
幾乎所有的高級編程語言都有自己的垃圾回收機制,開發者不需要關註記憶體的申請與釋放,Python 也不例外。Python 官方團隊的文章 https://devguide.python.org/internals/garbage-collector 詳細介紹了 Python 中的垃圾回收演算法,本文是這篇 ...
幾乎所有的高級編程語言都有自己的垃圾回收機制,開發者不需要關註記憶體的申請與釋放,Python 也不例外。Python 官方團隊的文章 https://devguide.python.org/internals/garbage-collector 詳細介紹了 Python 中的垃圾回收演算法,本文是這篇文章的譯文。
摘要
CPython 中主要的垃圾回收演算法是引用計數。引用計數顧名思義就是統計每個對象有多少個引用,每個引用可能來自另外一個對象,或者一個全局(或靜態)C 變數,或者 C 語言函數中的局部變數。當一個變數的引用計數變成 0,那麼這個對象就會被釋放。如果被釋放的對象包含對其他對象的引用,那麼其他對象的引用計數就會相應地減 1。如果其他對象的引用計數在減 1 之後變成 0,這些對象也會級聯地被釋放掉。在 Python 代碼中可以通過 sys.getrefcount 函數獲取一個對象的引用計數(函數的返回值會比實際的引用計數多 1,因為函數本身也包含一個對目標對象的引用)。
>>> x = object()
>>> sys.getrefcount(x)
2
>>> y = x
>>> sys.getrefcount(x)
3
>>> del y
>>> sys.getrefcount(x)
2
引用計數最大的問題就是不能處理迴圈引用。下麵是一個迴圈引用的例子:
>>> container = []
>>> container.append(container)
>>> sys.getrefcount(container)
3
>>> del container
在這個例子中,container 對象包含一個對自己的引用,所以即使我們移除了一個引用(變數 container)container 對象的引用計數也不會變成 0,因為 container 對象內部仍然有一個對自身的引用。因此如果僅僅通過簡單的引用計數,container 對象永遠不會被釋放。鑒於此,當對象不可達的時候(譯註:當代碼中沒有對實際對象的引用時),我們需要額外的機制來清除這些不可達對象間的迴圈引用。這個額外的機制就是迴圈垃圾收集器,通常簡稱為垃圾收集器(Garbage Collector,GC),雖然引用計數也是一種垃圾回收演算法。
記憶體佈局和對象結構
一般的 Python 對象在 C 語言中的結構體表示如下
object -----> +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ \
| ob_refcnt | |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | PyObject_HEAD
| *ob_type | |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ /
| ... |
為了支持垃圾回收,在一般 Python 對象的記憶體佈局前面加了一些額外的信息
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ \
| *_gc_next | |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | PyGC_Head
| *_gc_prev | |
object -----> +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ /
