概述 Apache ZooKeeper 是一個集中式服務,用於維護配置信息、命名、提供分散式同步和提供組服務,ZooKeeper 致力於開發和維護一個開源伺服器,以實現高度可靠的分散式協調,其實也可以認為就是一個分散式資料庫,只是結構比較特殊,是樹狀結構。官網文檔:https: ...
目錄
- 一、ZooKeeper概述
- 二、ZooKeeper數據模型
- 三、ZooKeeper架構
- 四、ZooKeeper中Observer【ZooKeeper伸縮性】
- 五、ZooKeeper原理
- 六、Zookeeper安裝
- 七、常用操作命令
一、ZooKeeper概述
Apache ZooKeeper 是一個集中式服務,用於維護配置信息、命名、提供分散式同步和提供組服務,ZooKeeper 致力於開發和維護一個開源伺服器,以實現高度可靠的分散式協調,其實也可以認為就是一個分散式資料庫,只是結構比較特殊,是樹狀結構。官網文檔:https://zookeeper.apache.org/doc/r3.8.0/
特點:
- 順序一致性 :來自客戶端的更新將按照它們發送的順序應用。
- 原子性 :更新成功或失敗。沒有部分結果。
- 單一系統映像 :客戶端將看到相同的服務視圖,而不管它連接到的伺服器如何。即,即使客戶端故障轉移到具有相同會話的不同伺服器,客戶端也永遠不會看到系統的舊視圖。
- 可靠性:應用更新後,它將從那時起持續存在,直到客戶端覆蓋更新。
- 及時性:系統的客戶視圖保證在一定的時間範圍內是最新的。
二、ZooKeeper數據模型
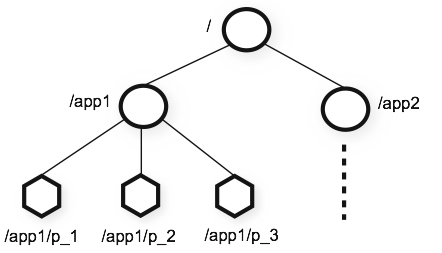
從上圖中我們可以看出ZooKeeper的數據模型,在結構上和標準文件系統的非常相似,都是採用這種樹形層次結構,ZooKeeper樹中的每個節點被稱為—Znode。和文件系統的目錄樹一樣,ZooKeeper樹中的每個節點可以擁有子節點。但也有不同之處:
1)ZooKeeper數據模型Znode
ZooKeeper擁有一個層次的命名空間,這個和標準的文件系統非常相似。
1、引用方式
Zonde通過路徑引用,如同Unix中的文件路徑。路徑必須是絕對的,因此他們必須由斜杠字元來開頭。除此以外,他們必須是唯一的,也就是說每一個路徑只有一個表示,因此這些路徑不能改變。在ZooKeeper中,路徑由Unicode字元串組成,並且有一些限制。字元串"/zookeeper"用以保存管理信息,比如關鍵配額信息。
2、Znode結構
ZooKeeper命名空間中的Znode,兼具文件和目錄兩種特點。既像文件一樣維護著數據、元信息、ACL、時間戳等數據結構,又像目錄一樣可以作為路徑標識的一部分。圖中的每個節點稱為一個Znode。 每個Znode由3部分組成:
- stat:此為狀態信息, 描述該Znode的版本, 許可權等信息
- data:與該Znode關聯的數據
- children:該Znode下的子節點
