
一、微服務網關概述 如下圖: 不同的微服務一般會有不同的網路地址,客戶端在訪問這些微服務時必須記住幾十甚至幾百個地址,這對於客戶端方來說太複雜也難以維護。如果讓客戶端直接與各個微服務通訊,可能會有很多問題: 客戶端會請求多個不同的服務,需要維護不同的請求地址,增加開發難度 在某些場景下存在跨域請求的 ...
一、微服務網關概述
如下圖:
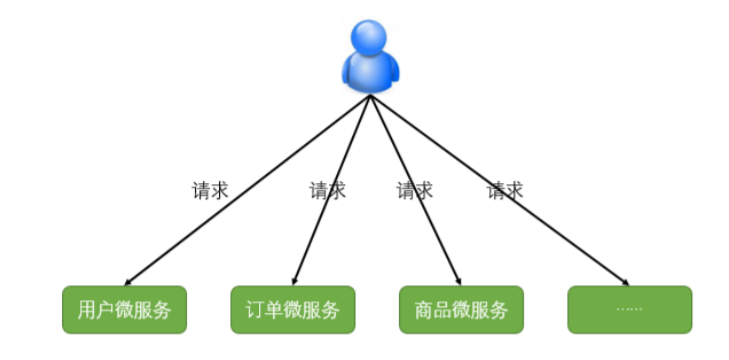
不同的微服務一般會有不同的網路地址,客戶端在訪問這些微服務時必須記住幾十甚至幾百個地址,這對於客戶端方來說太複雜也難以維護。如果讓客戶端直接與各個微服務通訊,可能會有很多問題: 客戶端會請求多個不同的服務,需要維護不同的請求地址,增加開發難度 在某些場景下存在跨域請求的問題 加大身份認證的難度,每個微服務需要獨立認證。因此,我們需要一個微服務網關,介於客戶端與伺服器之間的中間層,所有的外部請求都會先經過微服務網關。客戶端只需要與網關交互,只知道一個網關地址即可,這樣簡化了開發,還有以下優點: 1、易於監控 2、易於認證 3、減少了客戶端與各個微服務之間的交互次數。
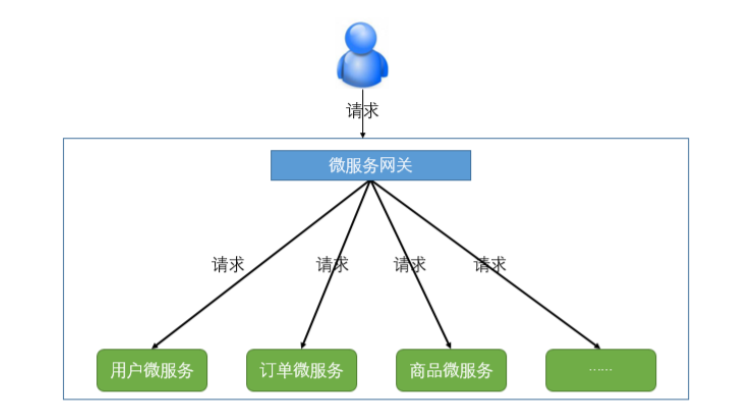
1、服務網關的概念
API網關是一個伺服器,是系統對外的唯一入口。API網關封裝了系統內部架構,為每個客戶端提供 一個定製的API。API網關方式的核心要點是,所有的客戶端和消費端都通過統一的網關接入微服務,在 網關層處理所有的非業務功能。通常,網關也是提供REST/HTTP的訪問API。服務端通過API-GW註冊和 管理服務。
2、作用和應用場景
網關具有的職責,如身份驗證、監控、負載均衡、緩存、請求分片與管理、靜態響應處理。當然,最主要的職責還是與“外界聯繫”。
3、常見的API網關實現方式
Kong
基於Nginx+Lua開發,性能高,穩定,有多個可用的插件(限流、鑒權等等)可以開箱即用。 問題:只支持Http協議;二次開發,自由擴展困難;提供管理API,缺乏更易用的管控、配置方 式。
Zuul
Netflix開源,功能豐富,使用JAVA開發,易於二次開發;需要運行在web容器中,如Tomcat。 問題:缺乏管控,無法動態配置;依賴組件較多;處理Http請求依賴的是Web容器,性能不如 Nginx;
Traefik
Go語言開發;輕量易用;提供大多數的功能:服務路由,負載均衡等等;提供WebUI 問題:二進位文件部署,二次開發難度大;UI更多的是監控,缺乏配置、管理能力;
Spring Cloud Gateway
SpringCloud提供的網關服務 Nginx+lua實現 使用Nginx的反向代理和負載均衡可實現對api伺服器的負載均衡及高可用 問題:自註冊的問題和網關本身的擴展性
4、基於Nginx的網關實現
(1) Nginx介紹

(2) Nginx反向代理
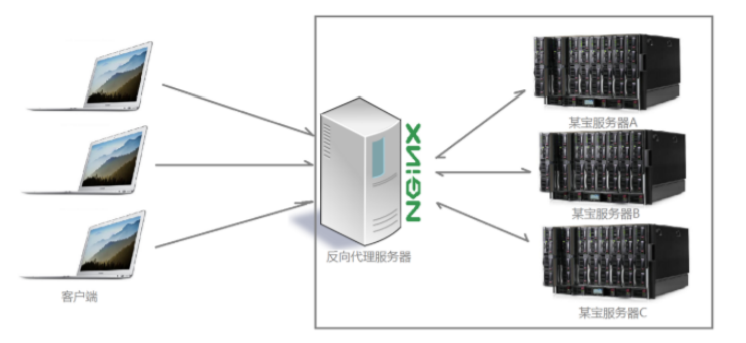
多個客戶端給伺服器發送的請求,Nginx伺服器接收到之後,按照一定的規則分發給了後端的業務處理伺服器進行處理了。此時~請求的來源也就是客戶端是明確的,但是請求具體由哪台伺服器處理的並不明確了,Nginx扮演的就是一個反向代理角色。客戶端是無感知代理的存在的,反向代理對外都是透明的,訪問者並不知道自己訪問的是一個代理。因為客戶端不需要任何配置就可以訪問。反向代理,"它代理的是服務端,代服務端接收請求",主要用於伺服器集群分散式部署的情況下,反向代理隱藏了伺服器的信息,如果只是單純的需要一個最基礎的具備轉發功能的網關,那麼使用Ngnix是一個不錯的選擇。
5、 微服務網關Zuul
(1)Zuul簡介
Zuul是Netflix開源的微服務網關,它可以和Eureka、Ribbon、Hystrix等組件配合使用,Zuul組件的核心是一系列的過濾器,這些過濾器可以完成以下功能:
動態路由:動態將請求路由到不同後端
集群壓力測試:逐漸增加指向集群的流量,以瞭解性能
負載分配:為每一種負載類型分配對應容量,並棄用超出限定值的請求
靜態響應處理:邊緣位置進行響應,避免轉發到內部集群
身份認證和安全: 識別每一個資源的驗證要求,並拒絕那些不符的請求。
Spring Cloud對Zuul進行了整合和增強。
(2)搭建Zuul網關伺服器
1)創建工程導入依賴
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-zuul</artifactId> <version>2.1.0.RELEASE</version> </dependency>
2)編寫啟動類
@SpringBootApplication @EnableZuulProxy // 開啟Zuul的網關功能 public class ZuulServerApplication { public static void main(String[] args) { SpringApplication.run(ZuulServerApplication.class, args); } }
@EnableZuulProxy : 通過 @EnableZuulProxy 註解開啟Zuul網管功能
3)編寫配置
創建配置文件 application.yml ,並添加相應配置
