
一、基本說明 • Oracle 中的函數可以返回表類型,但是這個表類型實際上是集合類型(與數組類似)。從 Oracle 9i 開始,提供了一個叫做"管道化表函數"來解決此問題。 • 管道化表函數,必須返回一個集合類型,且標明 pipelined。它不能返回具體變數,必須以一個空 return 返回, ...
第11章 Hive實戰
11.1 需求描述
統計矽谷影音視頻網站的常規指標,各種TopN指標:
-- 統計視頻觀看數Top10
-- 統計視頻類別熱度Top10
-- 統計出視頻觀看數最高的20個視頻的所屬類別以及類別包含Top20視頻的個數
-- 統計視頻觀看數Top50所關聯視頻的所屬類別Rank
-- 統計每個類別中的視頻熱度Top10,以Music為例
-- 統計每個類別視頻觀看數Top10
-- 統計上傳視頻最多的用戶Top10以及他們上傳的視頻觀看次數在前20的視頻
11.2 數據結構
1)視頻表
視頻表
| 欄位 | 備註 | 詳細描述 |
|---|---|---|
| videoId | 視頻唯一id(String) | 11位字元串 |
| uploader | 視頻上傳者(String) | 上傳視頻的用戶名String |
| age | 視頻年齡(int) | 視頻在平臺上的整數天 |
| category | 視頻類別(Array |
上傳視頻指定的視頻分類 |
| length | 視頻長度(Int) | 整形數字標識的視頻長度 |
| views | 觀看次數(Int) | 視頻被瀏覽的次數 |
| rate | 視頻評分(Double) | 滿分5分 |
| Ratings | 流量(Int) | 視頻的流量,整型數字 |
| conments | 評論數(Int) | 一個視頻的整數評論數 |
| relatedId | 相關視頻id(Array |
相關視頻的id,最多20個 |
2)用戶表
用戶表
| 欄位 | 備註 | 欄位類型 |
|---|---|---|
| uploader | 上傳者用戶名 | string |
| videos | 上傳視頻數 | int |
| friends | 朋友數量 | int |
11.3 準備工作
11.3.1 ETL
通過觀察原始數據形式,可以發現,視頻可以有多個所屬分類,每個所屬分類用&符號分割,且分割的兩邊有空格字元,同時相關視頻也是可以有多個元素,多個相關視頻又用“\t”進行分割。為了分析數據時方便對存在多個子元素的數據進行操作,我們首先進行數據重組清洗操作。即:將所有的類別用“&”分割,同時去掉兩邊空格,多個相關視頻id也使用“&”進行分割。
1)ETL之封裝工具類
public class ETLUtil {
/**
* 數據清洗方法
*/
public static String etlData(String srcData){
StringBuffer resultData = new StringBuffer();
//1. 先將數據通過\t 切割
String[] datas = srcData.split("\t");
//2. 判斷長度是否小於9
if(datas.length <9){
return null ;
}
//3. 將數據中的視頻類別的空格去掉
datas[3]=datas[3].replaceAll(" ","");
//4. 將數據中的關聯視頻id通過&拼接
for (int i = 0; i < datas.length; i++) {
if(i < 9){
//4.1 沒有關聯視頻的情況
if(i == datas.length-1){
resultData.append(datas[i]);
}else{
resultData.append(datas[i]).append("\t");
}
}else{
//4.2 有關聯視頻的情況
if(i == datas.length-1){
resultData.append(datas[i]);
}else{
resultData.append(datas[i]).append("&");
}
}
}
return resultData.toString();
}
}
2)ETL之Mapper
/**
* 清洗穀粒影音的原始數據
* 清洗規則
* 1. 將數據長度小於9的清洗掉
* 2. 將數據中的視頻類別中間的空格去掉 People & Blogs
* 3. 將數據中的關聯視頻id通過&符號拼接
*/
public class EtlMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
private Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//獲取一行
String line = value.toString();
//清洗
String resultData = ETLUtil.etlData(line);
if(resultData != null) {
//寫出
k.set(resultData);
context.write(k,NullWritable.get());
}
}
}
3)ETL之Driver