【溫馨提示】ZooKeeper雖然可以關聯一些數據,但並沒有被設計為常規的資料庫或者大數據存儲,相反的是,它用來管理調度數據,比如分散式應用中的配置文件信息、狀態信息、彙集位置等等。這些數據的共同特性就是它們都是很小的數據,通常以KB為大小單位。ZooKeeper的伺服器和客戶端都被設計為嚴格檢查並限制每個Znode的數據大小至多
1M,但常規使用中應該遠小於此值。
3、節點類型
ZooKeeper中的節點有兩種,分別為臨時節點和永久節點。節點的類型在創建時即被確定,並且不能改變。
- 臨時節點:該節點的生命周期依賴於創建它們的會話。一旦會話(Session)結束,臨時節點將被自動刪除,當然可以也可以手動刪除。雖然每個臨時的Znode都會綁定到一個客戶端會話,但他們對所有的客戶端還是可見的。另外,ZooKeeper的臨時節點不允許擁有子節點。
- 永久節點:該節點的生命周期不依賴於會話,並且只有在客戶端顯示執行刪除操作的時候,他們才能被刪除。
4、觀察
客戶端可以在節點上設置
watch,我們稱之為監視器。當節點狀態發生改變時(Znode的增、刪、改)將會觸發watch所對應的操作。當watch被觸發時,ZooKeeper將會向客戶端發送且僅發送一條通知,因為watch只能被觸發一次,這樣可以減少網路流量。
2)ZooKeeper中的時間
ZooKeeper有多種記錄時間的形式,其中包含以下幾個主要屬性:
1、Zxid
致使ZooKeeper節點狀態改變的每一個操作都將使節點接收到一個Zxid格式的時間戳,並且這個時間戳全局有序。也就是說,也就是說,每個對節點的改變都將產生一個唯一的Zxid。如果Zxid1的值小於Zxid2的值,那麼Zxid1所對應的事件發生在Zxid2所對應的事件之前。實際上,ZooKeeper的每個節點維護者三個Zxid值,為別為:cZxid、mZxid、pZxid。
cZxid: 是節點的創建時間所對應的Zxid格式時間戳。mZxid:是節點的修改時間所對應的Zxid格式時間戳。
實現中Zxid是一個64為的數字,它高32位是epoch用來標識leader關係是否改變,每次一個leader被選出來,它都會有一個 新的epoch。低32位是個遞增計數。
2、版本號
對節點的每一個操作都將致使這個節點的版本號增加。每個節點維護著三個版本號,他們分別為:
version:節點數據版本號cversion:子節點版本號aversion:節點所擁有的ACL版本號
3)ZooKeeper節點屬性
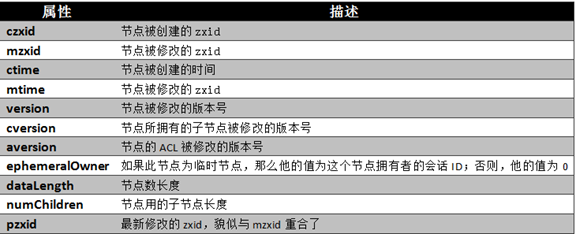
通過前面的介紹,我們可以瞭解到,一個節點自身擁有表示其狀態的許多重要屬性,如下圖所示:
三、ZooKeeper架構

- Leader:負責進行投票的發起和決議,更新系統狀態,Leader 是由選舉產生;
- Follower: 用於接受客戶端請求並向客戶端返回結果,在選主過程中參與投票;
- Observer:可以接受客戶端連接,接受讀寫請求,寫請求轉發給 Leader,但 Observer 不參加投票過程,只同步 Leader 的狀態,Observer 的目的是為了擴展系統,提高讀取速度。
四、ZooKeeper中Observer【ZooKeeper伸縮性】