server:
port: 8080 #服務埠
spring:
application:
name: api-gateway #指定服務名
(3)Zuul中的路由轉發
“路由”是指根據請求URL,將請求分配到對應的處理程式。在微服務體系中,Zuul負責接收所有的請求。根據不同的URL匹配規則,將不同的請求轉發到不同的微服務處理。
zuul:
routes:
product-service: # 這裡是路由id,隨意寫
path: /product-service/** # 這裡是映射路徑
url: http://127.0.0.1:9002 # 映射路徑對應的實際url地址
sensitiveHeaders: #預設zuul會屏蔽cookie,cookie不會傳到下游服務,這裡設置為空則取
消預設的黑名單,如果設置了具體的頭信息則不會傳到下游服務
只需要在application.yml文件中配置路由規則即可:
product-service:配置路由id,可以隨意取名 u
rl:映射路徑對應的實際url地址
path:配置映射路徑,這裡將所有請求首碼為/product-service/的請求,轉發到http://127.0.0.1: 9002處理 配置好Zuul路由之後啟動服務。
(4)面向服務的路由
微服務一般是由幾十、上百個服務組成,對於一個URL請求,最終會確認一個服務實例進行處理。如果對每個服務實例手動指定一個唯一訪問地址,然後根據URL去手動實現請求匹配,這樣做顯然就不合理。 Zuul支持與Eureka整合開發,根據ServiceID自動的從註冊中心中獲取服務地址並轉發請求,這樣做的好處不僅可以通過單個端點來訪問應用的所有服務,而且在添加或移除服務實例的時候不用修改Zuul的 路由配置。
1)添加Eureka客戶端依賴
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> </dependency>
2)開啟Eureka客戶端發現功能
@SpringBootApplication @EnableZuulProxy // 開啟Zuul的網關功能 @EnableDiscoveryClient public class ZuulServerApplication { public static void main(String[] args) { SpringApplication.run(ZuulServerApplication.class, args); } }
3)添加Eureka配置,獲取服務信息
eureka: client: serviceUrl: defaultZone: http://127.0.0.1:8761/eureka/ registry-fetch-interval-seconds: 5 # 獲取服務列表的周期:5s instance: preferIpAddress: true ip-address: 127.0.0.1
4)修改映射配置,通過服務名稱獲取
因為已經有了Eureka客戶端,我們可以從Eureka獲取服務的地址信息,因此映射時無需指定IP地址,而是通過服務名稱來訪問,而且Zuul已經集成了Ribbon的負載均衡功能。
#配置路由規則
zuul:
routes:
product-service: # 這裡是路由id,隨意寫
path: /product-service/** # 這裡是映射路徑
serviceId: shop-service-product #配置轉發的微服務名稱
serviceId: 指定需要轉發的微服務實例名稱
(5)Zuul加入後的架構

(6)Zuul中的過濾器
Zuul它包含了兩個核心功能:對請求的路由和過濾。其中路由功能負責將外部請求轉發到具體的微服務實例上,是實現外部訪問統一入口的基礎;而過濾器功能則負責對請求的處理過程進行干預,是實現請求校驗、服務聚合等功能的基礎。其實,路由功能在真正運行時,它的路由映射和請求轉發同樣也由幾個不同的過濾器完成的。所以,過濾器可以說是Zuul實現API網關功能最為核心的部件,每一個進入Zuul的HTTP請求都會經過一系列的過濾器處理鏈得到請求響應並返回給客戶端。
1)ZuulFilter簡介
Zuul 中的過濾器跟我們之前使用的 javax.servlet.Filter 不一樣,javax.servlet.Filter 只有一種類型,可以通過配置 urlPatterns 來攔截對應的請求。而 Zuul 中的過濾器總共有 4 種類型,且每種類型都有對 應的使用場景。
1. PRE:這種過濾器在請求被路由之前調用。我們可利用這種過濾器實現身份驗證、在集群中選擇請 求的微服務、記錄調試信息等。
2. ROUTING:這種過濾器將請求路由到微服務。這種過濾器用於構建發送給微服務的請求,並使用 Apache HttpClient或Netfilx Ribbon請求微服務。
3. POST:這種過濾器在路由到微服務以後執行。這種過濾器可用來為響應添加標準的HTTP Header、收集統計信息和指標、將響應從微服務發送給客戶端等。
4. ERROR:在其他階段發生錯誤時執行該過濾器。
Zuul提供了自定義過濾器的功能實現起來也十分簡單,只需要編寫一個類去實現zuul提供的介面
