
前言 不知道大家在工作無聊時,有沒有一種衝動:總想掏出手機,看看微博熱搜在討論什麼有趣的話題,但又不方便直接打開微博瀏 覽,今天就和大家分享一個有趣的小爬蟲,定時採集微博熱搜榜&熱評,下麵讓我們來看看具體的實現方法。 頁面分析 熱搜頁 熱榜首頁:https://s.weibo.com/top/sum ...
前言
不知道大家在工作無聊時,有沒有一種衝動:總想掏出手機,看看微博熱搜在討論什麼有趣的話題,但又不方便直接打開微博瀏
覽,今天就和大家分享一個有趣的小爬蟲,定時採集微博熱搜榜&熱評,下麵讓我們來看看具體的實現方法。
頁面分析
熱搜頁
熱榜首頁:https://s.weibo.com/top/summary?cate=realtimehot
熱榜首頁的榜單中共五十條數據,在這個頁面,我們需要獲取排行、熱度、標題,以及詳情頁的鏈接。
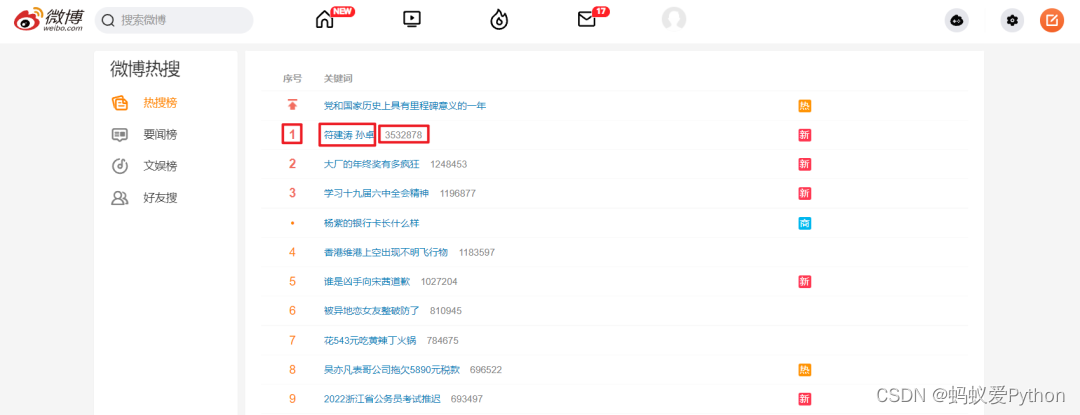
我們打開頁面後要先 登錄,之後使用 F12 打開開發者工具,Ctrl + R 刷新頁面後找到第一條數據包。這裡需要記錄一下自己的
Cookie 與 User-Agent。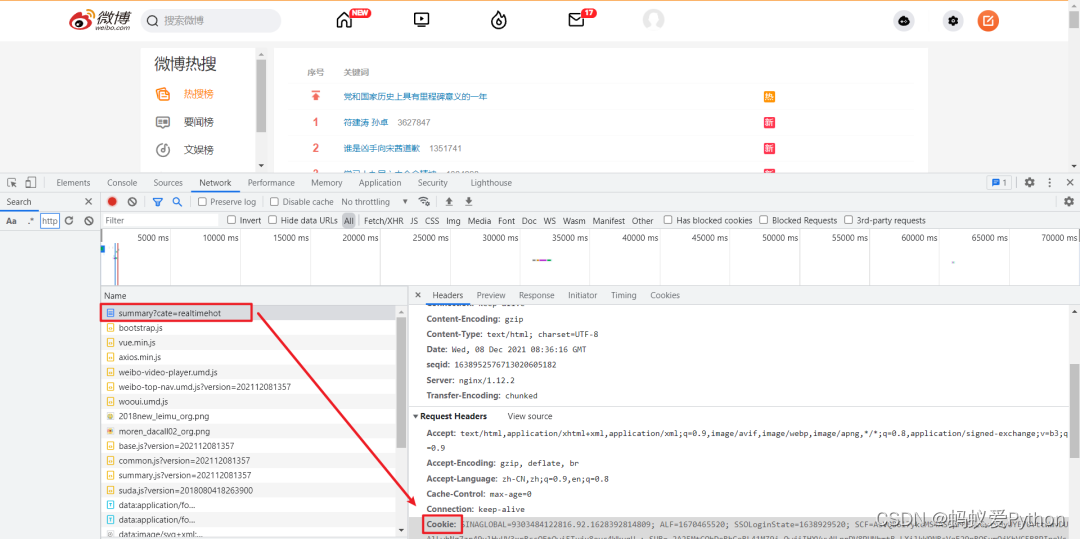
