
轉載至我的博客 https://www.infrastack.cn ,公眾號:架構成長指南 當我們使用 Mysql資料庫到達一定量級以後,性能就會逐步下降,而解決此類問題,常用的手段就是引入資料庫中間件進行分庫分表處理,比如使用 Mycat、ShadingShpere、tddl,但是這種都是過去式了 ...
轉載至我的博客 https://www.infrastack.cn ,公眾號:架構成長指南
當我們使用 Mysql資料庫到達一定量級以後,性能就會逐步下降,而解決此類問題,常用的手段就是引入資料庫中間件進行分庫分表處理,比如使用 Mycat、ShadingShpere、tddl,但是這種都是過去式了,現在使用分散式資料庫可以避免分庫分表
為什麼不建議分庫分表呢?
分庫分表以後,會面臨以下問題
- 分頁問題,例如:使用傳統寫法,隨著頁數過大性能會急劇下降
- 分散式事務問題
- 數據遷移問題,例如:需要把現有數據通過分配演算法導入到所有的分庫中
- 數據擴容問題,分庫分表的數據總有一天也會到達極限,需要增大分片
- 開發模式變化,比如在請求數據時,需要帶分片鍵,否則就會導致所有節點執行
- 跨庫跨表查詢問題
- 業務需要進行一定取捨,由於分庫分表的局限性,有些場景下需要業務進行取捨
以上只是列舉了一部分問題,為了避免這些問題,可以使用分散式資料庫TiDB來處理
TiDB介紹
TiDB 是 PingCAP 公司研發的一款開源分散式關係型資料庫,從 2015年 9 月開源,至今已經有9 年時間,可以說已經非常成熟,它是一款同時支持OLTP(線上事務處理)和OLAP(線上分析處理)的融合型分散式資料庫產品,具備水平擴縮容,金融級高可用、實時 HTAP(Hybrid Transactional and Analytical Processing)、雲原生的分散式資料庫,相容 MySQL 5.7 協議和 MySQL 生態等重要特性,它適合高可用、強一致要求較高、數據規模較大等各種應用場景。
核心特性
- 金融級高可用
- 線上水平擴容或者縮容,並且存算分離
- 雲原生的分散式資料庫,支持部署在公有雲,私有雲,混合雲中
- 實時HTAP,提供TIKV行存儲引擎和TiFlash列存儲引擎
- 相容MySQL協議和MySQL生態
- 分散式事務強一致性
- 從 MySQL 無縫切換到 TiDB,幾乎無需修改代碼,遷移成本極低
- PD在分散式理論CAP方面滿足CP,是強一致性的
應用場景
- 對數據一致性及高可靠、系統高可用、可擴展性、容災要求較高的金融行業屬性的場景
- 對存儲容量、可擴展性、併發要求較高的海量數據及高併發的OLTP場景
- 數據匯聚、二次加工處理的場景
案例
TiDB 有1500 多家不同行業的企業應用在了生產環境,以下是一些有代表性企業,要想查看更多案例,可以訪問TiDB 官網查詢