public abstract ZuulFilter implements IZuulFilter{ abstract public String filterType(); abstract public int filterOrder(); boolean shouldFilter();// 來自IZuulFilter Object run() throws ZuulException;// IZuulFilter }
ZuulFilter是過濾器的頂級父類。在這裡我們看一下其中定義的4個最重要的方法
shouldFilter :返回一個 Boolean 值,判斷該過濾器是否需要執行。返回true執行,返回false 不執行。
run :過濾器的具體業務邏輯。
filterType :返回字元串,代表過濾器的類型。包含以下4種:
pre :請求在被路由之前執行
routing :在路由請求時調用
post :在routing和errror過濾器之後調用
error :處理請求時發生錯誤調用
filterOrder :通過返回的int值來定義過濾器的執行順序,數字越小優先順序越高。
(7) 生命周期
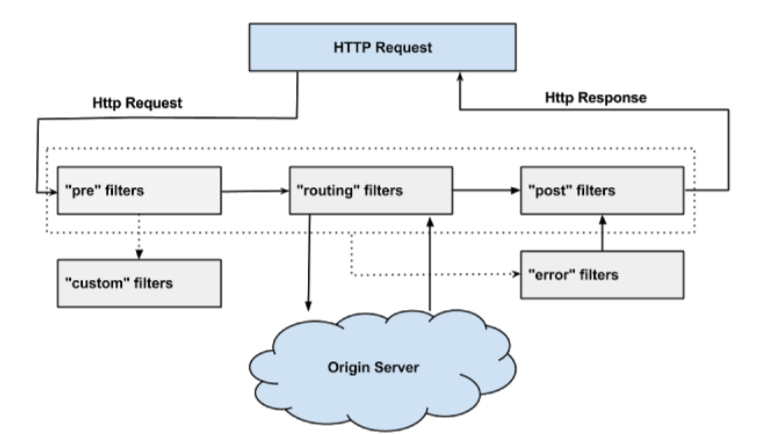
正常流程: 請求到達首先會經過pre類型過濾器,而後到達routing類型,進行路由,請求就到達真正的 服務提供者,執行請求,返回結果後,會到達post過濾器。而後返迴響應。 異常流程: 整個過程中,pre或者routing過濾器出現異常,都會直接進入error過濾器,再error處理完畢 後,會將請求交給POST過濾器,最後返回給用戶。 如果是error過濾器自己出現異常,最終也會進入POST過濾器,而後返回。 如果是POST過濾器出現異常,會跳轉到error過濾器,但是與pre和routing不同的時,請求不會再到達POST過濾器了。 不同過濾器的場景: 請求鑒權:一般放在pre類型,如果發現沒有訪問許可權,直接就攔截了 異常處理:一般會在error類型和post類型過濾器中結合來處理。 服務調用時長統計:pre和post結合使用。
(8)Zuul網關存在的問題
在實際使用中我們會發現直接使用Zuul會存在諸多問題,包括: 性能問題 Zuul1x版本本質上就是一個同步Servlet,採用多線程阻塞模型進行請求轉發。簡單講,每來 一個請求,Servlet容器要為該請求分配一個線程專門負責處理這個請求,直到響應返回客戶 端這個線程才會被釋放返回容器線程池。如果後臺服務調用比較耗時,那麼這個線程就會被阻塞,阻塞期間線程資源被占用,不能幹其它事情。我們知道Servlet容器線程池的大小是有限制的,當前端請求量大,而後臺慢服務比較多時,很容易耗盡容器線程池內的線程,造成容器無法接受新的請求。 不支持任何長連接,如websocket
(9) Zuul網關的替換方案
Zuul2.x版本 SpringCloud Gateway
5 、微服務網關GateWay
Zuul 1.x 是一個基於阻塞 IO 的 API Gateway 以及 Servlet;直到 2018 年 5 月,Zuul 2.x(基於 Netty,也是非阻塞的,支持長連接)才發佈,但 Spring Cloud 暫時還沒有整合計劃。Spring Cloud Gateway 比 Zuul 1.x 系列的性能和功能整體要好。
(1)Gateway簡介
Spring Cloud Gateway 是 Spring 官方基於 Spring 5.0,Spring Boot 2.0 和 Project Reactor 等技術開發的網關,旨在為微服務架構提供一種簡單而有效的統一的 API 路由管理方式,統一訪問介面。Spring Cloud Gateway 作為 Spring Cloud 生態系中的網關,目標是替代 Netflix ZUUL,其不僅提供統一的路 由方式,並且基於 Filter 鏈的方式提供了網關基本的功能,例如:安全,監控/埋點,和限流等。它是基 於Nttey的響應式開發模式。

上表為Spring Cloud Gateway與Zuul的性能對比,從結果可知,Spring Cloud Gateway的RPS是Zuul 的1.6倍
(2)核心概念
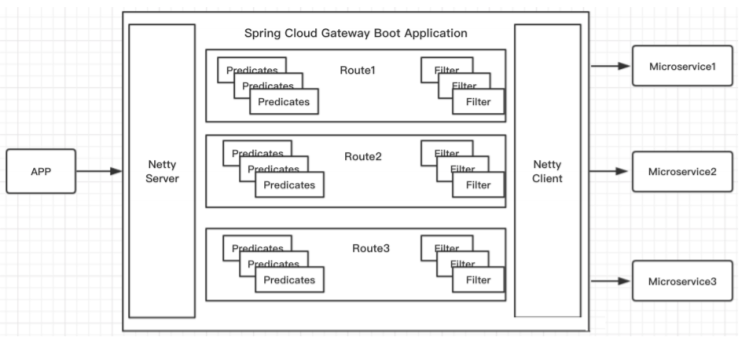
1. 路由(route) 路由是網關最基礎的部分,路由信息由一個ID、一個目的URL、一組斷言工廠和一 組Filter組成。如果斷言為真,則說明請求URL和配置的路由匹配。
2. 斷言(predicates) Java8中的斷言函數,Spring Cloud Gateway中的斷言函數輸入類型是 Spring5.0框架中的ServerWebExchange。Spring Cloud Gateway中的斷言函數允許開發者去定 義匹配來自Http Request中的任何信息,比如請求頭和參數等。
3. 過濾器(filter) 一個標準的Spring webFilter,Spring Cloud Gateway中的Filter分為兩種類型, 分別是Gateway Filter和Global Filter。過濾器Filter可以對請求和響應進行處理。
(3) 入門案例
