
掌握使用Python進行文本英文統計的基本方法,並瞭解如何進一步優化和擴展這些方法,以應對更複雜的文本分析任務。 ...
本文分享自華為雲社區《Python文本統計與分析從基礎到進階》,作者:檸檬味擁抱。
在當今數字化時代,文本數據無處不在,它們包含了豐富的信息,從社交媒體上的帖子到新聞文章再到學術論文。對於處理這些文本數據,進行統計分析是一種常見的需求,而Python作為一種功能強大且易於學習的編程語言,為我們提供了豐富的工具和庫來實現文本數據的統計分析。本文將介紹如何使用Python來實現文本英文統計,包括單詞頻率統計、辭彙量統計以及文本情感分析等。
單詞頻率統計
單詞頻率統計是文本分析中最基本的一項任務之一。Python中有許多方法可以實現單詞頻率統計,以下是其中一種基本的方法:
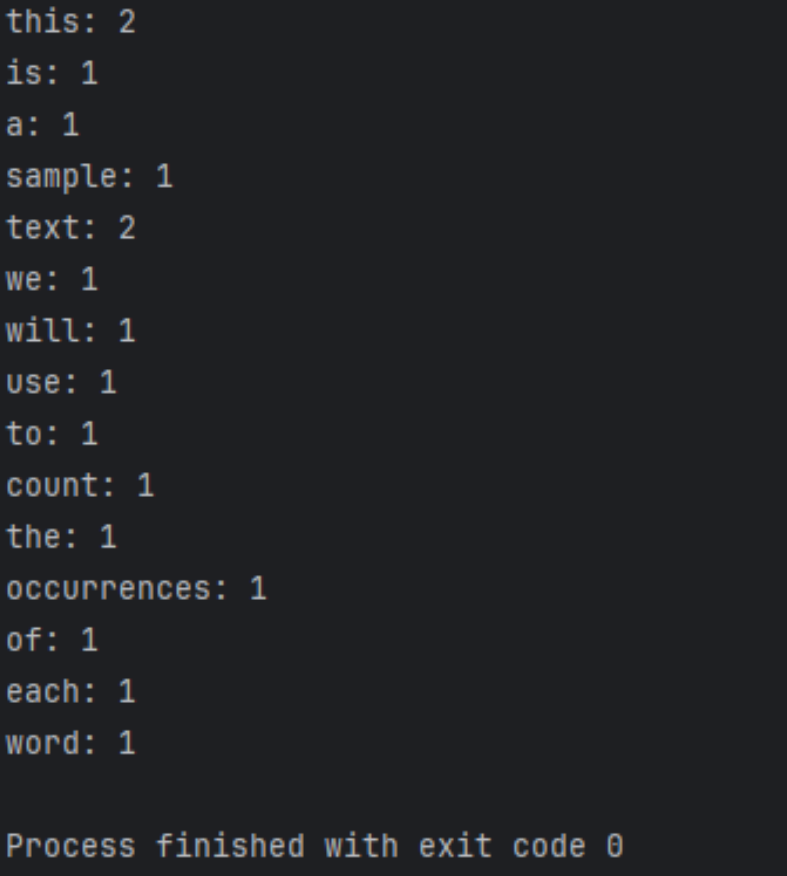
def count_words(text): # 將文本中的標點符號去除並轉換為小寫 text = text.lower() for char in '!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~': text = text.replace(char, ' ') # 將文本拆分為單詞列表 words = text.split() # 創建一個空字典來存儲單詞計數 word_count = {} # 遍歷每個單詞並更新字典中的計數 for word in words: if word in word_count: word_count[word] += 1 else: word_count[word] = 1 return word_count # 測試代碼 if __name__ == "__main__": text = "This is a sample text. We will use this text to count the occurrences of each word." word_count = count_words(text) for word, count in word_count.items(): print(f"{word}: {count}")
這段代碼定義了一個函數 count_words(text),它接受一個文本字元串作為參數,並返回一個字典,其中包含文本中每個單詞及其出現的次數。下麵是對代碼的逐行解析:
def count_words(text)::定義了一個函數 count_words,該函數接受一個參數 text,即要處理的文本字元串。
text = text.lower():將文本字元串轉換為小寫字母,這樣可以使單詞統計不受大小寫影響。
for char in '!"#$%&\'()*+,-./:;<=>?@[\\]^_{|}~’:`:這是一個迴圈,遍歷了文本中的所有標點符號。
text = text.replace(char, ' '):將文本中的每個標點符號替換為空格,這樣可以將標點符號從文本中刪除。
words = text.split():將處理後的文本字元串按空格分割為單詞列表。
word_count = {}:創建一個空字典,用於存儲單詞計數,鍵是單詞,值是該單詞在文本中出現的次數。
for word in words::遍歷單詞列表中的每個單詞。
if word in word_count::檢查當前單詞是否已經在字典中存在。
word_count[word] += 1:如果單詞已經在字典中存在,則將其出現次數加1。
else::如果單詞不在字典中,執行以下代碼。
word_count[word] = 1:將新單詞添加到字典中,並將其出現次數設置為1。
return word_count:返回包含單詞計數的字典。
if __name__ == "__main__"::檢查腳本是否作為主程式運行。
text = "This is a sample text. We will use this text to count the occurrences of each word.":定義了一個測試文本。
word_count = count_words(text):調用 count_words 函數,將測試文本作為參數傳遞,並將結果保存在 word_count 變數中。