package com.wolffy.gulivideo.etl;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class EtlDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(EtlDriver.class);
job.setMapperClass(EtlMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
job.setNumReduceTasks(0);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.waitForCompletion(true);
}
}
4)將ETL程式打包為etl.jar 並上傳到Linux的 /opt/module/hive/datas 目錄下
5)上傳原始數據到HDFS
[wolffy@hadoop102 datas] pwd
/opt/module/hive/datas
[wolffy@hadoop102 datas] hadoop fs -mkdir -p /gulivideo/video
[wolffy@hadoop102 datas] hadoop fs -mkdir -p /gulivideo/user
[wolffy@hadoop102 datas] hadoop fs -put gulivideo/user/user.txt /gulivideo/user
[wolffy@hadoop102 datas] hadoop fs -put gulivideo/video/*.txt /gulivideo/video
6)ETL數據
[wolffy@hadoop102 datas] hadoop jar etl.jar com.wolffy.hive.etl.EtlDriver /gulivideo/video /gulivideo/video/output
11.3.2 準備表
1)需要準備的表
創建原始數據表:gulivideo_ori,gulivideo_user_ori,
創建最終表:gulivideo_orc,gulivideo_user_orc
2)創建原始數據表:
(1)gulivideo_ori
create table gulivideo_ori(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
row format delimited fields terminated by "\t"
collection items terminated by "&"
stored as textfile;
(2)創建原始數據表: gulivideo_user_ori
ccreate table gulivideo_user_ori(
uploader string,
videos int,
friends int)
row format delimited
fields terminated by "\t"
stored as textfile;
1) 創建orc存儲格式帶snappy壓縮的表:
(1)gulivideo_orc
create table gulivideo_orc(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
stored as orc
tblproperties("orc.compress"="SNAPPY");
(2)gulivideo_user_orc
create table gulivideo_user_orc(
uploader string,
videos int,
friends int)
row format delimited
fields terminated by "\t"
stored as orc
tblproperties("orc.compress"="SNAPPY");
(3)向ori表插入數據
load data inpath "/gulivideo/video/output" into table gulivideo_ori;
load data inpath "/gulivideo/user" into table gulivideo_user_ori;
(4)向orc表插入數據
insert into table gulivideo_orc select * from gulivideo_ori;
insert into table gulivideo_user_orc select * from gulivideo_user_ori;
11.3.3 安裝Tez引擎(瞭解)
Tez是一個Hive的運行引擎,性能優於MR。為什麼優於MR呢?看下。
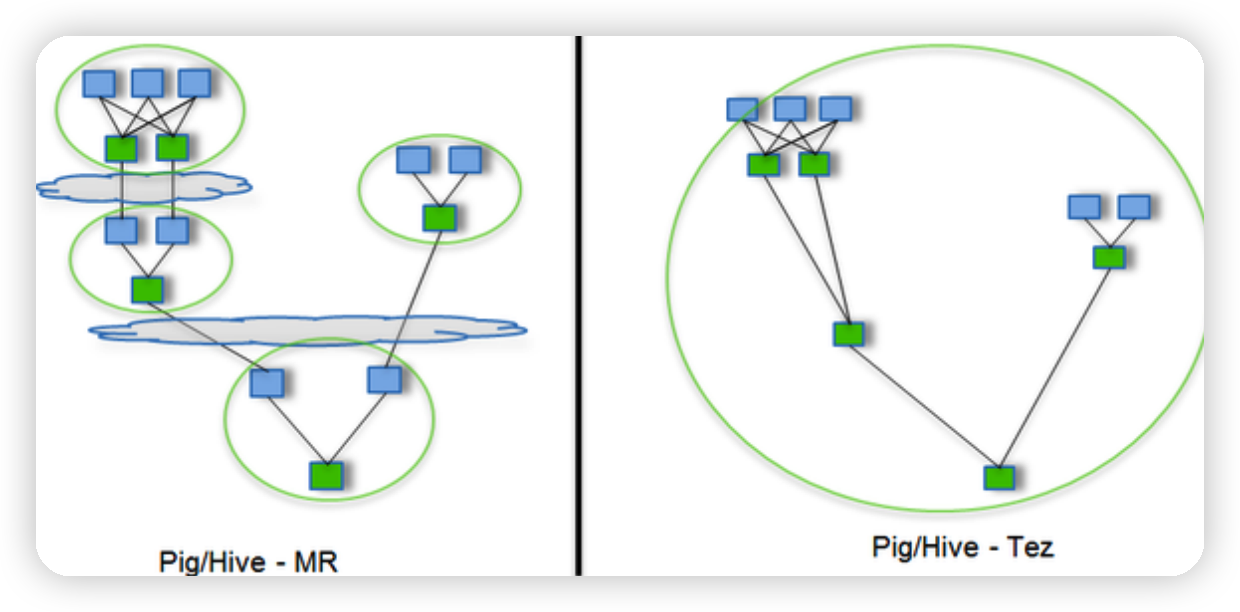
用Hive直接編寫MR程式,假設有四個有依賴關係的MR作業,上圖中,綠色是Reduce Task,雲狀表示寫屏蔽,需要將中間結果持久化寫到HDFS。
Tez可以將多個有依賴的作業轉換為一個作業,這樣只需寫一次HDFS,且中間節點較少,從而大大提升作業的計算性能。
1)將tez安裝包拷貝到集群,並解壓tar包