| ob_refcnt | \
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | PyObject_HEAD
| *ob_type | |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ /
| ... |
通過這種方式,object 可以被看做一般的 Python 對象,當需要垃圾回收相關的信息時可以通過簡單的類型轉換來訪問前面的欄位:((PyGC_Head *)(the_object)-1)。
在後面的章節 優化:通過復用欄位來節省記憶體 會介紹這兩個欄位通常用來串聯起被垃圾收集器管理的對象構成的雙向鏈表( 每個鏈表對應垃圾回收中的一個分代,更多細節在優化:分代回收 中有介紹),但是在不需要鏈表結構的時候這兩個欄位會被用作其他功能來減少記憶體的使用。
使用雙向鏈表是因為其能高效地支持垃圾回收對鏈表的一些高頻操作。所有被垃圾收集器管理的對象被劃分成一些不相交的集合,每個集合都在各自的雙向鏈表中。不同的集合表示不同的分代,對象所處的分代反映了其在垃圾回收中存活了多久。每次垃圾回收的時候,每個分代中的對象會進一步劃分成可達對象和不可達對象。雙向鏈表的一些操作比如移動對象、添加對象、完全刪除一個對象(垃圾收集器管理的對象一般情況下會在兩次垃圾回收之間通過引用計數系統回收)、合併鏈表等,都會在常量時間複雜度完成。並且雙向鏈表支持在遍歷的時候添加和刪除對象,垃圾收集器在運行的時候這也是一個非常頻繁的操作。
為了支持對象的垃圾回收,Python 的 C 介面提供了一些 API 來分配、釋放、初始化、添加和移除被垃圾收集器維護的對象。這些 API 的詳情參見 https://docs.python.org/3/c-api/gcsupport.html。
除了上面的對象結構之外,對於支持垃圾回收的對象的類型對象必須要在 tp_flags 欄位中設置 Py_TPFLAGS_HAVE_GC 標記,並且實現 tp_traverse 句柄。另外這些類型對象還要實現 tp_clear 句柄,除非能夠證明僅僅通過該類型的對象不會形成迴圈引用或者支持垃圾回收的對象是不可變類型。
迴圈引用的識別
CPython 中識別迴圈引用的演算法在 gc 模塊中實現。垃圾收集器只關註清除容器類型的對象(也就是那些能夠包含對其他對象的引用的對象)。比如數組、字典、列表、自定義類實例和擴展模塊中的類等等。雖然迴圈引用並不常見, 但是 CPython 解釋器自身也會由於一些內部引用的存在形成迴圈引用。下麵是一些典型場景
- 異常對象 exception 會包含棧跟蹤對象 traceback,棧跟蹤對象包含棧幀的列表,這些棧幀最終又會包含異常對象。
- 模塊級別的函數會引用模塊的字典 dict(用於解析全局變數),模塊字典反過來又會包含模塊級別的函數。
- 類的實例對象會引用其所屬的類對象,類對象會引用其所在的模塊,模塊會包含模塊內的所有對象(可能還會包含其他的模塊)從而最終會引用到最初的類實例對象。
- 當要表示圖這類數據結構的時候,很容易產生對自身的引用。
如果想要正確釋放不可達的對象,第一步就是要識別出不可達對象。在識別迴圈引用的函數中維護了兩個雙向鏈表:一個鏈表包含所有待掃描的對象,另一個鏈表包含暫時不可達的對象。
為了理解演算法的原理,我們看一下下麵的示例,其中 A 引用了一個迴圈鏈表,另外還有一個不可達的自我引用的對象:
>>> import gc
>>> class Link:
... def __init__(self, next_link=None):
... self.next_link = next_link
>>> link_3 = Link()
>>> link_2 = Link(link_3)