系統架構
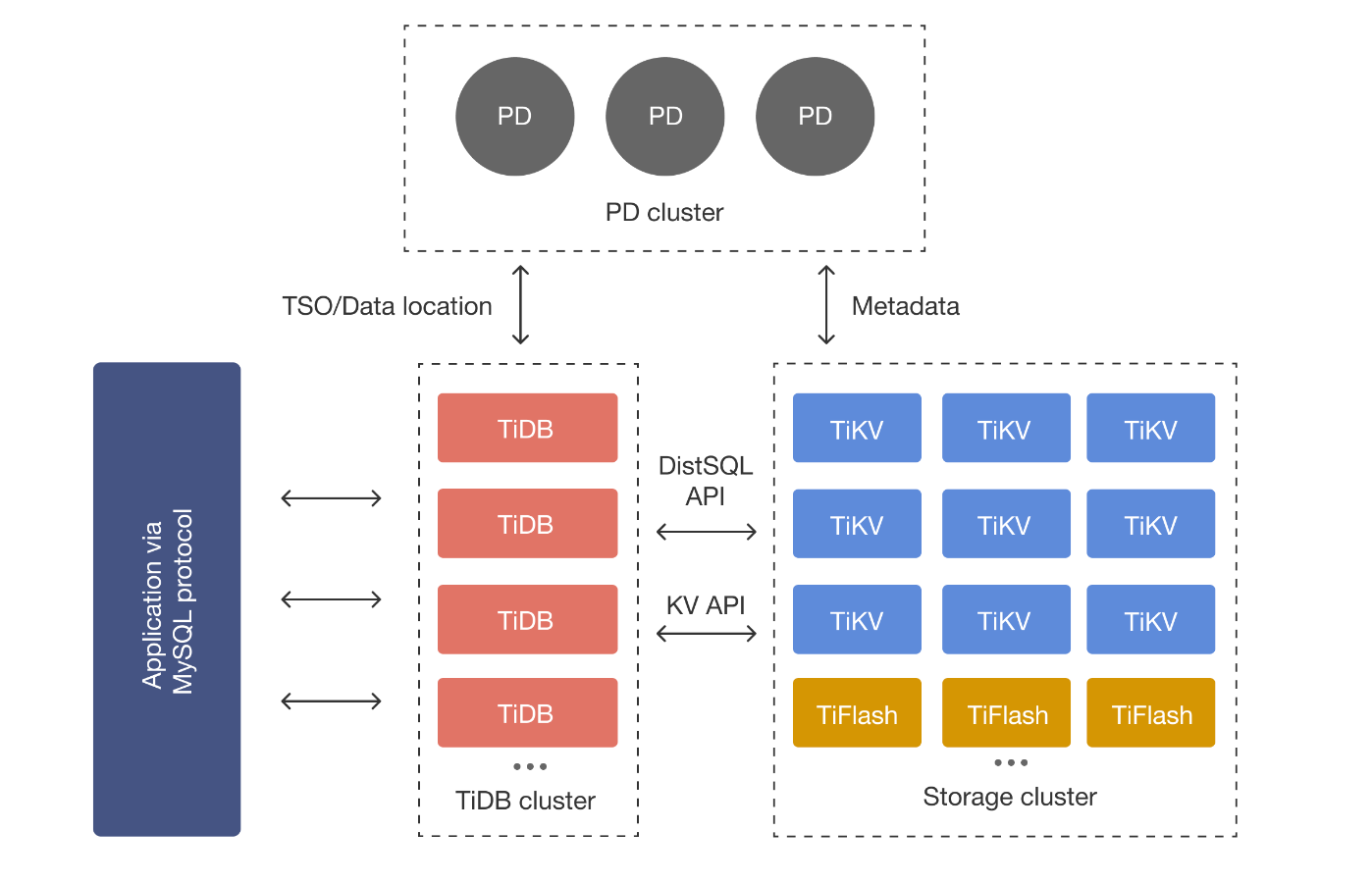
TIDB Server
SQL 層,對外暴露 MySQL 協議的連接 endpoint,負責接收SQL請求,處理SQL相關的邏輯,並通過PD找到存儲計算所需數據的TiKV地址,與TiKV交互獲取數據,最終返回結果。TiDB Server 是無狀態的,其本身並不存儲數據,只負責計算,可以無限水平擴展,可以通過負載均衡組件(LVS、HAProxy或F5)對外提供統一的接入地址,客戶端的連接可以均勻地分攤在多個 TiDB 實例上以達到負載均衡的效果。
PD Server
整個集群的管理模塊,其主要工作有三個:
- 存儲集群的元信息(某個Key存儲在那個TiKV節點);
- 對TiKV集群進行調度和負載均衡、Leader選舉;
- 分配全局唯一且遞增的事務ID。
PD 是一個集群,需要部署奇數個節點,一般線上推薦至少部署3個節點。PD在選舉的過程中無法對外提供服務,這個時間大約是3秒。
TIKV Server
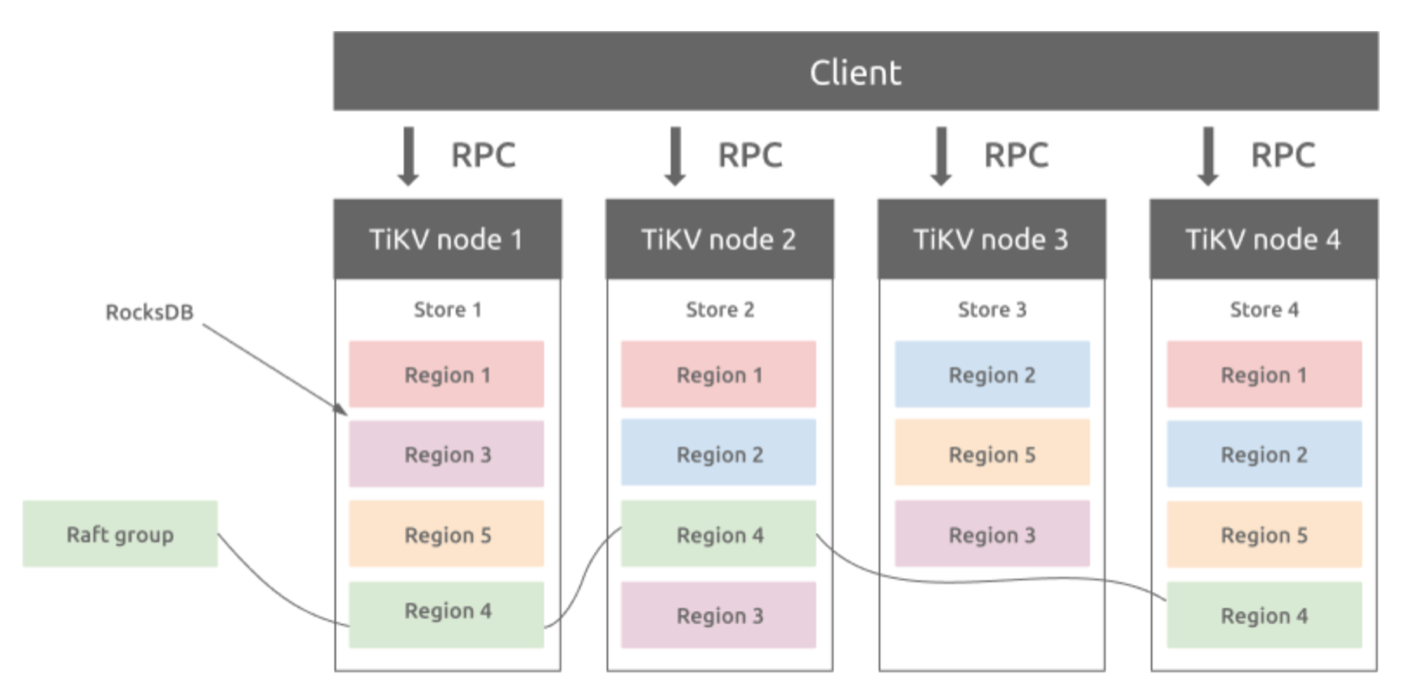
TiDB 現在同時支持OLTP 和 OLAP,而TiKV負責存儲OLTP數據,從外部看TiKV是一個分散式的提供事務的Key-Value存儲引擎。存儲數據的基本單位是Region,每個Region負責存儲一個Key Range(從StartKey到EndKey的左閉右開區間)的數據,每個TiKV節點會負責多個Region。
TiKV如何做到數據不丟失的?

