
關聯規則的目的就是在一個數據集中找出項與項之間的關係,適用於在大數量的項集中發現關聯共現的項。也被稱為購物籃分析 (Market Basket analysis),因為“購物籃分析”很貼切的表達了適用該演算法情景中的一個子集。購物網站里你買了一個商品,旁邊列出一系列買過該商品的人還買的其他商品,並且按...
@(hadoop)[Spark, MLlib, 數據挖掘, 關聯規則, 演算法]
[TOC]
〇、簡介
經典的關聯規則挖掘演算法包括Apriori演算法和FP-growth演算法。Apriori演算法多次掃描交易資料庫,每次利用候選頻繁集產生頻繁集;而FP-growth則利用樹形結構,無需產生候選頻繁集而是直接得到頻繁集,大大減少掃描交易資料庫的次數,從而提高了演算法的效率。但是apriori的演算法擴展性較好,可以用於並行計算等領域。
關聯規則的目的就是在一個數據集中找出項與項之間的關係,適用於在大數量的項集中發現關聯共現的項。也被稱為購物籃分析 (Market Basket analysis),因為“購物籃分析”很貼切的表達了適用該演算法情景中的一個子集。
購物網站里你買了一個商品,旁邊列出一系列買過該商品的人還買的其他商品,並且按置信度高低排序,一般會發現買手機的還會買充電器(買充電器的人不一定會買手機),買牙刷的還會買牙膏,這大概就是關聯規則的用處。
基礎環境:
CentOS-6.5
JDK-1.7
spark:spark-1.2.0+cdh5.3.6+379
一、Apriori演算法
支持度(Support):定義為
\[supp(X) = \frac{包含X的記錄數}{數據集記錄總數}= P(X)=\frac{occur(X)}{count(D)}\]
置信度(Confidence): 定義為
\[ conf(X=>Y) = \frac{同時包含X和Y的記錄數}{數據集中包含X的記錄數}=P(Y|X)=\frac{P(X \cap Y)}{P(X)} = \frac{occur(X \cap Y)}{occur(X)}\]
FP-growth演算法是Apriori演算法的優化。
二、MLlib實現
spark-1.2.0 版本中Mliib的FPGrowthModel並沒有generateAssociationRules(minConfidence)方法。因此要引用高版本的jar包,併在提交任務時指定才行。這是可以實現的。
Ⅰ、獲取購買歷史數據
下麵共選取了6931條購買歷史記錄,作為關聯規則挖掘的數據集。
1、產生源數據
我們可能需要使用類Mysql中的group_concat()來產生源數據。在Hive中的替代方案是concat_ws()。但若要連接的列是非string型,會報以下錯誤:Argument 2 of function CONCAT_WS must be "string or array<string>", but "array<bigint>" was found.。使用以下hiveSQL可以避免此問題:
SELECT concat_ws(',', collect_set(cast(item_id AS String))) AS items FROM ods_angel_useritem tb GROUP BY tb.user_id;得到item1,item2,item3式數據結構。
數據結構如下所示:
731478,732986,733494
731353
732985,733487,730924
731138,731169
733850,733447
731509,730796,733487
731169,730924,731353
730900
733494,730900,731509
732991,732985,730796,731246,7338502、構造JavaRDD
JavaRDD<List<String>> transactions = ...;Ⅱ、過濾掉出現頻率較低的數據
Java代碼:
//設置頻率(支持率)下限
FPGrowth fpg = new FPGrowth().setMinSupport(0.03).setNumPartitions(10);
FPGrowthModel<String> model = fpg.run(transactions);
List<FPGrowth.FreqItemset<String>> list_freqItem = model.freqItemsets().toJavaRDD().collect();
System.out.println("list_freqItem .size: " + list_freqItem .size());
for (FPGrowth.FreqItemset<String> itemset : list_freqItem) {
System.out.println("[" + itemset.javaItems() + "], " + itemset.freq());
}結果:
[[734902]], 275
[[733480]], 1051
[[734385]], 268
[[733151]], 895
[[733850]], 878
[[733850, 733480]], 339
[[733152]], 266
[[733230]], 243
[[731246]], 500
[[731246, 733480]], 233
[[734888]], 231
[[734894]], 483
[[733487]], 467
[[740697]], 222
[[733831]], 221
[[734900]], 333
[[731353]], 220
[[731169]], 311
[[730924]], 308
[[732985]], 212
[[732994]], 208
[[730900]], 291\[\frac{208}{6931}=0.03001>0.03\],6931是交易的訂單數量,即數據源總條數。
可見,商品732994正好高於支持率下限。
Ⅲ、過濾掉可信度過低的判斷
Java代碼:
double minConfidence = 0.3; //置信下限
List<AssociationRules.Rule<String>> list_rule = model.generateAssociationRules(minConfidence).toJavaRDD().collect();
System.out.println("list_rule.size: " + list_rule.size());
for (AssociationRules.Rule<String> rule : list_rule) {
System.out.println(
rule.javaAntecedent() + " => " + rule.javaConsequent() + ", " + rule.confidence());
}結果:
[733480] => [733850], 0.3225499524262607
[731246] => [733480], 0.466
[733850] => [733480], 0.38610478359908884- \(P(733850|733480)=\frac{occur(733850 \cap 733480)}{occur(733480)}=\frac{339}{1051}=0.3225499524262607\)
- \(P(733480|731246)=\frac{occur(733480 \cap 731246)}{occur(731246)}=\frac{233}{500}=0.466\)
- \(P(733480|733850)=\frac{occur(733850 \cap 733480)}{occur(733850)}=\frac{339}{878}=0.38610478359908884\)
以上表明,用戶在購買商品733480後往往還會購買商品733480,可信度為0.3225499524262607;用戶在購買商品731246後往往還會購買商品731246,可信度為0.466;用戶在購買商品733850後往往還會購買商品733480,可信度為0.38610478359908884。
三、提交任務
Ⅰ、Spark On Standalone
spark-submit --master spark://node190:7077 --class com.angel.mlib.FPGrowthTest --jars lib/hbase-client-0.98.6-cdh5.3.6.jar,lib/hbase-common-0.98.6-cdh5.3.6.jar,lib/hbase-protocol-0.98.6-cdh5.3.6.jar,lib/hbase-server-0.98.6-cdh5.3.6.jar,lib/htrace-core-2.04.jar,lib/zookeeper.jar,lib/spark-mllib_2.10-1.5.2.jar,lib/spark-core_2.10-1.5.2.jar spark-test-1.0.jar
Ⅱ、Spark On Yarn
spark-submit --master yarn-client --class com.angel.mlib.FPGrowthTest --jars lib/hbase-client-0.98.6-cdh5.3.6.jar,lib/hbase-common-0.98.6-cdh5.3.6.jar,lib/hbase-protocol-0.98.6-cdh5.3.6.jar,lib/hbase-server-0.98.6-cdh5.3.6.jar,lib/htrace-core-2.04.jar,lib/zookeeper.jar,lib/spark-mllib_2.10-1.5.2.jar,lib/spark-core_2.10-1.5.2.jar spark-test-1.0.jar
四、FPGrowth演算法在現實中的應用調優
在實際情況中,真實的業務數據處處都是雜訊。活用數據,設計有業務含義的特征體系,是構造魯棒模型的基礎!