- 在Observer出現以前,ZooKeeper的伸縮性由Follower來實現,我們可以通過添加Follower節點的數量來保證ZooKeeper服務的讀性能。
- 但是隨著Follower節點數量的增加,ZooKeeper服務的寫性能受到了影響;Zab協議對寫請求的處理過程中我們可以發現,增加伺服器的數量,則增加了對協議中投票過程的壓力,隨著 ZooKeeper 集群變大,寫操作的吞吐量會下降;
- 所以,我們不得不,在增加Client數量的期望和我們希望保持較好吞吐性能的期望間進行權衡,要打破這一耦合關係,我們引入了不參與投票的伺服器,稱為 Observer。
- Observer可以接受客戶端的連接,並將寫請求轉發給Leader節點。但是,Leader節點不會要求 Observer參加投票。
- 相反,Observer不參與投票過程,但是和其他服務節點一樣得到投票結果。

從上圖顯示了一個簡單評測的結果。縱軸是,單一客戶端能夠發出的每秒鐘同步寫操作的數量。橫軸是 ZooKeeper 集群的尺寸。藍色的是每個伺服器都是投票Server的情況,而綠色的則只有三個是投票Server,其它都是 Observer。從圖中我們可以看出,我們在擴充 Observer時寫性能幾乎可以保持不便。但是,如果擴展投票Server的數量,寫性能會明顯下降,顯然 Observers 是有效的。
五、ZooKeeper原理
Zookeeper的核心是原子廣播機制,這個機制保證了各個server之間的同步。實現這個機制的協議叫做Zab協議。Zab協議有兩種模式,它們分別是恢復模式和廣播模式。
1)恢復模式
當服務啟動或者在領導者崩潰後,Zab就進入了恢復模式,當領導者被選舉出來,且大多數server完成了和leader的狀態同步以後,恢復模式就結束了。狀態同步保證了leader和server具有相同的系統狀態。
2)廣播模式
-
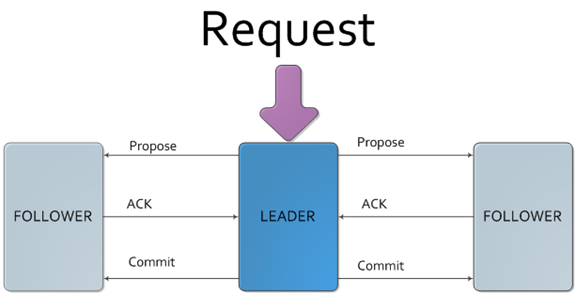
一旦Leader已經和多數的Follower進行了狀態同步後,他就可以開始廣播消息了,即進入廣播狀態。這時候當一個Server加入ZooKeeper服務中,它會在恢復模式下啟動,發現Leader,並和Leader進行狀態同步。待到同步結束,它也參與消息廣播。ZooKeeper服務一直維持在Broadcast狀態,直到Leader崩潰了或者Leader失去了大部分的Followers支持。
-
Broadcast模式極其類似於分散式事務中的2pc(two-phrase commit 兩階段提交):即Leader提起一個決議,由Followers進行投票,Leader對投票結果進行計算決定是否通過該決議,如果通過執行該決議(事務),否則什麼也不做。
-
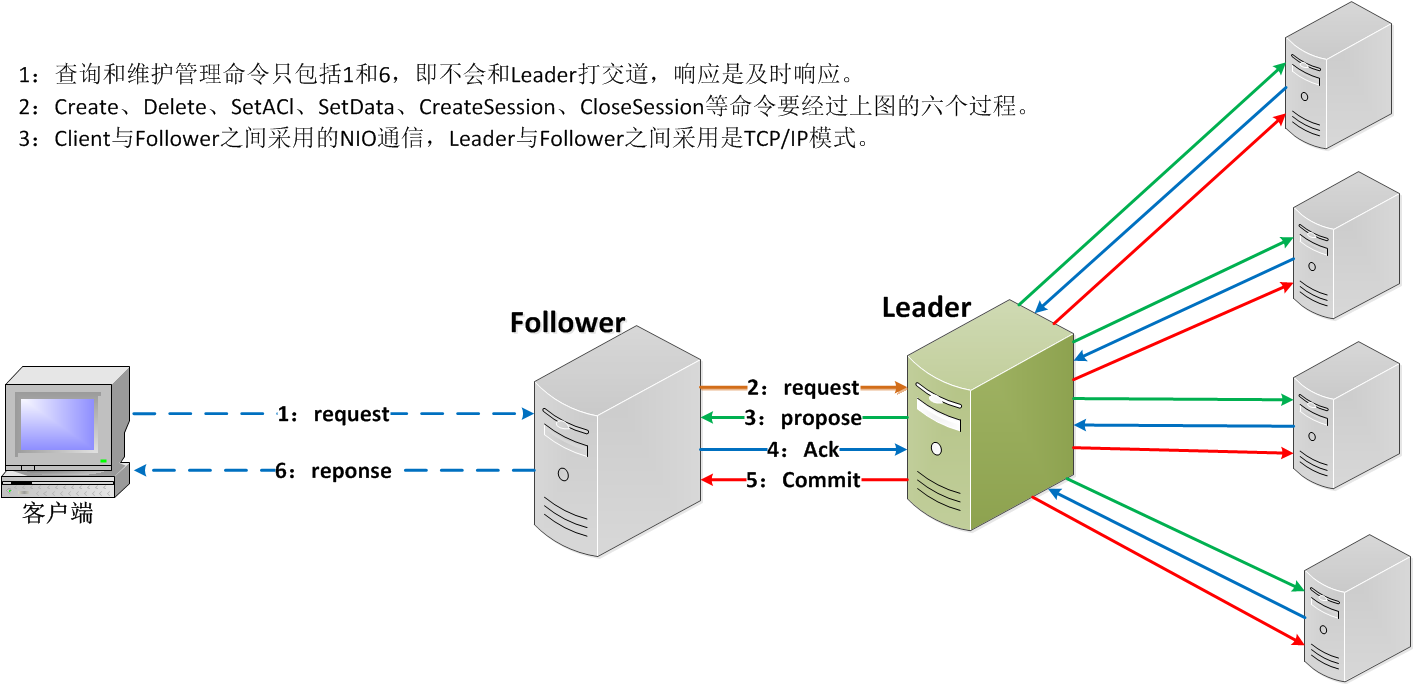
在廣播模式ZooKeeper Server會接受Client請求,所有的寫請求都被轉發給leader,再由領導者將更新廣播給跟隨者,而查詢和維護管理命令不用跟leader打交道。當半數以上的跟隨者已經將修改持久化之後,領導者才會提交這個更新,然後客戶端才會收到一個更新成功的響應。這個用來達成共識的協議被設計成具有原子性,因此每個修改要麼成功要麼失敗。