簡單理解,就是把數據複製到多台機器上,這樣一個節點down 機,其他節點上的副本還能繼續提供服務;複雜理解,需要這個數據可靠並且高效複製到其他節點,並且能處理副本失效的情況,那怎麼做呢,就是使用 Raft一致性演算法
Region 與副本之間通過 Raft 協議來維持數據一致性,任何寫請求都只能在 Leader 上寫入,並且需要寫入多數副本後(預設配置為 3 副本,即所有請求必須至少寫入兩個副本成功)才會返回客戶端寫入成功。
分散式事務支持
TiKV 支持分散式事務,我們可以一次性寫入多個 key-value 而不必關心這些 key-value 是否處於同一個數據切片 (Region) 上,TiKV 的分散式事務參考了Google 在 BigTable 中使用的事務模型Percolator,具體可以訪問論文瞭解
與MySQL的對比
支持的特性
- 支持分散式事務,原理是基於Google Percolator,Percolator是基於Bigtable的,所以數據結構直接使用了Bigtable的Tablet。詳情可參考https://zhuanlan.zhihu.com/p/39896539
- 支持鎖,TIDB是樂觀鎖 +MVCC ,MySQL是悲觀鎖+MVCC,要註意TIDB執行Update、Insert、Delete時不會檢查衝突,只有在提交時才會檢查寫寫衝突,所以在業務端執行SQL語句後,要註意檢查返回值,即使執行沒有出錯,提交的時候也可能出錯。
不支持的功能特性
- 不支持存儲過程、函數、觸發器
- 自增id只支持在單個TIDB Server的自增,不支持多個TIDB Server的自增。
- 外鍵約束
- 臨時表
- Mysql追蹤優化器
XA語法(TiDB 內部使用兩階段提交,但並沒有通過 SQL 介面公開)
資源使用情況
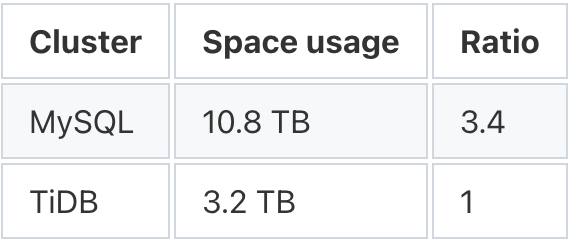
TiDB 具有很高的數據壓縮比,MySQL 中的 10.8 TB 數據在 TiDB 中變成了 3.2 TB,還是三副本的總數據量。因此,MySQL 與 TiDB 的空間使用比例為 3.4:1。
同等量級,使用2 年以後,資源使用情況
- MySQL使用32 個節點,而 TiDB 只有 14 個
- MySql 用了 512 個 CPU 核心,而 TiDB 將僅使用 224 個,不到 MySQL 的一半。
- MySQL 使用 48 TB 存儲空間,而 TiDB 將使用 16 TB,僅為 MySQL 的 1/3。