對於標簽的定位,直接使用 Google 工具獲取標簽的 xpath 表達式即可。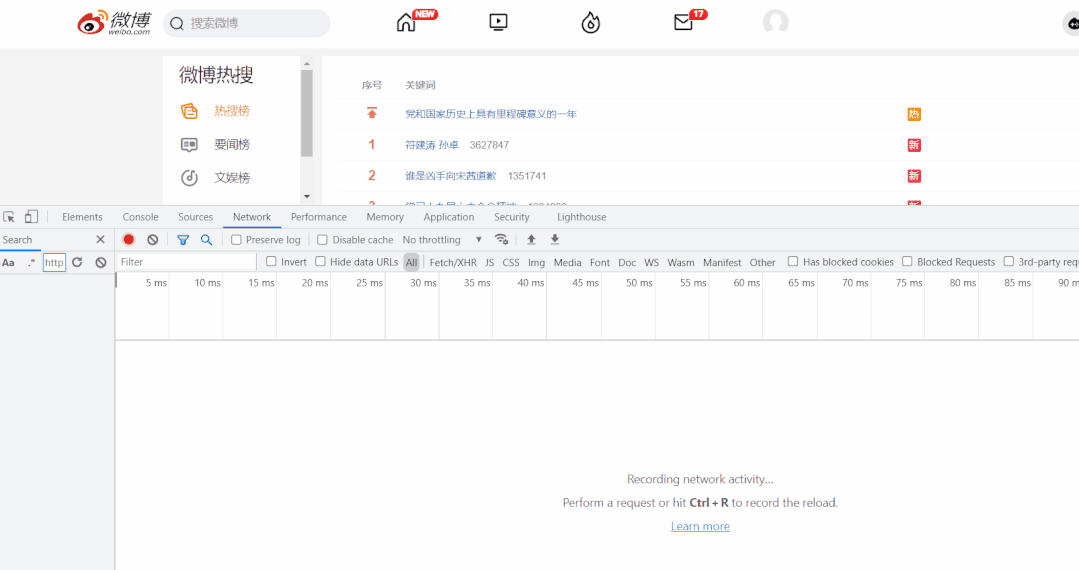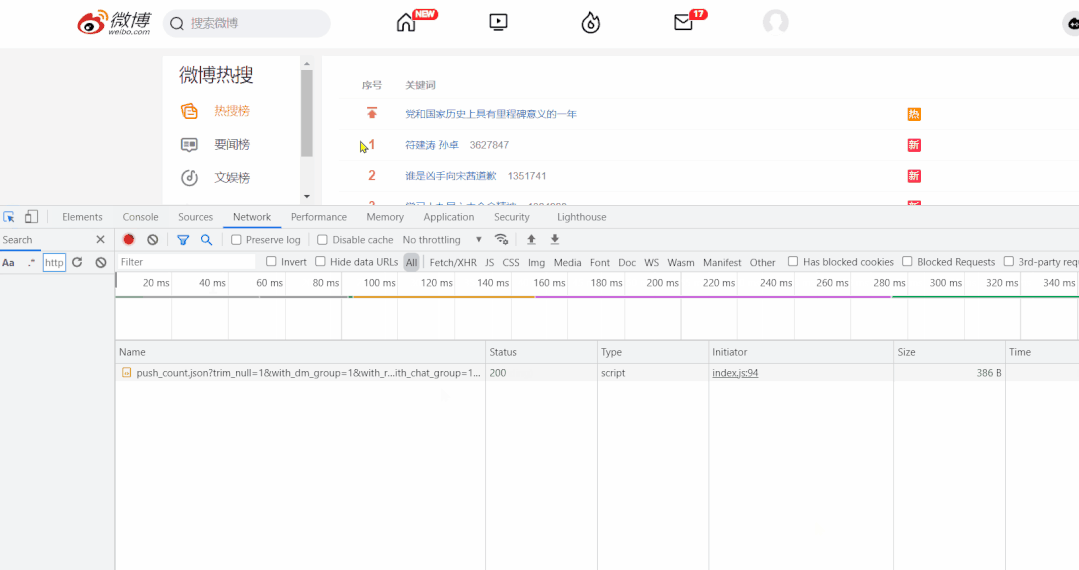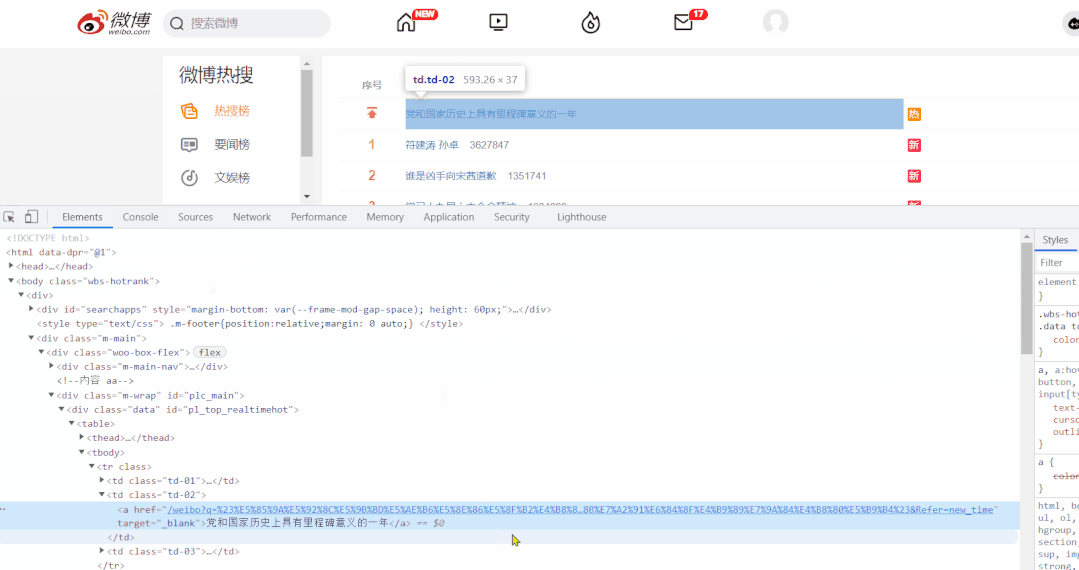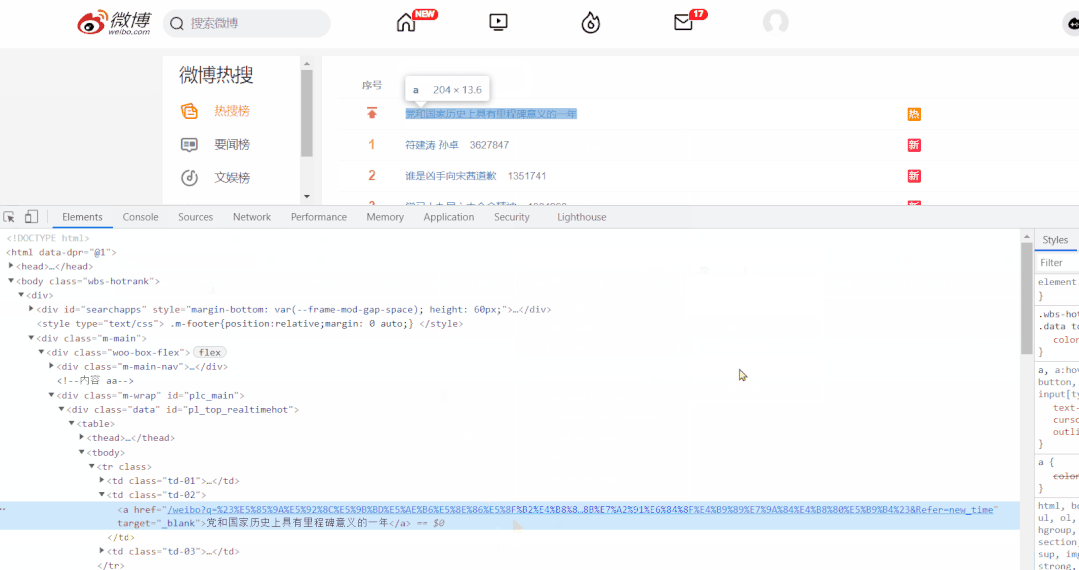
詳情頁
對於詳情頁,我們需要獲取評論時間、用戶名稱、轉發次數、評論次數、點贊次數、評論內容這部分信息。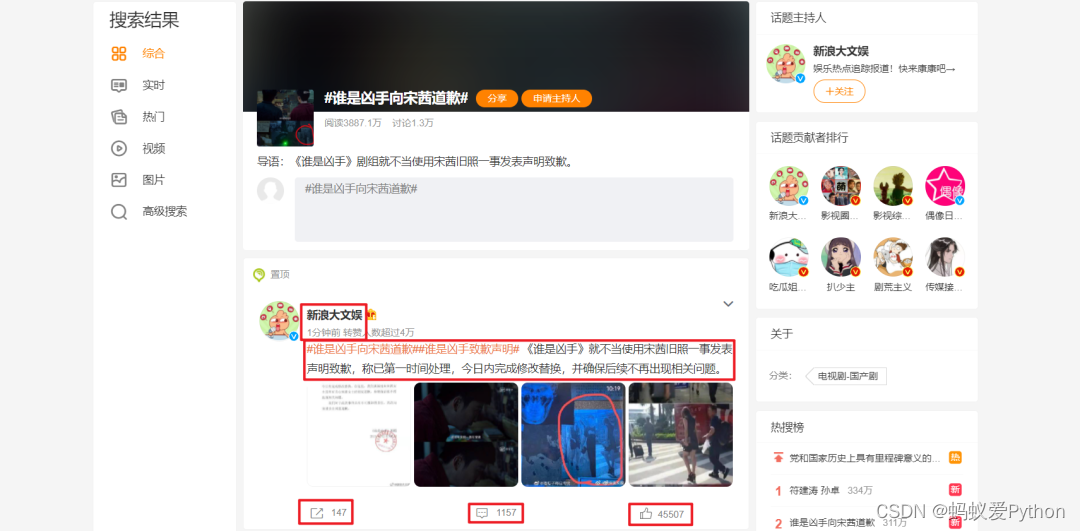
方法與熱搜頁採集方式基本相同,下麵看看如何用代碼實現!
採集代碼
首先導入所需要的模塊。
python插件/素材/源碼加Q群:903971231#### import requests from time import sleep import pandas as pd import numpy as np from lxml import etree import re
定義全局變數。
•headers:請求頭 •all_df:DataFrame,保存採集的數據 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36', 'Cookie': '''你的Cookie''' } all_df = pd.DataFrame(columns=['排行', '熱度', '標題', '評論時間', '用戶名稱', '轉發次數', '評論次數', '點贊次數', '評論內容'])