1) 創建工程導入依賴
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId> </dependency>
註意SpringCloud Gateway使用的web框架為webflux,和SpringMVC不相容。引入的限流組件是 hystrix。redis底層不再使用jedis,而是lettuce。
2) 配置啟動類
@SpringBootApplication public class GatewayServerApplication { public static void main(String[] args) { SpringApplication.run(GatewayServerApplication.class, args); } }
3) 編寫配置文件
創建 application.yml 配置文件
server:
port: 8080 #服務埠
spring:
application:
name: api-gateway #指定服務名
cloud:
gateway:
routes:
- id: product-service
uri: http://127.0.0.1:9002
predicates:
- Path=/product/**
id:我們自定義的路由 ID,保持唯一
uri:目標服務地址
predicates:路由條件,Predicate 接受一個輸入參數,返回一個布爾值結果。
該介面包含多種默 認方法來將 Predicate 組合成其他複雜的邏輯(比如:與,或,非)。 filters:過濾規則,暫時沒用。
(4)路由規則
Spring Cloud Gateway 的功能很強大,前面我們只是使用了 predicates 進行了簡單的條件匹配,其實 Spring Cloud Gataway 幫我們內置了很多 Predicates 功能。在 Spring Cloud Gateway 中 Spring 利用 Predicate 的特性實現了各種路由匹配規則,有通過 Header、請求參數等不同的條件來進行作為條件匹配到對應的路由。
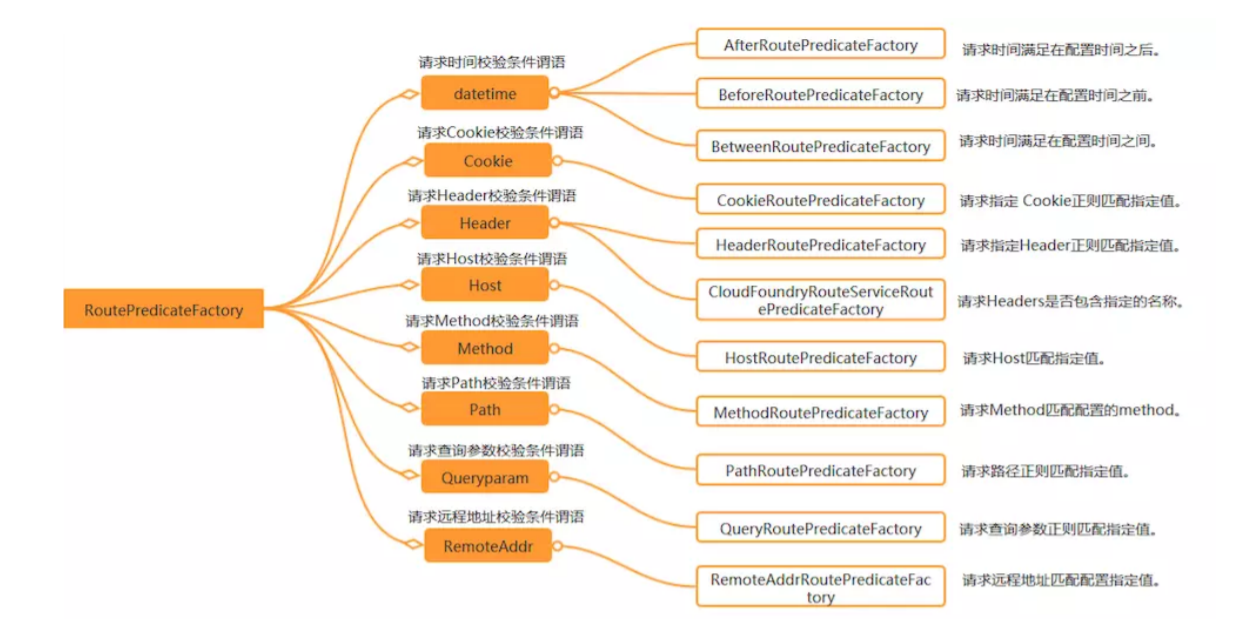
eg:
#路由斷言之後匹配
spring:
cloud:
gateway:
routes:
- id: after_route
uri: https://xxxx.com
#路由斷言之前匹配
predicates:
- After=xxxxx
#路由斷言之前匹配
spring:
cloud:
gateway:
routes:
- id: before_route
uri: https://xxxxxx.com
predicates:
- Before=xxxxxxx
#路由斷言之間
spring:
cloud:
gateway:
routes:
- id: between_route
uri: https://xxxx.com
predicates:
- Between=xxxx,xxxx
#路由斷言Cookie匹配,此predicate匹配給定名稱(chocolate)和正則表達式(ch.p)
spring:
cloud:
gateway:
routes:
- id: cookie_route
uri: https://xxxx.com
predicates:
- Cookie=chocolate, ch.p
#路由斷言Header匹配,header名稱匹配X-Request-Id,且正則表達式匹配\d+
spring:
cloud:
gateway:
routes:
- id: header_route
uri: https://xxxx.com
predicates:
- Header=X-Request-Id, \d+
#路由斷言匹配Host匹配,匹配下麵Host主機列表,**代表可變參數
spring:
cloud:
gateway:
routes:
- id: host_route
uri: https://xxxx.com
predicates:
- Host=**.somehost.org,**.anotherhost.org
#路由斷言Method匹配,匹配的是請求的HTTP方法
spring:
cloud:
gateway:
routes:
- id: method_route
uri: https://xxxx.com
predicates:
- Method=GET
#路由斷言匹配,{segment}為可變參數
spring:
cloud:
gateway:
routes:
- id: host_route
uri: https://xxxx.com
predicates:
- Path=/foo/{segment},/bar/{segment}
#路由斷言Query匹配,將請求的參數param(baz)進行匹配,也可以進行regexp正則表達式匹配 (參數包含
foo,並且foo的值匹配ba.)
spring:
cloud:
gateway:
routes:
- id: query_route
uri: https://xxxx.com
predicates:
- Query=baz 或 Query=foo,ba.