六、Zookeeper安裝
1)獨立集群安裝
1、下載
$ cd /opt/bigdata/hadoop/software
$ wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz
$ tar -xf apache-zookeeper-3.8.0-bin.tar.gz -C /opt/bigdata/hadoop/server/
2、配置環境變數
$ vi /etc/profile
export ZOOKEEPER_HOME=/opt/bigdata/hadoop/server/apache-zookeeper-3.8.0-bin/
export PATH=$ZOOKEEPER_HOME/bin:$PATH
$ source /etc/profile
3、配置
$ cd $ZOOKEEPER_HOME
$ cp conf/zoo_sample.cfg conf/zoo.cfg
$ mkdir $ZOOKEEPER_HOME/data
$ cat >conf/zoo.cfg<<EOF
# tickTime:Zookeeper 伺服器之間或客戶端與伺服器之間維持心跳的時間間隔,也就是每個 tickTime 時間就會發送一個心跳。tickTime以毫秒為單位。session最小有效時間為tickTime*2
tickTime=2000
# Zookeeper保存數據的目錄,預設情況下,Zookeeper將寫數據的日誌文件也保存在這個目錄里。不要使用/tmp目錄
dataDir=/opt/bigdata/hadoop/server/apache-zookeeper-3.8.0-bin/data
# 埠,預設就是2181
clientPort=2181
# 集群中的follower伺服器(F)與leader伺服器(L)之間初始連接時能容忍的最多心跳數(tickTime的數量),超過此數量沒有回覆會斷開鏈接
initLimit=10
# 集群中的follower伺服器與leader伺服器之間請求和應答之間能容忍的最多心跳數(tickTime的數量)
syncLimit=5
# 最大客戶端鏈接數量,0不限制,預設是0
maxClientCnxns=60
# zookeeper集群配置項,server.1,server.2,server.3是zk集群節點;hadoop-node1,hadoop-node2,hadoop-node3是主機名稱;2888是主從通信埠;3888用來選舉leader
server.1=hadoop-node1:2888:3888
server.2=hadoop-node2:2888:3888
server.3=hadoop-node3:2888:3888
EOF
4、配置myid
$ echo 1 > $ZOOKEEPER_HOME/data/myid
5、將配置推送到其它節點