>>> link_1 = Link(link_2)
>>> link_3.next_link = link_1
>>> A = link_1
>>> del link_1, link_2, link_3
>>> link_4 = Link()
>>> link_4.next_link = link_4
>>> del link_4
# 回收不可達的 Link 對象 (和它的字典 __dict__)。
>>> gc.collect()
2
當垃圾收集器開始工作的時候,會將所有要掃描的容器對象放在第一個鏈表中,這樣做是為了將所有不可達對象移除。因為正常情況下大多數對象都是可達的,所以移除不可達對象會涉及更少的指針操作,因此更高效。
演算法開始的時候會為所有支持垃圾回收的對象另外初始化一個引用計數欄位(下圖中的 gc_ref),初始值設置為對象實際的引用計數。因為演算法在識別迴圈引用的計算中會修改引用計數,通過使用一個另外的欄位 gc_ref 解釋器就不會修改對象真正的引用計數。
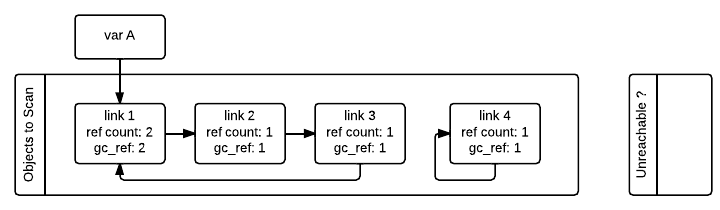
垃圾收集器會遍歷第一個列表中的所有容器對象,每遍歷一個對象都會將其所引用的所有的其他對象的 gc_ref 欄位減 1。為了找到容器對象所引用的其他對象需要調用容器類的 tp_traverse 方法(通過 C API 實現或者由超類繼承)。在遍歷完之後,只有那些被外部變數引用的對象的 gc_ref 的值才會大於 0。
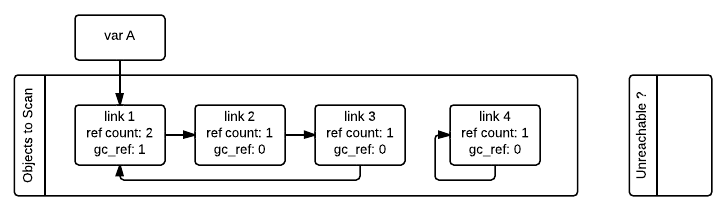
需要註意的是即使 gc_ref == 0 也不能說明對象就是不可達的。因為被外部變數引用的對象(gc_ref > 0)仍然可能引用它們。比如在我們的例子中,link_2 對象在第一次遍歷之後 gc_ref == 0,但是 link_1 對象仍然會引用 link_2,而 link_1 是從外部可達的。為了找到那些真正不可達的對象,垃圾收集器需要重新遍歷容器對象,這次遍歷的時候會將 gc_ref == 0 的對象標記為暫時不可達並且移動到暫時不可達的鏈表中。下圖描述了垃圾收集器在處理了 link_3 和 link_4 對象但是還沒處理 link_1 和 link_2 對象時的狀態。
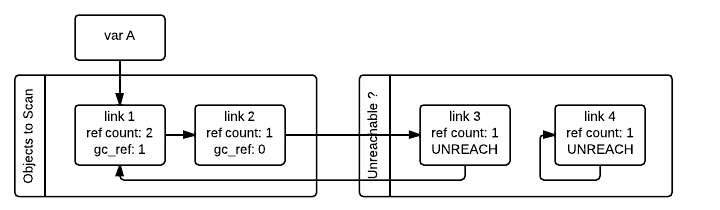
垃圾收集器接下來會處理 link_1 對象。由於 gc_ref == 1,垃圾收集器不會對其做特殊處理因為知道其可達(並且已經在可達對象鏈表中)。
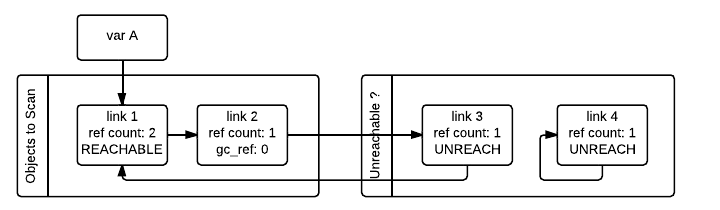
當垃圾收集器遇到可達對象時(gc_ref > 0),會通過 tp_traverse 找到其所引用的其他對象,並且將這些對象移動到可達對象鏈表(它們最初所在的鏈表)的末尾,同時設置 gc_ref 欄位為 1。link_2 和 link_3 對象就會被這樣處理,因為它們都被 link_1 引用。在上圖所示狀態之後,垃圾收集器會檢查被 link_1 引用的對象從而知道 link_3 是可達的,所以將其移回到原來的鏈表中並且設置 gc_ref 欄位值為 1,那麼垃圾收集器下次遇到 link_3 的時候就知道它是可達的。為了避免重覆處理同一個對象,垃圾收集器在處理被可達對象引用的對象的時候會標記它們已經被訪問過(通過清除 PREV_MASK_COLLECTING 標記)。
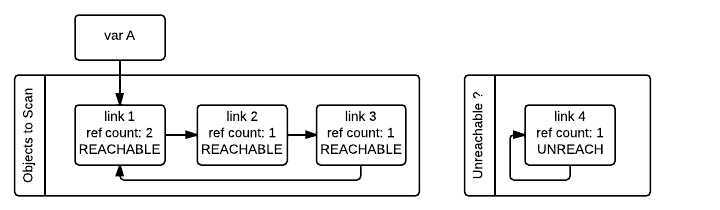
需要註意的是那些開始被標記為暫時性不可達後來又被移回到可達對象鏈表的對象,會再次被垃圾收集器訪問到,因為按照演算法邏輯現在被這些對象引用的其他對象也要被處理。第二次遍歷實際上是對這些對象間引用關係構成的圖的廣度優先搜索。在第二遍遍歷結束後,垃圾收集器就可以確定現在還留在暫時性不可達對象鏈表中的對象是真的不可達,因此可以被回收掉。