#路由斷言RemoteAddr匹配,將匹配192.168.1.1~192.168.1.254之間的ip地址,其中24為子網掩碼位
數即255.255.255.0
spring:
cloud:
gateway:
routes:
- id: remoteaddr_route
uri: https://example.org
predicates:
- RemoteAddr=192.168.1.1/24
(5)過濾器
Spring Cloud Gateway除了具備請求路由功能之外,也支持對請求的過濾。通過Zuul網關類似,也是通 過過濾器的形式來實現的。那麼接下來我們一起來研究一下Gateway中的過濾器
(6)過濾器基礎
1) 過濾器的生命周期
Spring Cloud Gateway 的 Filter 的生命周期不像 Zuul 的那麼豐富,它只有兩個:“pre” 和 “post”。
PRE: 這種過濾器在請求被路由之前調用。我們可利用這種過濾器實現身份驗證、在集群中選擇 請求的微服務、記錄調試信息等。
POST:這種過濾器在路由到微服務以後執行。這種過濾器可用來為響應添加標準的 HTTP Header、收集統計信息和指標、將響應從微服務發送給客戶端等。
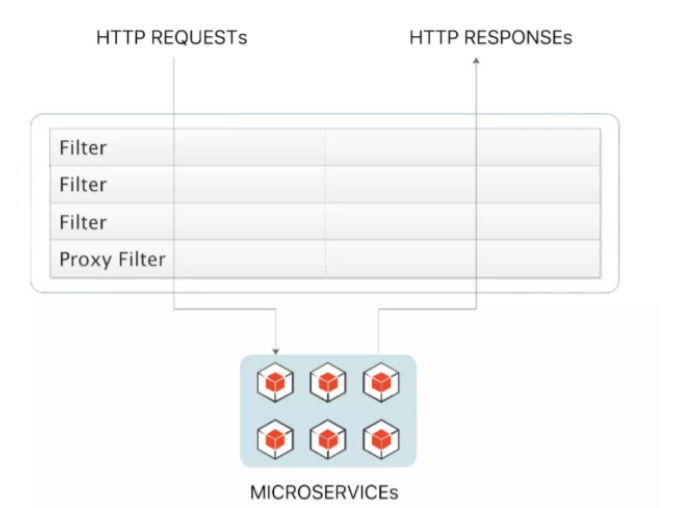
2) 過濾器類型 Spring Cloud Gateway 的 Filter 從作用範圍可分為另外兩種GatewayFilter 與 GlobalFilter。
GatewayFilter:應用到單個路由或者一個分組的路由上。
GlobalFilter:應用到所有的路由上。
(7) 局部過濾器
局部過濾器(GatewayFilter),是針對單個路由的過濾器。可以對訪問的URL過濾,進行切麵處理。在 Spring Cloud Gateway中通過GatewayFilter的形式內置了很多不同類型的局部過濾器。這裡簡單將 Spring Cloud Gateway內置的所有過濾器工廠整理成了一張表格,雖然不是很詳細,但能作為速覽使 用。如下:
每個過濾器工廠都對應一個實現類,並且這些類的名稱必須以 GatewayFilterFactory 結尾,這是 Spring Cloud Gateway的一個約定,例如 AddRequestHeader 對應的實現類為 AddRequestHeaderGatewayFilterFactory 。對於這些過濾器的使用方式可以參考官方文檔
(8)全局過濾器
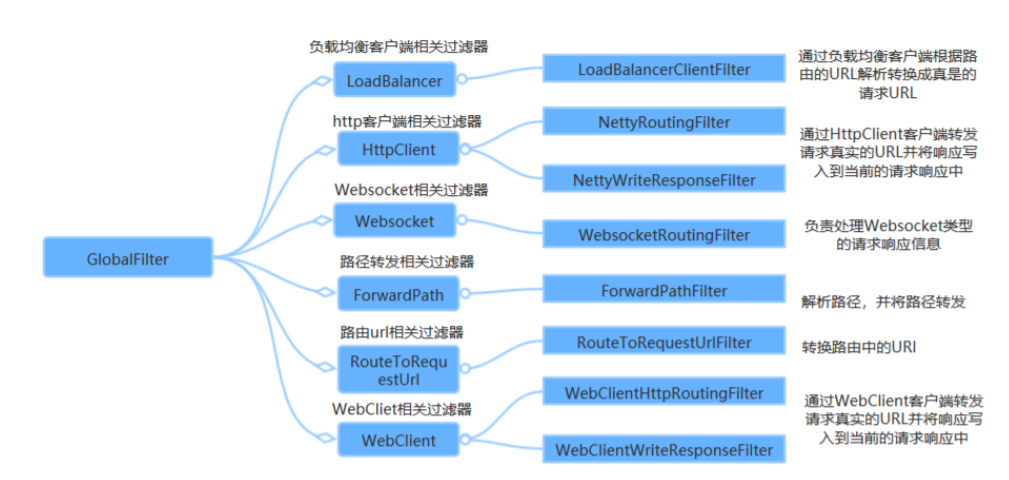
全局過濾器(GlobalFilter)作用於所有路由,Spring Cloud Gateway 定義了Global Filter介面,用戶 可以自定義實現自己的Global Filter。通過全局過濾器可以實現對許可權的統一校驗,安全性驗證等功 能,並且全局過濾器也是程式員使用比較多的過濾器。 Spring Cloud Gateway內部也是通過一系列的內置全局過濾器對整個路由轉發進行處理如下:
(9)統一鑒權
內置的過濾器已經可以完成大部分的功能,但是對於企業開發的一些業務功能處理,還是需要我們自己 編寫過濾器來實現的,那麼我們一起通過代碼的形式自定義一個過濾器,去完成統一的許可權校驗。
(10) 鑒權邏輯
開發中的鑒權邏輯: 當客戶端第一次請求服務時,服務端對用戶進行信息認證(登錄) 認證通過,將用戶信息進行加密形成token,返回給客戶端,作為登錄憑證 以後每次請求,客戶端都攜帶認證的token 服務端對token進行解密,判斷是否有效。
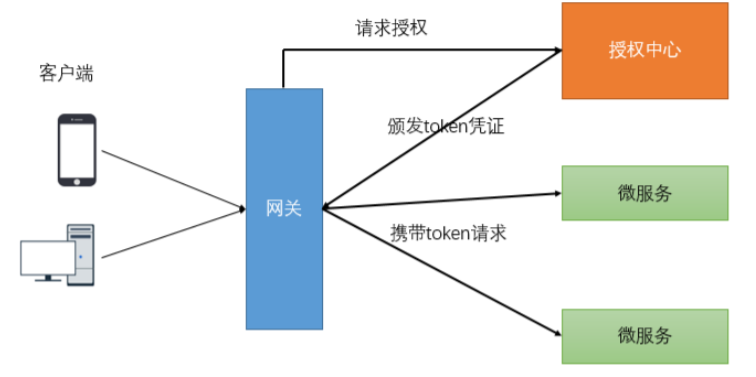
如上圖,對於驗證用戶是否已經登錄鑒權的過程可以在網關層統一檢驗。檢驗的標準就是請求中是否攜 帶token憑證以及token的正確性。
(11)網關限流
常見的限流演算法
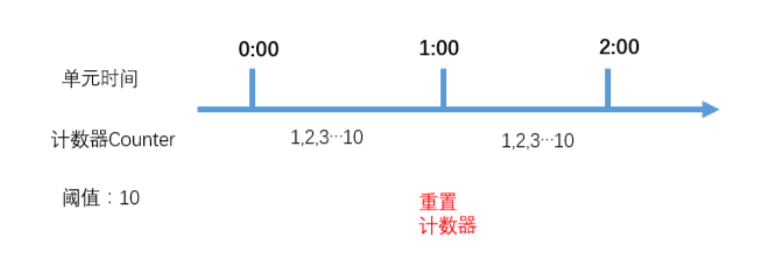
1) 計數器 計數器限流演算法是最簡單的一種限流實現方式。其本質是通過維護一個單位時間內的計數器,每次請求 計數器加1,當單位時間內計數器累加到大於設定的閾值,則之後的請求都被拒絕,直到單位時間已經 過去,再將計數器重置為零