$ scp -r $ZOOKEEPER_HOME hadoop-node2:/opt/bigdata/hadoop/server/
$ scp -r $ZOOKEEPER_HOME hadoop-node3:/opt/bigdata/hadoop/server/
# 也需要添加環境變數和修改myid,hadoop-node2的myid設置2,hadoop-node3的myid設置3
6、啟動服務
$ cd $ZOOKEEPER_HOME
# 啟動
$ ./bin/zkServer.sh start
# 查看狀態
$ ./bin/zkServer.sh status
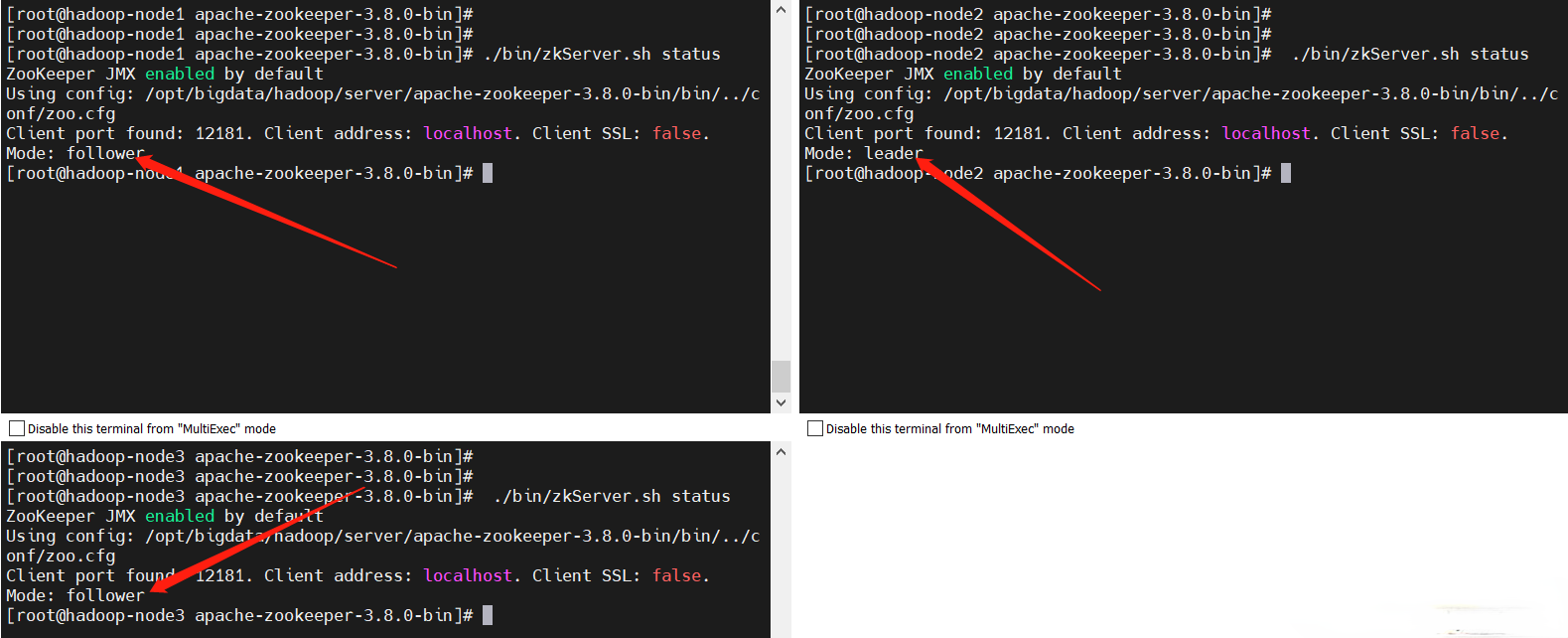
從上圖很容易就看出那個是leader和follower,到這裡部署就ok了。
2)與Kafka集成安裝
kafka官網文檔:https://kafka.apache.org/documentation/
1、下載kafka
$ cd /opt/bigdata/hadoop/software
$ wget https://dlcdn.apache.org/kafka/3.1.1/kafka_2.13-3.1.1.tgz
$ tar -xf kafka_2.13-3.1.1.tgz -C /opt/bigdata/hadoop/server/
2、配置環境變數
這裡配置kafka的環境變數,畢竟是kafka里自帶的zookeeper
$ vi /etc/profile
export KAFKA_HOME=/opt/bigdata/hadoop/server/kafka_2.13-3.1.1
export PATH=$PATH:$KAFKA_HOME/bin
$ source /etc/profile
3、修改zookeeper配置
配置跟上面一樣,這裡我換個埠12181
$ cd $KAFKA_HOME
$ cat >./config/zookeeper.properties<<EOF
# tickTime:Zookeeper 伺服器之間或客戶端與伺服器之間維持心跳的時間間隔,也就是每個 tickTime 時間就會發送一個心跳。tickTime以毫秒為單位。session最小有效時間為tickTime*2
tickTime=2000
# Zookeeper保存數據的目錄,預設情況下,Zookeeper將寫數據的日誌文件也保存在這個目錄里。不要使用/tmp目錄
dataDir=/opt/bigdata/hadoop/server/apache-zookeeper-3.8.0-bin/data
# 埠,預設2181
clientPort=12181
# 集群中的follower伺服器(F)與leader伺服器(L)之間初始連接時能容忍的最多心跳數(tickTime的數量),超過此數量沒有回覆會斷開鏈接
initLimit=10
# 集群中的follower伺服器與leader伺服器之間請求和應答之間能容忍的最多心跳數(tickTime的數量)
syncLimit=5