值得註意的是,整個演算法中沒有遞歸操作,也不需要相對於對象數量、指針數量或引用鏈長度的線性記憶體空間。除了臨時的 C 變數占用 O(1) 的常量空間外,對象本身的欄位都已經包含了演算法需要的所有數據。
為什麼選擇移動不可達的對象
因為大多數對象都是可達對象,因此移動不可達對象看起來很合理。但是真正的原因並非想象的那麼簡單。
假設我們依次創建了 A、B 和 C 三個對象,那麼它們在第一代(譯註:這裡的第一代指的是分代回收)中的順序就是創建順序。如果 B 引用 A,C 引用 B,並且 C 有外部引用,那麼在垃圾回收演算法的第一輪遍歷之後 A、B 和 C 的 gc_ref 值分別為 0、0 和 1,因為只有 C 是外部可達對象。
在演算法的第二輪遍歷中,會先訪問 A,因為 gc_ref 為 0 會被移動到暫時性不可達對象鏈表中,B 也一樣。當訪問到 C 的時候會將 B 移回到可達對象鏈表中,當再次訪問 B 的時候 A 也會被移回到可達對象鏈表中。
本可以不用移動,A 和 B 卻來回移動了兩次,為什麼要這麼做呢?如果演算法直接移動可達對象的話,那麼只用將 A、B 和 C 分別移動一次即可。這麼做的關鍵是在垃圾回收結束的時候這幾個對象在鏈表中的順序依次為 C、B 和 A,與它們最初的創建順序相反。在後續的垃圾回收中,它們不再需要做任何移動。因為大多數對象之間都沒有迴圈引用,這樣做只會在第一次垃圾回收的時候開銷比較大,在後續的垃圾回收中能節省很多移動的開銷。
銷毀不可達對象
一旦垃圾收集器確定了最終的不可達對象列表,就開始銷毀這些對象,銷毀的大體過程如下
- 處理並且清除弱引用(如果有的話)。如果要銷毀的不可達對象有弱引用的回調,那麼需要處理回調函數。這個處理過程需要特別小心,因為一個小小的錯誤就可能讓狀態不一致的對象被覆活或者被回調函數所調用的 Python 函數引用。如果弱引用對象本身也是不可達的(弱引用和其引用的對象在不可達的迴圈引用中),那麼這個弱引用對象需要馬上被清理並且不用調用回調函數。如果不馬上清理的話,那麼在後來調用
tp_clear的時候會造成嚴重後果。當弱引用和其引用的對象都不可達的時候,那麼兩者都會被銷毀,因此可以先銷毀弱引用,這個時候其引用的對象還存在,所以可以忽略弱引用的回調。 - 如果對象有老版本的終結器(
tp_del)需要將其移到gc.garbage列表中。 - 調用不可達對象的終結器(
tp_finalize函數)並且標記這些對象已終結,避免對象被覆活後或者在其他對象的終結器已經移除該對象的情況下重覆調用tp_finalize。 - 處理被覆活的對象。如果有些不可達對象在上一步被覆活,垃圾收集器需要重新計算出最終的不可達對象。
- 對於每個最終的不可達對象,調用
tp_clear來打破迴圈引用使每個對象的引用計數都變成 0,從而觸發基於引用計數的銷毀邏輯。
優化:分代回收
為了避免每次垃圾回收的時候耗時太久,垃圾收集器使用了一個常用的優化:分代回收。分代回收有個前提假設,認為大多數對象的生命周期都很短,會在創建後很快就被回收。這個假設與現實中很多 Python 程式的情況一致,因為很多臨時對象會被很快地創建和銷毀。存活越久的對象越不容易因為不可達而被回收。
為了充分利用這一點,所有容器對象都會被分成三代中的某一代。每個新建的容器對象都處於第一代(generation 0)。上面描述的垃圾回收演算法只在某一個具體的分代中進行,那些沒有被回收的對象會進入下一代(generation 1),這一代中的對象相對於上一代執行垃圾回收的次數會更少。如果對象在新一代中仍然沒有被回收就會移動到最後一代(generation 2),在最後一代中執行垃圾回收的次數是最少的。