[wolffy@hadoop102 software]$ mkdir /opt/module/tez
[wolffy@hadoop102 software]$ tar -zxvf /opt/software/tez-0.10.1-SNAPSHOT-minimal.tar.gz -C /opt/module/tez
2)上傳tez依賴到HDFS
[wolffy@hadoop102 software]$ hadoop fs -mkdir /tez
[wolffy@hadoop102 software]$ hadoop fs -put /opt/software/tez-0.10.1-SNAPSHOT.tar.gz /tez
3)新建tez-site.xml
[wolffy@hadoop102 software]$ vim $HADOOP_HOME/etc/hadoop/tez-site.xml
添加如下內容:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/tez/tez-0.10.1-SNAPSHOT.tar.gz</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>tez.am.resource.memory.mb</name>
<value>1024</value>
</property>
<property>
<name>tez.am.resource.cpu.vcores</name>
<value>1</value>
</property>
<property>
<name>tez.container.max.java.heap.fraction</name>
<value>0.4</value>
</property>
<property>
<name>tez.task.resource.memory.mb</name>
<value>1024</value>
</property>
<property>
<name>tez.task.resource.cpu.vcores</name>
<value>1</value>
</property>
</configuration>
4)修改Hadoop環境變數
[wolffy@hadoop102 software]$ vim $HADOOP_HOME/etc/hadoop/shellprofile.d/tez.sh
添加Tez的Jar包相關信息
hadoop_add_profile tez
function _tez_hadoop_classpath
{
hadoop_add_classpath "$HADOOP_HOME/etc/hadoop" after
hadoop_add_classpath "/opt/module/tez/*" after
hadoop_add_classpath "/opt/module/tez/lib/*" after
}
5)修改Hive的計算引擎
[wolffy@hadoop102 software]$ vim $HIVE_HOME/conf/hive-site.xml
添加
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
<property>
<name>hive.tez.container.size</name>
<value>1024</value>
</property>
6)解決日誌Jar包衝突
[wolffy@hadoop102 software]$ rm /opt/module/tez/lib/slf4j-log4j12-1.7.10.jar
11.4 業務分析
11.4.1 統計視頻觀看數Top10
思路:使用order by按照views欄位做一個全局排序即可,同時我們設置只顯示前10條。
最終代碼:
SELECT
videoId,
views
FROM
gulivideo_orc
ORDER BY
views DESC
LIMIT 10;
11.4.2 統計視頻類別熱度Top10
思路:
(1)即統計每個類別有多少個視頻,顯示出包含視頻最多的前10個類別。
(2)我們需要按照類別group by聚合,然後count組內的videoId個數即可。
(3)因為當前表結構為:一個視頻對應一個或多個類別。所以如果要group by類別,需要先將類別進行列轉行(展開),然後再進行count即可。
(4)最後按照熱度排序,顯示前10條。
最終代碼:
SELECT
t1.category_name ,
COUNT(t1.videoId) hot
FROM
(
SELECT
videoId,
category_name
FROM
gulivideo_orc
lateral VIEW explode(category) gulivideo_orc_tmp AS category_name
) t1
GROUP BY
t1.category_name
ORDER BY
hot
DESC
LIMIT 10
11.4.3 統計出視頻觀看數最高的20個視頻的所屬類別以及類別包含Top20視頻的個數
思路:
(1)先找到觀看數最高的20個視頻所屬條目的所有信息,降序排列
(2)把這20條信息中的category分裂出來(列轉行)