具體的解決辦法,我們可以多演算法並用,這些將在後續的aitanjupt文章中詳述。
五、綜上所述
也就是說,“購買了該寶貝的人32%還購買了某某商品”就是使用商品關聯規則挖掘實現的;還有一些捆綁銷售,例如牙膏和牙刷一起賣,尿布和啤酒放在一起賣。
關聯規則挖掘演算法不只是能用在商品銷售,使用它我們可以挖掘出更多的關聯關係,比如我們可以挖掘出,溫度、天氣、性別等等與心情之間是否有關聯關係,這是非常有意義的。
關聯規則挖掘演算法應用場景非常龐大,遙記多年前做的手機用戶關聯分析,那時尚未用到關聯規則挖掘演算法,用的是自己編寫的類join演算法,現在看起來,關聯規則挖掘演算法是再適合不過的了。

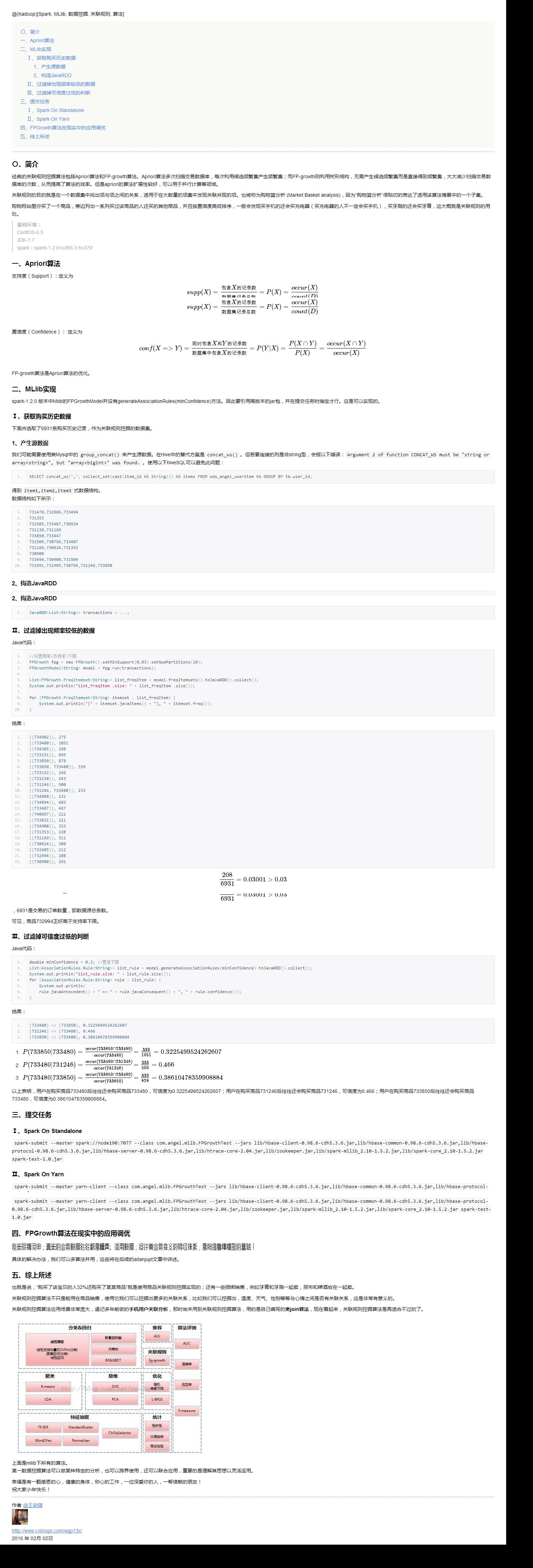
上面是mllib下所有的演算法。
某一數據挖掘演算法可以做某種特定的分析,也可以跨界使用,還可以聯合應用,重要的是理解其思想以靈活運用。
幸福是有一顆感恩的心,健康的身體,稱心的工作,一位深愛你的人,一幫信賴的朋友!
祝大家小年快樂!
作者 @王安琪

http://www.cnblogs.com/wgp13x/
2016 年 02月 02日