垃圾收集器會記錄在上次垃圾回收之後新增對象與銷毀對象數量之差,也就是凈新增對象數量。如果超過了 threshold_0 垃圾收集器就會執行。最初的時候垃圾回收只在 generation 0 中執行。如果 generation 1 在上次執行垃圾回收之後, generation 0 中執行垃圾回收的次數超過了 threshold_1 那麼就會再次在 generation 1 中執行垃圾回收。對於 generation 2 的處理稍微複雜點,在第三代中的垃圾回收 中單獨介紹。前面說的閾值 threshold_0 和 threshold_1 可以通過函數 gc.get_threshold 查看(譯註:原文這裡描述有誤,我在 issue https://github.com/python/devguide/issues/1027 中提出並被作者採納):
>>> import gc
>>> gc.get_threshold()
(700, 10, 10)
每個分代中的對象可以通過函數 gc.get_objects(generation=NUM) 查看,另外可以通過調用函數 gc.collect(generation=NUM) 指定在哪個分代中執行垃圾回收。
>>> import gc
>>> class MyObj:
... pass
...
# 為了更容易觀察年輕代中的對象需要將第一代和第二代中的對象都移動到第三代
>>> gc.collect()
0 # 譯註:不同版本執行的時候的結果不一樣
# 創建迴圈引用
>>> x = MyObj()
>>> x.self = x
# x 最初在第一代中
>>> gc.get_objects(generation=0)
[..., <__main__.MyObj object at 0x7fbcc12a3400>, ...]
# 在第一代中執行垃圾回收之後,x 就移動到了第二代
>>> gc.collect(generation=0)
0
>>> gc.get_objects(generation=0)
[] # 譯註:在交互模式下,每次鍵入的代碼都會經過編譯再執行,所以輸出中還有編譯過程生成的一些被垃圾收集器管理的對象
>>> gc.get_objects(generation=1)
[..., <__main__.MyObj object at 0x7fbcc12a3400>, ...]
第三代中的垃圾回收
在上面提到的各種閾值的基礎之上,只有當比率 long_lived_pending / long_lived_total 的值高於一個給定值(硬編碼為 25%)的時候,才會在第三代中進行一次全量回收。因為儘管對於非全量的回收(比如創建很多被垃圾收集器管理的對象並且都放進一個列表中,那麼垃圾回收的時間複雜度不是線性的,而是 O(N²)。(譯註:這裡的時間複雜度不是上面說的一次垃圾回收的時間與分代中對象數量的關係,而是指在創建很多對象到列表中這種程式模式下,所有垃圾回收的總耗時與創建的對象數量的關係,詳情見 https://mail.python.org/pipermail/python-dev/2008-June/080579.html))。如果使用上面的比率,就會變成攤還之後的線性複雜度(這種做法可以總結為:儘管隨著創建的對象越來越多全量垃圾回收會變得越來越慢,但是全量垃圾回收的次數也會變得越來越少)。
優化:通過復用欄位來節省記憶體
為了節省記憶體,支持垃圾回收的對象中的用於鏈表的兩個指針也會被用作其他用途。這種常見的優化叫做胖指針或標記指針:在指針中存儲額外的數據,能夠這樣做也是利用了記憶體定址的特性。大多數架構會將數據的記憶體同數據的大小對齊,通常是一個字或多個字對齊。對齊之後就會使得指針的最低幾位不會被使用,而這些低位就可以用作標記或存儲其他信息 —— 通常作為位域(每一位都是一個獨立的標記)—— 只要程式在使用指針定址前屏蔽掉這些位域即可。例如在 32 位架構上,一個字大小是 32 位 4 位元組,所以字對齊的地址都是 4 的倍數,也就是以 00 結尾,因此最低 2 位可以用作他用;類似的在 64 位結構上,一個字大小是 64 位 8 位元組,字對齊的地址以 000 結尾,最低 3 位可以用來保存其他數據。
