
###一、簡介 什麼是分散式爬蟲? 分散式爬蟲就是把一個爬蟲任務放到多台機器上去運行,提高爬取效率 但是每台機器運行同一套代碼,都在各自的任務和去重隊列,等於各爬各的,最終爬的數據是相同的 因此需要提供一個公共的去重隊列和公共的任務隊列,多台機器都在共用的隊列中去調度和去重,然後分別爬取 原來scr ...
一、簡介
什麼是分散式爬蟲?
分散式爬蟲就是把一個爬蟲任務放到多台機器上去運行,提高爬取效率
但是每台機器運行同一套代碼,都在各自的任務和去重隊列,等於各爬各的,最終爬的數據是相同的
因此需要提供一個公共的去重隊列和公共的任務隊列,多台機器都在共用的隊列中去調度和去重,然後分別爬取
原來scrapy的Scheduler維護的是本機的任務隊列(存放Request對象及其回調函數等信息)+本機的去重隊列(存放訪問過的url地址)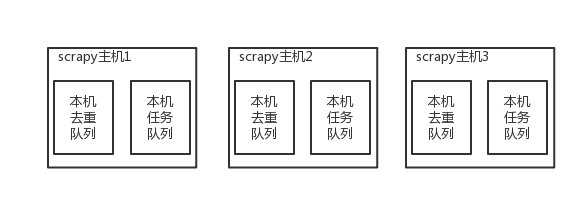
實現分散式的關鍵就是三點:
1、共用隊列
2、重寫Scheduler(調度器),讓其無論去重還是任務都訪問共用隊列
3、為Scheduler定製去重規則(利用redis的集合類型)
以上三點便是scrapy-redis組件的核心功能
二、scrapy-redis實現分散式爬蟲
1 scrapy-redis架構
scrapy-redis整體運行流程如下:核心就是把Scheduler(調度器)放到redis當中去

源碼位置
2 scrapy-redis共用隊列
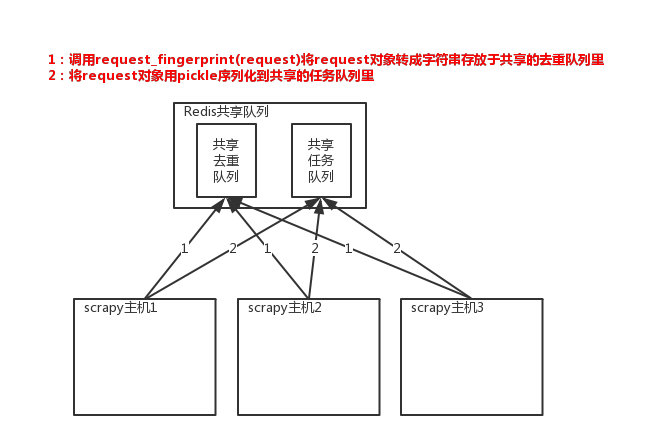
3 使用scrapy-redis組件
1 pip3 install scrapy-redis 安裝
2 原來繼承Spider,現在繼承RedisSpider
源碼spiders.py中,RedisSpider(RedisMixin, Spider)類,繼承了原來的Spider,並繼承了擴展類RedisMixin
3 不能寫start_urls = ['https:/www.cnblogs.com/']
需要寫redis_key = 'myspider:start_urls' 統一管理起始的爬取地址,redis的name對應的是一個列表
放一個起始url,啟動爬蟲後,返回來的url也是丟到這個列表中,每台機器都是從這個列表中取地址爬取,共用一個隊列
class ChoutiSpider(RedisSpider):
name = 'cnblog'
allowed_domains = ['cnblogs.com']
redis_key = 'myspider:start_urls'
4 setting中配置
redis連接
# redis的連接, 預設配置本地+6379
REDIS_HOST = 'localhost' # 主機名
REDIS_PORT = 6379 # 埠
REDIS_USER = # 用戶名
REDIS_PASSWORD = # 密碼
REDIS_URL = 'redis://user:pass@hostname:port' # 支持直接鏈接
REDIS_PARAMS = {} # Redis連接參數
REDIS_PARAMS['redis_cls'] = 'myproject.RedisClient' # 指定連接Redis的Python模塊
REDIS_ENCODING = "utf-8" # redis編碼類型
REDIS_ITEMS_KEY = '%(spider)s:items' # 將item持久化到redis時,指定的name
REDIS_ITEMS_SERIALIZER = 'json.dumps' # 將item持久化到redis時,指定序列化函數
重點配置
1、DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 使用scrapy-redis的去重
源碼dupefilter.py中,RFPDupeFilter類重寫了request_seen()方法
def request_seen(self, request):
fp = self.request_fingerprint(request)
# self.server是redis連接,sadd表示向集合中add數據
added = self.server.sadd(self.key, fp)
return added == 0
2、SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 使用scrapy-redis的Scheduler, 分散式爬蟲的配置
3、持久化配置,配了都走公共的,存在redis中,如果不配,各自存各自的庫,當然Mysql也是共用的一個庫
ITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline': 299}
源碼pipelines.py中,RedisPipeline類,_process_item()方法,就是把item對象轉成pickle,再存入redis
def _process_item(self, item, spider):
key = self.item_key(item, spider)
data = self.serialize(item)
self.server.rpush(key, data)
return item
其他配置
# 調度器將不重覆的任務用pickle序列化後放入共用任務隊列,預設使用優先順序隊列,其他PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表)
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'
# 對保存到redis中的request對象進行序列化,預設使用pickle
SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat"
# 調度器中請求任務序列化後存放在redis中的name
SCHEDULER_QUEUE_KEY = '%(spider)s:requests'
# 去重隊列(用的指紋去重,放在集合中),在redis中保存時對應的name
SCHEDULER_DUPEFILTER_KEY = '%(spider)s:dupefilter'
# 去調度器中獲取數據時,如果為空,最多等待時間(最後沒數據,未獲取到)。如果沒有則立刻返回會造成空迴圈次數過多,cpu占用率飆升
SCHEDULER_IDLE_BEFORE_CLOSE = 10
# 是否在關閉時候保留原來的調度器和去重記錄,True=保留,False=清空
SCHEDULER_PERSIST = True
# 是否在開始之前清空 調度器和去重記錄,True=清空,False=不清空
SCHEDULER_FLUSH_ON_START = False
5 啟動scrapy-redis
分散式爬蟲部署在三台機器上,等於每台機器啟一個爬蟲進程,跟在一臺機器上啟動3個進程本質上一樣的
1 進程啟動爬蟲,啟動後要等待從redis中拿出起始url
scrapy crawl cnblog_redis
現在要讓爬蟲運行起來,需要去redis中以myspider:start_urls為key,插入一個起始地址
cmd命令視窗輸入:
2 redis-cil # 啟動redis
3 lpush myspider:start_urls https://www.cnblogs.com/ # 插入起始地址
···