性能測試
測試報告 1
來源:https://www.percona.com/blog/a-quick-look-into-tidb-performance-on-a-single-server/
五個 ecs 實例,使用了不同配置,以此測試
- t2.medium:2 個 CPU 核心
- x1e.xlarge:4 個 CPU 核心
- r4.4xlarge:16 個 CPU 核心
- m4.16xlarge:64 個 CPU 核心
- m5.24xlarge:96 個 CPU 核心
MySQL 中的資料庫大小為 70Gb,TiDB 中的資料庫大小為 30Gb(壓縮)。該表沒有二級索引(主鍵除外)。
測試用例
-
簡單計數(*):
select count(*) from ontime; -
簡單分組依據
select count(*), year from ontime group by year order by year; -
用於全表掃描的複雜過濾器
select * from ontime where UniqueCarrier = 'DL' and TailNum = 'N317NB' and FlightNum = '2' and Origin = 'JFK' and Dest = 'FLL' limit 10; -
複雜的分組依據和排序依據查詢
select SQL_CALC_FOUND_ROWS FlightDate, UniqueCarrier as carrier, FlightNum, Origin, Dest FROM ontime WHERE DestState not in ('AK', 'HI', 'PR', 'VI') and OriginState not in ('AK', 'HI', 'PR', 'VI') and flightdate > '2015-01-01' and ArrDelay < 15 and cancelled = 0 and Diverted = 0 and DivAirportLandings = '0' ORDER by DepDelay DESC LIMIT 10;下圖表示結果(條形表示查詢響應時間,越小越好):

系統基準測試
在 m4.16xlarge 實例上使用 Sysbench 進行點選擇(意味著通過主鍵選擇一行,線程範圍從 1 到 128)(記憶體限制:無磁碟讀取)。結果在這裡。條形代表每秒的交易數量,越多越好:

系統測試報告 2
來源:https://www.dcits.com/show-269-4103-1.html
硬體配置


測試場景

測試分兩階段進行,第一階段測試數據為100萬單,第二階段測試數據為1300萬單。在此基礎上,使用Jmeter壓力測試10萬單結果如下:


從測試結果來看,在小數據量mysql性能是好於TiDB,因為 TiDB 是分散式架構,如果小數據量,在網路通訊節點分發一致性等方面花的時間就很多,然後各個節點執行完還要彙總返回,所以開銷是比較大的,但是數據量一上來TiDB 優勢就體現出來了,所以如果數據量比較小,沒必要使用 TiDB
總結
以上介紹了 TiDB架構,以及它的一些特性,同時也與 mysql 進行了對比,如果貴司的數據量比較大,正在考慮要分庫分表,那麼完全可以使用它,來避免分庫分表,分庫分表是一個過渡方案,使用分散式資料庫才是終極方案。同時如果貴司的數據量比較小,那麼就沒必要引入了
掃描下麵的二維碼關註我們的微信公眾帳號,在微信公眾帳號中回覆◉加群◉即可加入到我們的技術討論群裡面共同學習。


