
DOM(文檔對象模型)定義了一種訪問和操作文檔的標準。它是一個平臺和語言無關的介面,允許程式和腳本動態訪問和更新文檔的內容、結構和樣式。HTML DOM用於操作HTML文檔,而XML DOM用於操作XML文檔。 HTML DOM示例 通過ID獲取並修改HTML元素的值: <!DOCTYPE html ...
DOM(文檔對象模型)定義了一種訪問和操作文檔的標準。它是一個平臺和語言無關的介面,允許程式和腳本動態訪問和更新文檔的內容、結構和樣式。HTML DOM用於操作HTML文檔,而XML DOM用於操作XML文檔。
HTML DOM示例
通過ID獲取並修改HTML元素的值:
<!DOCTYPE html>
<html>
<head>
<style>
table, th, td {
border: 1px solid black;
border-collapse: collapse;
}
th, td {
padding: 5px;
}
</style>
</head>
<body>
<button type="button" onclick="loadXMLDoc()">獲取我的CD收藏</button>
<br><br>
<table id="demo"></table>
<script>
function loadXMLDoc() {
var xmlhttp = new XMLHttpRequest();
xmlhttp.onreadystatechange = function() {
if (this.readyState == 4 && this.status == 200) {
myFunction(this);
}
};
xmlhttp.open("GET", "cd_catalog.xml", true);
xmlhttp.send();
}
function myFunction(xml) {
var i;
var xmlDoc = xml.responseXML;
var table = "<tr><th>Artist</th><th>Title</th></tr>";
var x = xmlDoc.getElementsByTagName("CD");
for (i = 0; i < x.length; i++) {
table += "<tr><td>" +
x[i].getElementsByTagName("ARTIST")[0].childNodes[0].nodeValue +
"</td><td>" +
x[i].getElementsByTagName("TITLE")[0].childNodes[0].nodeValue +
"</td></tr>";
}
document.getElementById("demo").innerHTML = table;
}
</script>
</body>
</html>
通過標簽名獲取並修改HTML元素的值:
<!DOCTYPE html>
<html>
<body>
<h1>This is a Heading</h1>
<h1>This is another Heading</h1>
<script>
document.getElementsByTagName("h1")[0].innerHTML = "Hello World!";
</script>
</body>
</html>
XML DOM示例
載入XML文件並獲取元素的值:
<!DOCTYPE html>
<html>
<body>
<p id="demo"></p>
<script>
var xhttp = new XMLHttpRequest();
xhttp.onreadystatechange = function() {
if (this.readyState == 4 && this.status == 200) {
myFunction(this);
}
};
xhttp.open("GET", "books.xml", true);
xhttp.send();
function myFunction(xml) {
var xmlDoc = xml.responseXML;
document.getElementById("demo").innerHTML =
xmlDoc.getElementsByTagName("title")[0].childNodes[0].nodeValue;
}
</script>
</body>
</html>
載入XML字元串並獲取元素的值:
<html>
<body>
<p id="demo"></p>
<script>
var text, parser, xmlDoc;
text = "<bookstore><book>" +
"<title>Everyday Italian</title>" +
"<author>Giada De Laurentiis</author>" +
"<year>2005</year>" +
"</book></bookstore>";
parser = new DOMParser();
xmlDoc = parser.parseFromString(text,"text/xml");
document.getElementById("demo").innerHTML =
xmlDoc.getElementsByTagName("title")[0].childNodes[0].nodeValue;
</script>
</body>
</html>
DOM編程介面
DOM的編程介面由一組標準屬性和方法定義。屬性通常用於描述節點的特征,而方法通常用於執行與節點相關的操作。
屬性的例子
x.nodeName- x的名稱x.nodeValue- x的值x.parentNode- x的父節點x.childNodes- x的子節點x.attributes- x的屬性節點
方法的例子
x.getElementsByTagName(name)- 獲取指定標簽名的所有元素x.appendChild(node)- 將一個子節點插入到xx.removeChild(node)- 從x中移除一個子節點
這些屬性和方法使得通過編程可以訪問和操作文檔的各個部分。
XML DOM 節點
根據 XML DOM,XML 文檔中的所有內容都是節點:
- 整個文檔是一個文檔節點
- 每個 XML 元素是一個元素節點
- XML 元素中的文本是文本節點
- 每個屬性是一個屬性節點
- 註釋是註釋節點
DOM 示例
看下麵的 XML 文件(books.xml):
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="children">
<title lang="en">Harry Potter</title>
<author>J.K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="web">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book>
<book category="web" cover="paperback">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
上述 XML 中的根節點命名為 <bookstore>。
文檔中的所有其他節點都包含在 <bookstore> 中。
根節點 <bookstore> 包含了 4 個 <book> 節點。
第一個 <book> 節點包含子節點: <title>、<author>、<year> 和 <price>。
子節點分別包含一個文本節點,內容分別為 "Everyday Italian"、"Giada De Laurentiis"、"2005" 和 "30.00"。
文本始終存儲在文本節點中
在 DOM 處理中常見的錯誤是期望元素節點包含文本。然而,元素節點的文本存儲在文本節點中。
在這個例子中:<year>2005</year>,元素節點 <year> 包含一個值為 "2005" 的文本節點。
"2005" 不是 <year> 元素的值!