2) 漏桶演算法
漏桶演算法可以很好地限制容量池的大小,從而防止流量暴增。漏桶可以看作是一個帶有常量服務時間的 單伺服器隊列,如果漏桶(包緩存)溢出,那麼數據包會被丟棄。 在網路中,漏桶演算法可以控制埠的 流量輸出速率,平滑網路上的突發流量,實現流量整形,從而為網路提供一個穩定的流量。

為了更好的控制流量,漏桶演算法需要通過兩個變數進行控制:一個是桶的大小,支持流量突發增多時可 以存多少的水(burst),另一個是水桶漏洞的大小(rate)。
3) 令牌桶演算法
令牌桶演算法是對漏桶演算法的一種改進,桶演算法能夠限制請求調用的速率,而令牌桶演算法能夠在限制調用 的平均速率的同時還允許一定程度的突發調用。在令牌桶演算法中,存在一個桶,用來存放固定數量的令 牌。演算法中存在一種機制,以一定的速率往桶中放令牌。每次請求調用需要先獲取令牌,只有拿到令 牌,才有機會繼續執行,否則選擇選擇等待可用的令牌、或者直接拒絕。放令牌這個動作是持續不斷的 進行,如果桶中令牌數達到上限,就丟棄令牌,所以就存在這種情況,桶中一直有大量的可用令牌,這 時進來的請求就可以直接拿到令牌執行,比如設置qps為100,那麼限流器初始化完成一秒後,桶中就 已經有100個令牌了,這時服務還沒完全啟動好,等啟動完成對外提供服務時,該限流器可以抵擋瞬時 的100個請求。所以,只有桶中沒有令牌時,請求才會進行等待,最後相當於以一定的速率執行。

(12)基於Filter的限流
SpringCloudGateway官方就提供了基於令牌桶的限流支持。基於其內置的過濾器工廠 RequestRateLimiterGatewayFilterFactory 實現。在過濾器工廠中是通過Redis和lua腳本結合的方 式進行流量控制。
(13)基於Sentinel的限流
Sentinel 支持對 Spring Cloud Gateway、Zuul 等主流的 API Gateway 進行限流。

從 1.6.0 版本開始,Sentinel 提供了 Spring Cloud Gateway 的適配模塊,可以提供兩種資源維度的限 流: route 維度:即在 Spring 配置文件中配置的路由條目,資源名為對應的 routeId 自定義 API 維度:用戶可以利用 Sentinel 提供的 API 來自定義一些 API 分組 Sentinel 1.6.0 引入了 Sentinel API Gateway Adapter Common 模塊,此模塊中包含網關限流的規則 和自定義 API 的實體和管理邏輯: GatewayFlowRule :網關限流規則,針對 API Gateway 的場景定製的限流規則,可以針對不同 route 或自定義的 API 分組進行限流,支持針對請求中的參數、Header、來源 IP 等進行定製化的 限流。 ApiDefinition :用戶自定義的 API 定義分組,可以看做是一些 URL 匹配的組合。比如我們可以 定義一個 API 叫 my_api ,請求 path 模式為 /foo/** 和 /baz/** 的都歸到 my_api 這個 API 分組下麵。限流的時候可以針對這個自定義的 API 分組維度進行限流。
基於Sentinel 的Gateway限流是通過其提供的Filter來完成的,使用時只需註入對應的 SentinelGatewayFilter 實例以及 SentinelGatewayBlockExceptionHandler 實例即可。 @PostConstruct定義初始化的載入方法,用於指定資源的限流規則。這裡資源的名稱為 orderservice ,統計時間是1秒內,限流閾值是1。表示每秒只能訪問一個請求。
(14)網關高可用
高可用HA(High Availability)是分散式系統架構設計中必須考慮的因素之一,它通常是指,通過設計 減少系統不能提供服務的時間。我們都知道,單點是系統高可用的大敵,應該儘量在系統設計的過程中避免單點。方法論上,高可用保證的原則是“集群化”,或者 叫“冗餘”:只有一個單點,掛了服務會受影響;如果有冗餘備份,掛了還有其他backup能夠頂上。