熱搜榜採集代碼,通過 requests 發起請求,獲取詳情頁鏈接後,跳轉進入詳情頁採集 get_detail_page。
def get_hot_list(url): ''' 微博熱搜頁面採集,獲取詳情頁鏈接後,跳轉進入詳情頁採集 :param url: 微博熱搜頁鏈接 :return: None ''' page_text = requests.get(url=url, headers=headers).text tree = etree.HTML(page_text) tr_list = tree.xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr') for tr in tr_list: parse_url = tr.xpath('./td[2]/a/@href')[0] detail_url = 'https://s.weibo.com' + parse_url title = tr.xpath('./td[2]/a/text()')[0] try: rank = tr.xpath('./td[1]/text()')[0] hot = tr.xpath('./td[2]/span/text()')[0] except: rank = '置頂' hot = '置頂' get_detail_page(detail_url, title, rank, hot)
根據詳情頁鏈接,解析所需頁面數據,並保存到全局變數 all_df 中,對於每個熱搜只採集熱評前三條,熱評不夠則跳過。
def get_detail_page(detail_url, title, rank, hot): ''' 根據詳情頁鏈接,解析所需頁面數據,並保存到全局變數 all_df :param detail_url: 詳情頁鏈接 :param title: 標題 :param rank: 排名 :param hot: 熱度 :return: None ''' global all_df try: page_text = requests.get(url=detail_url, headers=headers).text except: return None tree = etree.HTML(page_text) result_df = pd.DataFrame(columns=np.array(all_df.columns)) # 爬取3條熱門評論信息 for i in range(1, 4): try: comment_time = tree.xpath(f'//*[@id="pl_feedlist_index"]/div[4]/div[{i}]/div[2]/div[1]/div[2]/p[1]/a/text()')[0] comment_time = re.sub('\s','',comment_time) user_name = tree.xpath(f'//*[@id="pl_feedlist_index"]/div[4]/div[{i}]/div[2]/div[1]/div[2]/p[2]/@nick-name')[0] forward_count = tree.xpath(f'//*[@id="pl_feedlist_index"]/div[4]/div[{i}]/div[2]/div[2]/ul/li[1]/a/text()')[1] forward_count = forward_count.strip() comment_count = tree.xpath(f'//*[@id="pl_feedlist_index"]/div[4]/div[{i}]/div[2]/div[2]/ul/li[2]/a/text()')[0] comment_count = comment_count.strip() like_count = tree.xpath(f'//*[@id="pl_feedlist_index"]/div[4]/div[{i}]/div[2]/div[2]/ul/li[3]/a/button/span[2]/text()')[0] comment = tree.xpath(f'//*[@id="pl_feedlist_index"]/div[4]/div[{i}]/div[2]/div[1]/div[2]/p[2]//text()') comment = ' '.join(comment).strip() result_df.loc[len(result_df), :] = [rank, hot, title, comment_time, user_name, forward_count, comment_count, like_count, comment] except Exception as e: print(e) continue print(detail_url, title) all_df = all_df.append(result_df, ignore_index=True)
調度代碼,向 get_hot_list 中傳入熱搜頁的 url ,最後進行保存即可。
if __name__ == '__main__': url = 'https://s.weibo.com/top/summary?cate=realtimehot' get_hot_list(url) all_df.to_excel('工作文檔.xlsx', index=False) python插件/素材/源碼Q群:903971231####