XML DOM 節點樹
XML DOM 將 XML 文檔視為樹結構。樹結構被稱為節點樹。
所有節點都可以通過樹訪問。它們的內容可以修改或刪除,並且可以創建新元素。
節點樹顯示了節點集和它們之間的連接。樹從根節點開始,延伸到樹的最低層的文本節點:
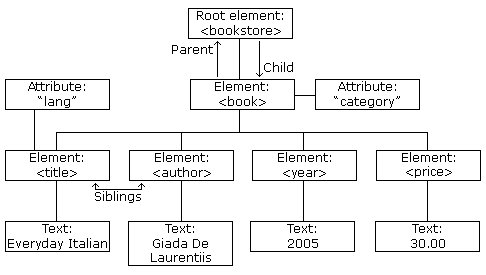
圖像上方代表 XML 文件 books.xml。
節點的父節點、子節點和兄弟姐妹
節點樹中的節點之間存在層次關係。
術語父節點、子節點和兄弟姐妹用於描述這些關係。父節點有子節點。在同一層級上的子節點稱為兄弟姐妹。
- 在節點樹中,頂部節點稱為根節點
- 除了根節點,每個節點都有一個父節點
- 一個節點可以有任意數量的子節點
- 葉子是沒有子節點的節點
- 具有相同父節點的節點稱為兄弟節點
以下圖像說明瞭節點樹的一部分以及節點之間的關係:
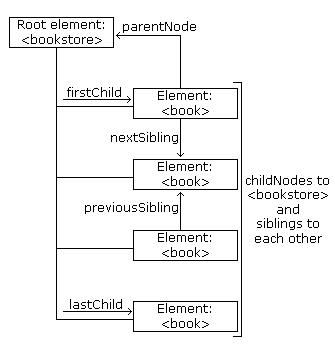
由於 XML 數據是以樹形式結構化的,可以在不知道樹的確切結構和包含的數據類型的情況下遍歷它。
第一個子節點 - 最後一個子節點
看下麵的 XML 片段:
<bookstore>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
</bookstore>
在上述 XML 中,<title> 元素是 <book> 元素的第一個子節點,<price> 元素是 <book> 元素的最後一個子節點。
此外,<book> 元素是 <title>、<author>、<year> 和 <price> 元素的父節點。
XML DOM - 訪問節點
使用 DOM,您可以訪問 XML 文檔中的每個節點。
訪問節點
有三種方式可以訪問節點:
- 使用
getElementsByTagName()方法 - 通過迴圈遍歷節點樹
- 通過導航節點樹,使用節點之間的關係
getElementsByTagName() 方法
getElementsByTagName() 返回具有指定標簽名的所有元素。
語法
node.getElementsByTagName("tagname");
示例
以下示例返回 x 元素下的所有 <title> 元素:
x.getElementsByTagName("title");
註意,上面的示例僅返回 x 節點下的 <title> 元素。要返回 XML 文檔中的所有 <title> 元素,請使用:
xmlDoc.getElementsByTagName("title");
其中 xmlDoc 是文檔本身(文檔節點)。
DOM 節點列表
getElementsByTagName() 方法返回一個節點列表。節點列表是節點的數組。
x = xmlDoc.getElementsByTagName("title");
x 中的 <title> 元素可以通過索引號訪問。要訪問第三個 <title>,您可以這樣寫:
y = x[2];
註意:索引從 0 開始。
DOM 節點列表長度
length 屬性定義了節點列表的長度(節點數)。
您可以通過使用 length 屬性迴圈遍歷節點列表:
var x = xmlDoc.getElementsByTagName("title");
for (i = 0; i < x.length; i++) {
// 對每個節點執行一些操作
}
節點類型
XML 文檔的 documentElement 屬性是根節點。
節點的 nodeName 屬性是節點的名稱。
節點的 nodeType 屬性是節點的類型
遍歷節點
以下代碼迴圈遍歷根節點的子節點,這些子節點也是元素節點:
txt = "";
x = xmlDoc.documentElement.childNodes;
for (i = 0; i < x.length; i++) {
// 僅處理元素節點(類型 1)
if (x[i].nodeType == 1) {
txt += x[i].nodeName + "<br>";
}
}
示例解釋:
- 假設您已經將 "books.xml" 載入到
xmlDoc中 - 獲取根元素(
xmlDoc)的子節點 - 對於每個子節點,檢查節點類型。如果節點類型是 "1",則它是一個元素節點
- 如果它是一個元素節點,則輸出節點的名稱
導航節點關係