for word, count in word_count.items()::遍歷 word_count 字典中的每個鍵值對。
print(f"{word}: {count}"):列印每個單詞和其出現次數。
運行結果如下
進一步優化與擴展
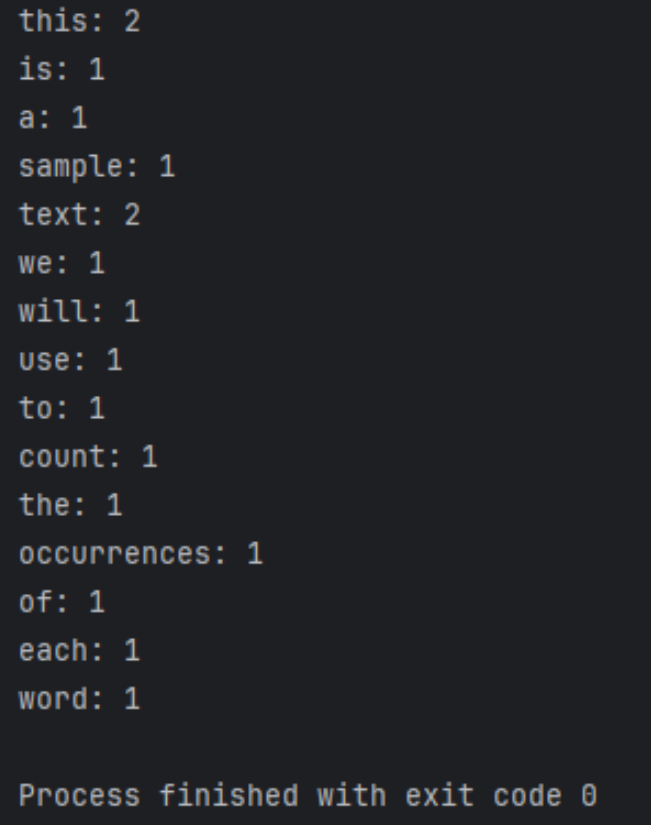
import re from collections import Counter def count_words(text): # 使用正則表達式將文本分割為單詞列表(包括連字元單詞) words = re.findall(r'\b\w+(?:-\w+)*\b', text.lower()) # 使用Counter來快速統計單詞出現次數 word_count = Counter(words) return word_count # 測試代碼 if __name__ == "__main__": text = "This is a sample text. We will use this text to count the occurrences of each word." word_count = count_words(text) for word, count in word_count.items(): print(f"{word}: {count}")
這段代碼與之前的示例相比有以下不同之處:
- 使用了正則表達式
re.findall()來將文本分割為單詞列表。這個正則表達式\b\w+(?:-\w+)*\b匹配單詞,包括連字元單詞(如 “high-tech”)。 - 使用了 Python 標準庫中的
Counter類來進行單詞計數,它更高效,並且代碼更簡潔。
這個實現更加高級,更加健壯,並且處理了更多的特殊情況,比如連字元單詞。
運行結果如下
文本預處理
在進行文本分析之前,通常需要進行文本預處理,包括去除標點符號、處理大小寫、詞形還原(lemmatization)和詞乾提取(stemming)等。這樣可以使得文本數據更加規範化和準確。
使用更高級的模型
除了基本的統計方法外,我們還可以使用機器學習和深度學習模型來進行文本分析,例如文本分類、命名實體識別和情感分析等。Python中有許多強大的機器學習庫,如Scikit-learn和TensorFlow,可以幫助我們構建和訓練這些模型。
處理大規模數據
當面對大規模的文本數據時,我們可能需要考慮並行處理和分散式計算等技術,以提高處理效率和降低計算成本。Python中有一些庫和框架可以幫助我們實現這些功能,如Dask和Apache Spark。
結合其他數據源
除了文本數據外,我們還可以結合其他數據源,如圖像數據、時間序列數據和地理空間數據等,進行更加全面和多維度的分析。Python中有許多數據處理和可視化工具,可以幫助我們處理和分析這些數據。
總結
本文深入介紹瞭如何使用Python實現文本英文統計,包括單詞頻率統計、辭彙量統計以及文本情感分析等。以下是總結:
單詞頻率統計:
- 通過Python函數
count_words(text),對文本進行處理並統計單詞出現的頻率。 - 文本預處理包括將文本轉換為小寫、去除標點符號等。
- 使用迴圈遍歷文本中的單詞,使用字典來存儲單詞及其出現次數。
進一步優化與擴展:
- 引入正則表達式和
Counter類,使代碼更高效和健壯。 - 使用正則表達式將文本分割為單詞列表,包括處理連字元單詞。
- 使用
Counter類進行單詞計數,簡化了代碼。
文本預處理:
文本預處理是文本分析的重要步驟,包括去除標點符號、處理大小寫、詞形還原和詞乾提取等,以規範化文本數據。
使用更高級的模型:
介紹了使用機器學習和深度學習模型進行文本分析的可能性,如文本分類、命名實體識別和情感分析等。
處理大規模數據:
提及了處理大規模文本數據時的技術考量,包括並行處理和分散式計算等,以提高效率和降低成本。
結合其他數據源:
探討了結合其他數據源進行更全面和多維度分析的可能性,如圖像數據、時間序列數據和地理空間數據等。
總結:
強調了本文介紹的內容,以及對未來工作的展望,鼓勵進一步研究和探索,以適應更複雜和多樣化的文本數據分析任務。
通過本文的學習,讀者可以掌握使用Python進行文本英文統計的基本方法,並瞭解如何進一步優化和擴展這些方法,以應對更複雜的文本分析任務。