(3)最後查詢視頻分類名稱和該分類下有多少個Top20的視頻
最終代碼:
SELECT
t2.category_name,
COUNT(t2.videoId) video_sum
FROM
(
SELECT
t1.videoId,
category_name
FROM
(
SELECT
videoId,
views ,
category
FROM
gulivideo_orc
ORDER BY
views
DESC
LIMIT 20
) t1
lateral VIEW explode(t1.category) t1_tmp AS category_name
) t2
GROUP BY t2.category_name
11.4.4 統計視頻觀看數Top50所關聯視頻的所屬類別排序
代碼:
SELECT
t6.category_name,
t6.video_sum,
rank() over(ORDER BY t6.video_sum DESC ) rk
FROM
(
SELECT
t5.category_name,
COUNT(t5.relatedid_id) video_sum
FROM
(
SELECT
t4.relatedid_id,
category_name
FROM
(
SELECT
t2.relatedid_id ,
t3.category
FROM
(
SELECT
relatedid_id
FROM
(
SELECT
videoId,
views,
relatedid
FROM
gulivideo_orc
ORDER BY
views
DESC
LIMIT 50
)t1
lateral VIEW explode(t1.relatedid) t1_tmp AS relatedid_id
)t2
JOIN
gulivideo_orc t3
ON
t2.relatedid_id = t3.videoId
) t4
lateral VIEW explode(t4.category) t4_tmp AS category_name
) t5
GROUP BY
t5.category_name
ORDER BY
video_sum
DESC
) t6
11.4.5 統計每個類別中的視頻熱度Top10,以Music為例
思路:
(1)要想統計Music類別中的視頻熱度Top10,需要先找到Music類別,那麼就需要將category展開,所以可以創建一張表用於存放categoryId展開的數據。
(2)向category展開的表中插入數據。
(3)統計對應類別(Music)中的視頻熱度。
統計Music類別的Top10(也可以統計其他)
SELECT
t1.videoId,
t1.views,
t1.category_name
FROM
(
SELECT
videoId,
views,
category_name
FROM gulivideo_orc
lateral VIEW explode(category) gulivideo_orc_tmp AS category_name
)t1
WHERE
t1.category_name = "Music"
ORDER BY
t1.views
DESC
LIMIT 10
11.4.6 統計每個類別視頻觀看數Top10
最終代碼:
SELECT
t2.videoId,
t2.views,
t2.category_name,
t2.rk
FROM
(
SELECT
t1.videoId,
t1.views,
t1.category_name,
rank() over(PARTITION BY t1.category_name ORDER BY t1.views DESC ) rk
FROM
(
SELECT
videoId,
views,
category_name
FROM gulivideo_orc
lateral VIEW explode(category) gulivideo_orc_tmp AS category_name
)t1
)t2
WHERE t2.rk <=10
11.4.7 統計上傳視頻最多的用戶Top10以及他們上傳的視頻觀看次數在前20的視頻
思路:
(1)求出上傳視頻最多的10個用戶
(2)關聯gulivideo_orc表,求出這10個用戶上傳的所有的視頻,按照觀看數取前20
最終代碼:
SELECT
t2.videoId,
t2.views,
t2.uploader
FROM
(
SELECT
uploader,
videos
FROM gulivideo_user_orc
ORDER BY
videos
DESC
LIMIT 10
) t1
JOIN gulivideo_orc t2
ON t1.uploader = t2.uploader
ORDER BY
t2.views
DESC
LIMIT 20
IT學習網站
大數據高薪訓練營 完結
鏈接:https://pan.baidu.com/s/1ssRD-BYOiiMw30EV_BLMWQ
提取碼:dghu
失效加V:x923713
QQ交流群 歡迎加入

本文來自博客園,作者:大數據Reasearch,轉載請註明原文鏈接:https://www.cnblogs.com/niuniu2022/p/16354086.html