CPython 的垃圾收集器的實現就使用了記憶體佈局和對象結構 中描述的 PyGC_Head 結構體中的兩個胖指針:
_gc_prev欄位正常情況下用於指向雙向鏈表中的前一個元素,低 2 位會用來保存PREV_MASK_COLLECTING和_PyGC_PREV_MASK_FINALIZED標記。在沒有進行垃圾回收的時候只有表示對象是否被釋放的標記_PyGC_PREV_MASK_FINALIZED會被使用。在垃圾回收期間,_gc_prev會被臨時用來保存引用計數gc_ref,在此期間垃圾收集器維護的對象鏈表只能當做單鏈表使用,直到_gc_prev恢複原來的值。_gc_next欄位用於指向雙向鏈表中的下一個元素,垃圾回收演算法在檢測迴圈引用時,它的最低位會用來保存表示對象是否暫時性不可達的標記NEXT_MASK_UNREACHABLE。垃圾回收演算法中使用雙向鏈表使得大多數操作都能在常量時間複雜度內完成,但是無法高效地判斷一個對象是在可達鏈表中還是在暫時性不可達鏈表中。由於有標記NEXT_MASK_UNREACHABLE的存在,當需要判斷對象在哪個鏈表中的時候只用檢查該標記即可。
註意事項
因為胖指針或標記指針保存了其他數據,所以不能直接用來定址,必須在清除這些其他數據之後才能得到真正的地址。尤其需要註意那些直接操作鏈表的函數,因為這些函數經常會假設鏈表中的指針狀態一致。
優化:延遲管理容器對象
有些容器對象不會產生迴圈引用,所以垃圾收集器沒必要管理它們。解除對這些對象的管理會提高垃圾收集器的性能。但是判斷一個對象是否可以解除管理也是有成本的,因此必須要權衡一下成本和由此給垃圾收集器帶來的收益。有兩個可能的時機可以解除對容器對象的管理:
- 容器對象創建的時候
- 垃圾回收的時候
大的原則是原子類型不需要被垃圾收集器管理,非原子類型(容器、用戶自定義對象等)需要。也有一些針對特定類型的優化避免垃圾收集器在垃圾回收時對一些簡單對象做不必要的檢查。下麵是一些對內置類型延遲管理的例子:
- 只包含不可變對象(整數、字元串或者只包含不可變對象的元組)的元組不需要被管理。解釋器會創建大量的元組,其中很多在垃圾回收之前就銷毀了。因此沒必要在創建時就對符合條件的元組解除管理。因此除了空元組之外的所有元組在創建時都會被垃圾收集器管理,直到垃圾回收的時候才會確定是否有存活的元組需要解除管理。如果一個元組中的所有元素都沒有被垃圾收集器管理,那麼元組本身也可以解除管理。每個分代中的垃圾回收都會對元組做是否需要解除管理的檢查,因此一個元組可能在多次檢查之後才會被解除管理。
- 只包含不可變對象的字典也不需要被垃圾收集器管理。字典是在創建時解除管理的。如果另一個被管理的對象加入到字典中(無論是作為鍵還是值),那麼垃圾收集器都會重新管理字典。另外,在全量垃圾回收(所有分代中)時,垃圾收集器也會檢查字典中的內容是否都沒有被管理,如果滿足條件也會對字典解除管理。
垃圾回收模塊提供了 Python 函數 is_tracked(obj) 返回對象當前是否被垃圾收集器管理。當然後續垃圾回收的時候可能會改變管理狀態。
>>> gc.is_tracked(0)
False
>>> gc.is_tracked("a")
False
>>> gc.is_tracked([])
True
>>> gc.is_tracked({})
False
>>> gc.is_tracked({"a": 1})
False
>>> gc.is_tracked({"a": []})
True