以下代碼使用節點之間的關係導航節點樹:
x = xmlDoc.getElementsByTagName("book")[0];
xlen = x.childNodes.length;
y = x.firstChild;
txt = "";
for (i = 0; i < xlen; i++) {
// 僅處理元素節點(類型 1)
if (y.nodeType == 1) {
txt += y.nodeName + "<br>";
}
y = y.nextSibling;
}
示例解釋:
- 假設您已經將 "books.xml" 載入到
xmlDoc中 - 獲取第一個
book元素的子節點 - 將 "y" 變數設置為第一個
book元素的第一個子節點 - 對於每個子節點(從第一個子節點 "y" 開始):
- 檢查節點類型。如果節點類型是 "1",則它是一個元素節點
- 如果它是一個元素節點,則輸出節點的名稱
- 將 "y" 變數設置為下一個兄弟節點,並再次運行迴圈
XML DOM 節點信息
nodeName 屬性
nodeName 屬性指定節點的名稱。
nodeName是只讀的。- 元素節點的
nodeName與標簽名相同。 - 屬性節點的
nodeName是屬性名。 - 文本節點的
nodeName始終是 #text。 - 文檔節點的
nodeName始終是 #document。
nodeValue 屬性
nodeValue 屬性指定節點的值。
- 元素節點的
nodeValue是未定義的。 - 文本節點的
nodeValue是文本本身。 - 屬性節點的
nodeValue是屬性值。
獲取元素的值
以下代碼檢索第一個 <title> 元素的文本節點值:
var x = xmlDoc.getElementsByTagName("title")[0].childNodes[0];
var txt = x.nodeValue;
結果:txt = "Everyday Italian"
示例解釋:
- 假設您已經將
books.xml載入到xmlDoc中。 - 獲取第一個
<title>元素節點的文本節點。 - 將
txt變數設置為文本節點的值。
更改元素的值
以下代碼更改了第一個 <title> 元素的文本節點值:
var x = xmlDoc.getElementsByTagName("title")[0].childNodes[0];
x.nodeValue = "Easy Cooking";
示例解釋:
- 假設您已經將
books.xml載入到xmlDoc中。 - 獲取第一個
<title>元素節點的文本節點。 - 將文本節點的值更改為 "Easy Cooking"。
nodeType 屬性
nodeType 屬性指定節點的類型。
nodeType是只讀的。- 最重要的節點類型是:
- 元素:1
- 屬性:2
- 文本:3
- 註釋:8
- 文檔:9
DOM 屬性列表(命名節點映射)
元素節點的 attributes 屬性返回屬性節點的列表。
這稱為命名節點映射,與節點列表類似,只是在方法和屬性上有一些差異。
屬性列表會自我更新。如果刪除或添加了屬性,列表會自動更新。
此代碼片段從 "books.xml" 中的第一個 <book> 元素返回屬性節點的列表:
x = xmlDoc.getElementsByTagName('book')[0].attributes;
執行上述代碼後,x.length 是屬性的數量,x.getNamedItem() 可用於返回一個屬性節點。
此代碼片段獲取書籍的 "category" 屬性值和屬性列表的數量:
x = xmlDoc.getElementsByTagName("book")[0].attributes;
txt = x.getNamedItem("category").nodeValue + " " + x.length;
輸出:
- cooking 1
示例解釋:
- 假設
books.xml已載入到xmlDoc中。 - 設置
x變數以保存第一個<book>元素的所有屬性的列表。 - 獲取 "category" 屬性的值和屬性列表的長度。
最後
為了方便其他設備和平臺的小伙伴觀看往期文章:
微信公眾號搜索:Let us Coding,關註後即可獲取最新文章推送
看完如果覺得有幫助,歡迎點贊、收藏、關註