# 最大客戶端鏈接數量,0不限制,預設是0
maxClientCnxns=60
# zookeeper集群配置項,server.1,server.2,server.3是zk集群節點;hadoop-node1,hadoop-node2,hadoop-node3是主機名稱;2888是主從通信埠;3888用來選舉leader
server.1=hadoop-node1:2888:3888
server.2=hadoop-node2:2888:3888
server.3=hadoop-node3:2888:3888
EOF
4、啟動服務
$ ./bin/zookeeper-server-start.sh -daemon ./config/zookeeper.properties

好像kafka自帶的zookeeper沒辦法查zookeeper的集群狀態,所以不建議使用kafka內置的zookeeper,如果有小伙伴知道怎麼查kafka里自帶zookeeper的集群狀態,歡迎給我留言哦~
七、常用操作命令
# kafka自帶的zookeeper客戶端啟動如下:
$ cd $KAFKA_HOME
$ ./bin/zookeeper-shell.sh hadoop-node1:12181
# 獨立zookeeper客戶端啟動如下:
$ cd $ZOOKEEPER_HOME
$ zkCli.sh -server hadoop-node1:2181
# 查看幫助
help
1)創建節點
雖然上面只說了兩種節點類型,其實嚴格來講有四種節點類型:
持久節點
持久順序節點
臨時節點
臨時順序節點
接下來分別創建這四種類型的節點
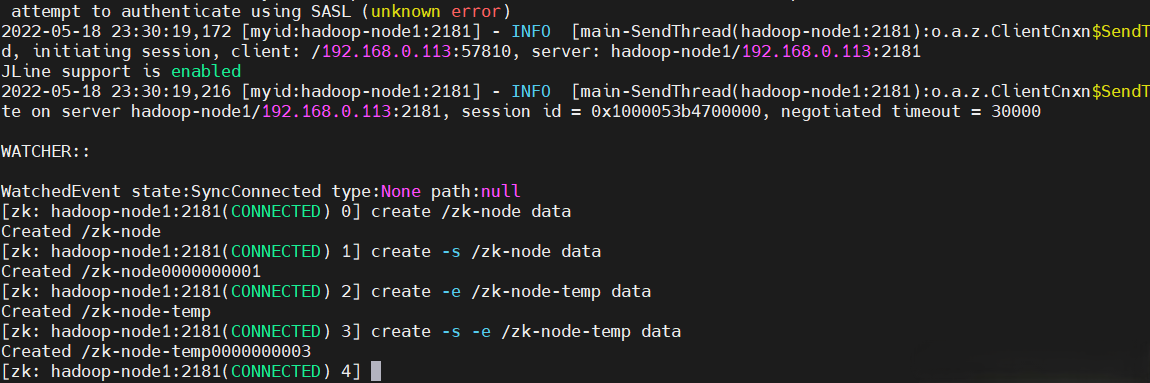
# 【持久節點】數據節點創建後,一直存在,直到有刪除操作主動清除,示例如下:
create /zk-node data
# 【持久順序節點】節點一直存在,zk自動追加數字尾碼做節點名,尾碼上限 MAX(int),示例如下:
create -s /zk-node data
# 【臨時節點】生命周期和會話相同,客戶端會話失效,則臨時節點被清除,示例如下:
create -e /zk-node-temp data
# 【臨時順序節點】臨時節點+順序節點尾碼,示例如下:
create -s -e /zk-node-temp data
2)查看節點
# 列出zk執行節點的所有子節點,只能看到第一級子節點
ls /
# 獲取zk指定節點數據內容和屬性
get /zk-node

3)更新節點
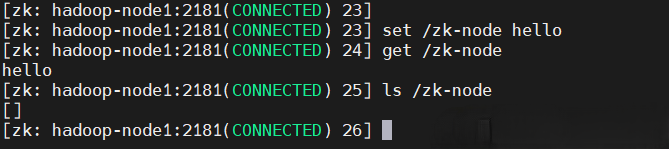
# 表達式:set ${path} ${data} [version]
set /zk-node hello
get /zk-node
4)刪除節點
# 對於包含子節點的節點,該命令無法成功刪除,使用deleteall /zk-node
delete /zk-node
Zookeeper架構、環境部署和基礎操作就到這裡了,後續會有更多相關內容的文章,請小伙伴耐心等待,有疑問的歡迎給我留言哦~