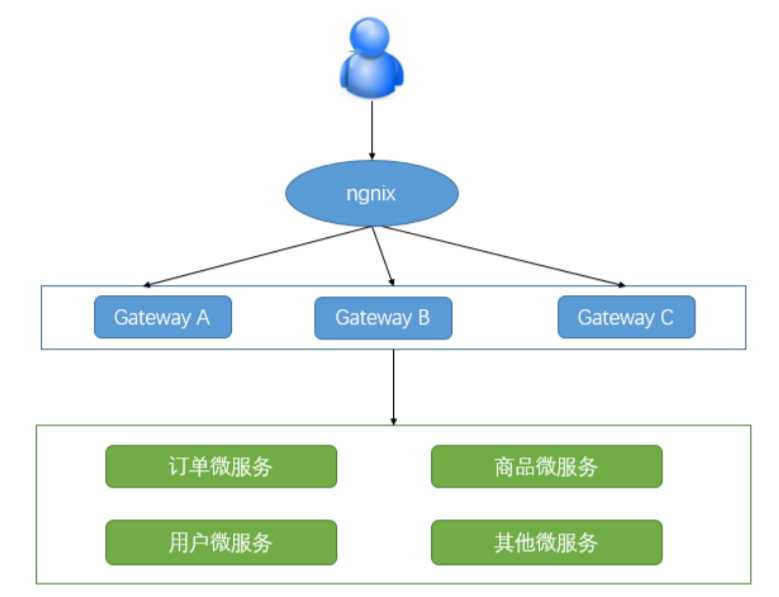
我們實際使用 Spring Cloud Gateway 的方式如上圖,不同的客戶端使用不同的負載將請求分發到後端 的 Gateway,Gateway 再通過HTTP調用後端服務,最後對外輸出。因此為了保證 Gateway 的高可用 性,前端可以同時啟動多個 Gateway 實例進行負載,在 Gateway 的前端使用 Nginx 或者 F5 進行負載 轉發以達到高可用性。
(15) 執行流程分析
Spring Cloud Gateway 核心處理流程如上圖所示,Gateway的客戶端向 Spring Cloud Gateway 發 送請求,請求首先被 HttpWebHandlerAdapter 進行提取組裝成網關上下文,然後網關的上下文會傳遞 到 DispatcherHandler 。 DispatcherHandler 是所有請求的分發處理器, DispatcherHandler 主要 負責分發請求對應的處理器。比如請求分發到對應的 RoutePredicateHandlerMapping (路由斷言處 理映射器)。路由斷言處理映射器主要作用用於路由查找,以及找到路由後返回對應的 FilterWebHandler 。 FilterWebHandler 主要負責組裝Filter鏈並調用Filter執行一系列的Filter處理, 然後再把請求轉到後端對應的代理服務處理,處理完畢之後將Response返回到Gateway客戶端。
二、微服務的鏈路追蹤概述
1、微服務架構下的問題
在大型系統的微服務化構建中,一個系統會被拆分成許多模塊。這些模塊負責不同的功能,組合成系統,最終可以提供豐富的功能。在這種架構中,一次請求往往需要涉及到多個服務。互聯網應用構建在不同的軟體模塊集上,這些軟體模塊,有可能是由不同的團隊開發、可能使用不同的編程語言來實現、 有可能布在了幾千台伺服器,橫跨多個不同的數據中心,也就意味著這種架構形式也會存在一些問題: 如何快速發現問題? 如何判斷故障影響範圍? 如何梳理服務依賴以及依賴的合理性? 如何分析鏈路性能問題以及實時容量規劃? 分散式鏈路追蹤(Distributed Tracing),就是將一次分散式請求還原成調用鏈路,進行日誌記錄,性能監控並將 一次分散式請求的調用情況集中展示。比如各個服務節點上的耗時、請求具體到達哪台機器 上、每個服務節點的請求狀態等等。 目前業界比較流行的鏈路追蹤系統如:Twitter的Zipkin,阿裡的鷹眼,美團的Mtrace,大眾點評的cat等,大部分都是基於google發表的Dapper。Dapper闡述了分散式系統,特別是微服務架構中鏈路 追蹤的概念、數據表示、埋點、傳遞、收集、存儲與展示等技術細節。
2、 Sleuth概述
Spring Cloud Sleuth 主要功能就是在分散式系統中提供追蹤解決方案,並且相容支持了 zipkin,只需要在pom文件中引入相應的依賴即可。
(1)相關概念
Spring Cloud Sleuth 為Spring Cloud提供了分散式根據的解決方案。它大量借用了Google Dapper的 設計。先來瞭解一下Sleuth中的術語和相關概念。 Spring Cloud Sleuth採用的是Google的開源項目Dapper的專業術語。 Span:基本工作單元,例如,在一個新建的span中發送一個RPC等同於發送一個回應請求給 RPC,span通過一個64位ID唯一標識,trace以另一個64位ID表示,span還有其他數據信息,比 如摘要、時間戳事件、關鍵值註釋(tags)、span的ID、以及進度ID(通常是IP地址) span在不斷的啟動和停止,同時記錄了時間信息,當你創建了一個span,你必須在未來的某個時 刻停止它。 Trace:一系列spans組成的一個樹狀結構,例如,如果你正在跑一個分散式大數據工程,你可能 需要創建一個trace。 Annotation:用來及時記錄一個事件的存在,一些核心annotations用來定義一個請求的開始和結 束 cs - Client Sent -客戶端發起一個請求,這個annotion描述了這個span的開始 sr - Server Received -服務端獲得請求並準備開始處理它,如果將其sr減去cs時間戳便可得到 網路延遲 ss - Server Sent -註解表明請求處理的完成(當請求返回客戶端),如果ss減去sr時間戳便可得 到服務端需要的處理請求時間 cr - Client Received -表明span的結束,客戶端成功接收到服務端的回覆,如果cr減去cs時間 戳便可得到客戶端從服務端獲取回覆的所有所需時間