對於採集過程中對於一些可能發生報錯的地方,為保證程式的正常運行,都通過異常處理給忽略掉了,整體影響不大!
工作文檔.xlsx
設置定時運行
至此,採集代碼已經完成,想要實現每小時自動運行代碼,可以使用「任務計劃程式」。
在此之前需要我們簡單修改一下上面代碼中的Cookie與最後文件的保存路徑(建議使用絕對路徑),如果在 Jupyter notebook 中運行的需要導出一個 .py 文件
打開任務計劃程式,【創建任務】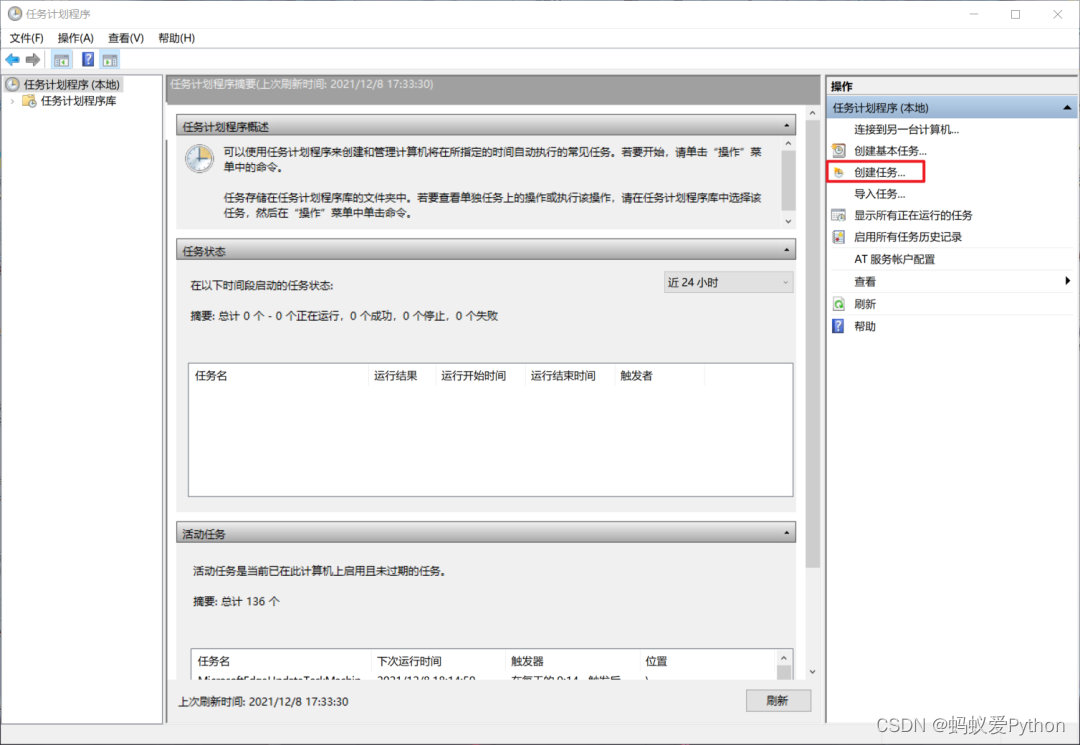
輸入名稱,名稱隨便起就好。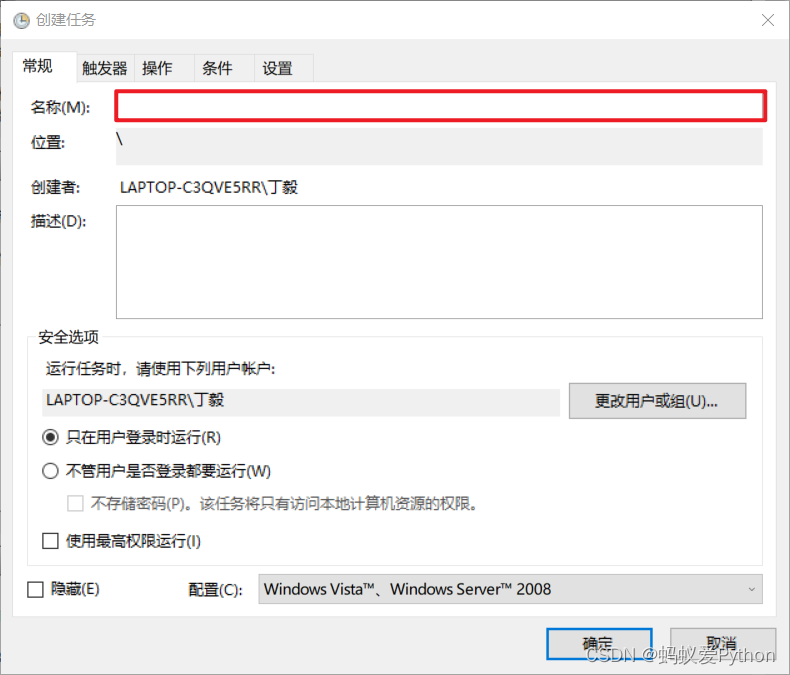
選擇【觸發器】>>【新建】>>【設置觸發時間】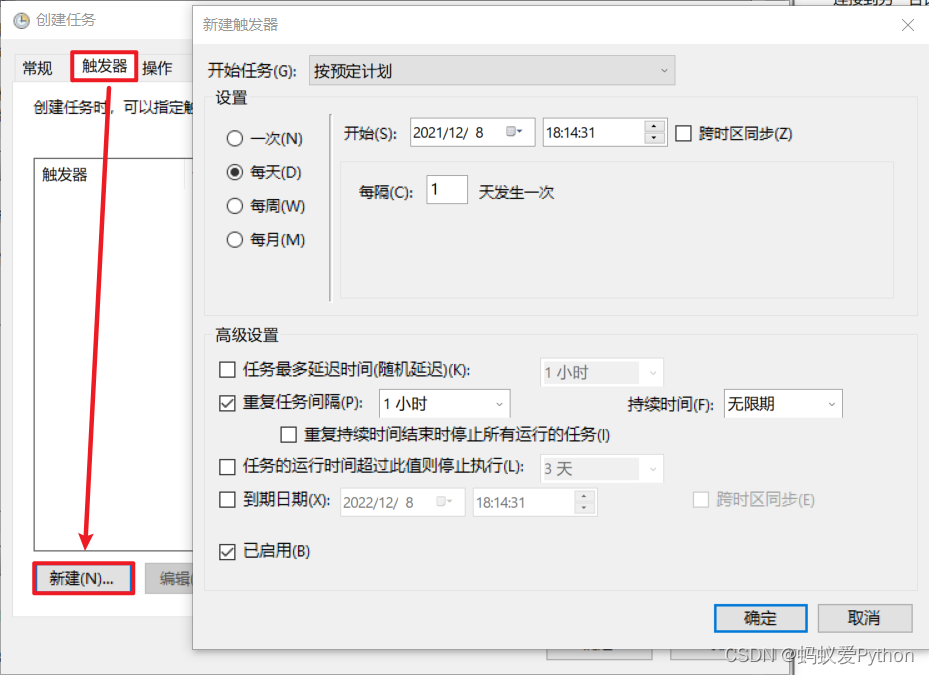
選擇【操作】>>【新建】>>【選擇程式】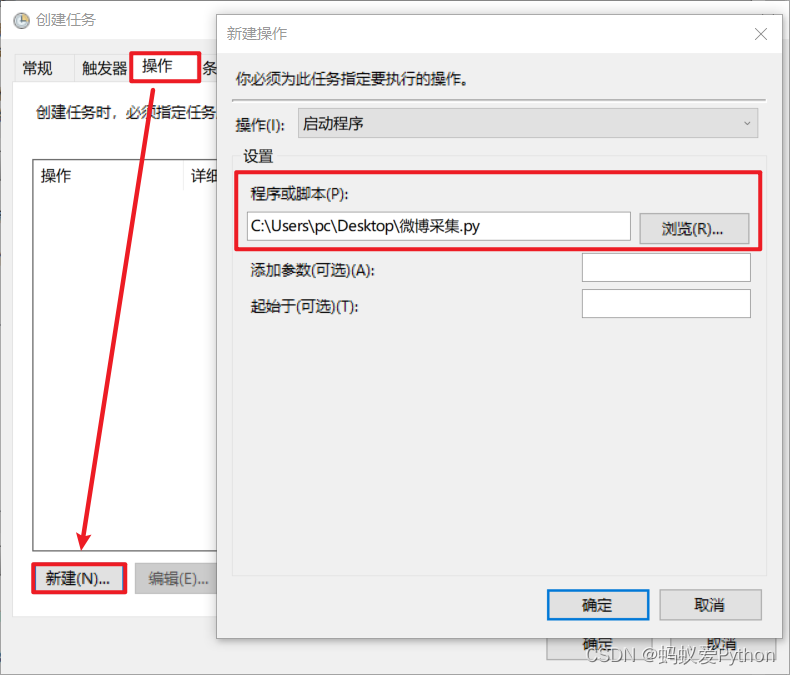
最後確認即可。到時間就會自動運行,或者右鍵任務手動運行。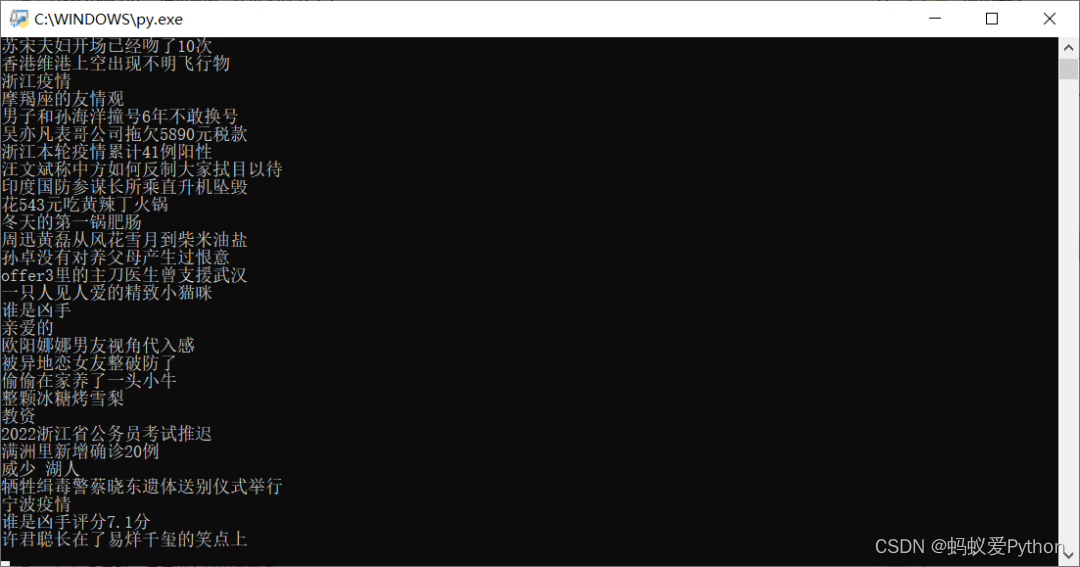
「運行效果」
這就是今天要分享的內容,整體難度不大,希望大家能夠有所收穫,文章中的代碼拼接起來就可以運行,如果有什麼問題可以聯
系我哦!