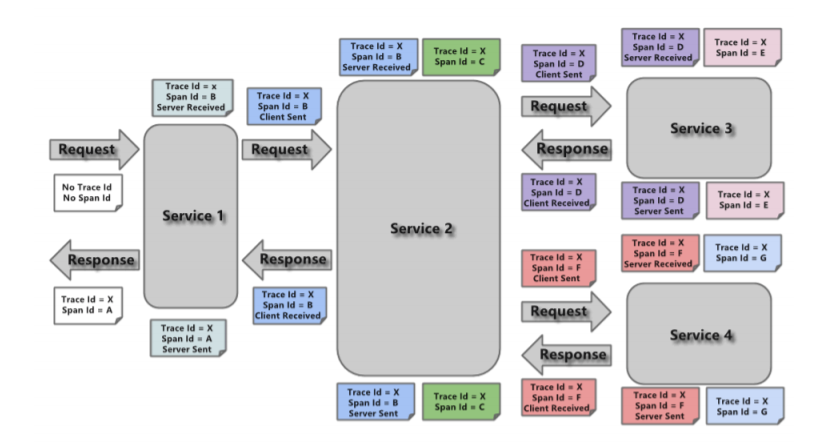
(2) 鏈路追蹤Sleuth入門
查看日誌文件並不是一個很好的方法,當微服務越來越多日誌文件也會越來越多,通過Zipkin可以將日誌聚合,併進行可視化展示和全文檢索。
(3)Zipkin的概述
Zipkin 是 Twitter 的一個開源項目,它基於 Google Dapper 實現,它致力於收集服務的定時數據,以解決微服務架構中的延遲問題,包括數據的收集、存儲、查找和展現。 我們可以使用它來收集各個服務 器上請求鏈路的跟蹤數據,並通過它提供的 REST API 介面來輔助我們查詢跟蹤數據以實現對分散式系 統的監控程式,從而及時地發現系統中出現的延遲升高問題並找出系統性能瓶頸的根源。除了面向開發 的 API 介面之外,它也提供了方便的 UI 組件來幫助我們直觀的搜索跟蹤信息和分析請求鏈路明細,比 如:可以查詢某段時間內各用戶請求的處理時間等。 Zipkin 提供了可插拔數據存儲方式:InMemory、MySql、Cassandra 以及 Elasticsearch。
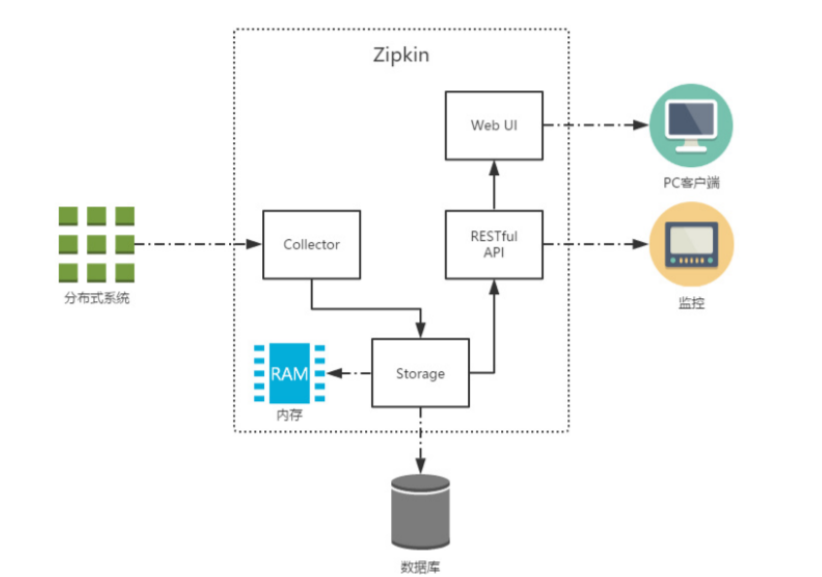
上圖展示了 Zipkin 的基礎架構,它主要由 4 個核心組件構成:
Collector:收集器組件,它主要用於處理從外部系統發送過來的跟蹤信息,將這些信息轉換為 Zipkin 內部處理的 Span 格式,以支持後續的存儲、分析、展示等功能。
Storage:存儲組件,它主要對處理收集器接收到的跟蹤信息,預設會將這些信息存儲在記憶體中, 我們也可以修改此存儲策略,通過使用其他存儲組件將跟蹤信息存儲到資料庫中。
RESTful API:API 組件,它主要用來提供外部訪問介面。比如給客戶端展示跟蹤信息,或是外接系統訪問以實現監控等。
Web UI:UI 組件,基於 API 組件實現的上層應用。通過 UI 組件用戶可以方便而有直觀地查詢和 分析跟蹤信息。
Zipkin 分為兩端,一個是 Zipkin 服務端,一個是 Zipkin 客戶端,客戶端也就是微服務的應用。 客戶端會配置服務端的 URL 地址,一旦發生服務間的調用的時候,會被配置在微服務裡面的 Sleuth 的監聽器監聽,並生成相應的 Trace 和 Span 信息發送給服務端。 發送的方式主要有兩種,一種是 HTTP 報文的方式,還有一種是消息匯流排的方式如 RabbitMQ。不論哪種方式,我們都需要: 一個 Eureka 服務註冊中心,這裡我們就用之前的 eureka 項目來當註冊中心。 一個 Zipkin 服務端。 多個微服務,這些微服務中配置Zipkin 客戶端。
(4)基於消息中間件收集數據
在預設情況下,Zipkin客戶端和Server之間是使用HTTP請求的方式進行通信(即同步的請求方式),在網路波動,Server端異常等情況下可能存在信息收集不及時的問題。Zipkin支持與rabbitMQ整合完成非同步消息傳輸。 加了MQ之後,通信過程如下圖所示:

(5)存儲跟蹤數據
Zipkin Server預設時間追蹤數據信息保存到記憶體,這種方式不適合生產環境。因為一旦Service關閉重啟或者服務崩潰,就會導致歷史數據消失。Zipkin支持將追蹤數據持久化到mysql資料庫或者存儲到elasticsearch中。
感謝閱讀,借鑒了不少大佬資料,如需轉載,請註明出處,謝謝!https://www.cnblogs.com/huyangshu-fs/p/13888664.html


