
進程啟動順序 Oracle Grid Infrastructure由OS初始化守護程式啟動 操作系統初始化守護進程(init)->Grid Infrastructure包裝腳本(init.ohasd)->Grid Infrastructure守護程式和進程(ohasd.bin,oraagent.bi ...
進程啟動順序 Oracle Grid Infrastructure由OS初始化守護程式啟動 操作系統初始化守護進程(init)->Grid Infrastructure包裝腳本(init.ohasd)->Grid Infrastructure守護程式和進程(ohasd.bin,oraagent.bin,orarootagent.bin,diskmon.bin,cssdagent,ocssd.bin)->ASM實例、監聽程式、DB實例、用戶定義的應用程式
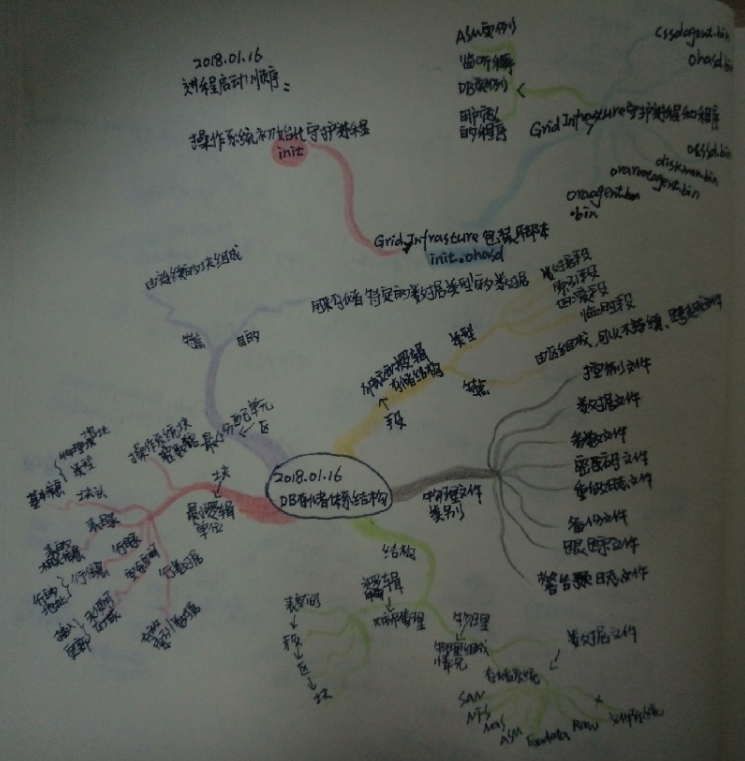 資料庫存儲體繫結構
構成Oracle資料庫的文件類別
控制文件:資料庫物理結構信息和備份相關的元數據。
數據文件:資料庫用戶或應用程式數據,以及元數據和數據字典。
聯機重做日誌文件:用於進行資料庫的實例恢復。
參數文件:用於定義實例啟動時的配置。
口令文件:允許用戶使用sysdba、sysoper和sysasm角色遠程連接到實例並管理。
備份文件:用於進行資料庫恢復。
歸檔重做日誌文件:包含實例發生的數據更改(重做)的實時歷史記錄。使用這些文件和資料庫備份,可以恢復丟失的數據文件。
跟蹤文件:每個伺服器和後臺進程都可以寫入一個關聯的跟蹤文件。當進程檢測到內部錯誤時,會將有關該錯誤的信息轉儲到相應的跟蹤文件中。
預警日誌文件:改文件包含特殊的跟蹤條目。資料庫的預警日誌是一個按時間順序記錄消息和錯誤的日誌。
邏輯和物理資料庫結構
邏輯結構(用於展示oracle在操作系統中的物理文件組成情況):資料庫->表空間->段->區->Oracle數據塊
物理結構(用於描述oracle內部組織和管理數據的方式):數據文件->存儲系統(SAN,NFS,NAS,ASM,Exadata,RAW,文件系統)
數據塊(Data Blocks):是Oracle邏輯存儲結構中最小的邏輯單位,也是執行資料庫輸入輸出的最小存儲單位。 Oracle數據塊是操作系統塊的整數倍,Oracle數據塊有一定的標準大小(DB_BLOCK_SIZE);另外Oracle支持在同一個資料庫中使用多種大小的塊,與標準塊大小不同的就是非標準塊;
Oracle數據塊結構:塊頭、表目錄、行目錄、空餘空間和行數據
塊頭:存放數據塊的基本信息,如塊的物理地址、塊所屬的段的類型。
表目錄:存放表的相關信息。
行目錄:如果塊中有行數據存在,則這些行的信息將被記錄在行目錄中,這些信息包括行的地址。
空餘空間:空餘空間是一個塊中未使用的區域,這片區域用於新行的插入和已經存在的行的更新。
行數據:用於存放表數據和索引數據的地方,這部分空間已被數據行所占用。
通常將塊頭、表目錄、行目錄這3個部分組合起來稱為頭部信息,頭部信息區不存放數據,它存放整個塊的引導信息,起到引導系統讀取數據的作用。所以頭部信息若遭到破壞,則Oracle系統無法讀取這部分數據。空餘空間和行數據共同構成塊的存儲區,用於存放真正的數據。
數據區(Extent):也稱做數據擴展區是由一組連續的Oracle數據塊所構成的Oracle存儲結構,一個或多個數據塊組成一個數據區,一個或多個數據區組成一個段(Segment),當段(Segment)空間不足時Oracle系統會自動為該段分配一個新的數據區。數據區是Oracle存儲分配的最小單位。
使用數據區的目的:用來保存特定的數據類型的數據。
數據區是表中數據增長的基本單位,在Oracle資料庫中,分配存儲空間就是以數據區為單位的。一個Oracle對象包含至少一個數據區。設置一個表或索引的存儲參數包含設置它的數據區大小。
段(Segment):由一個或多個數據區組成,它不是存儲空間的分配單位,而是一個獨立的邏輯存儲結構,用於存儲表、索引或簇等占用空間的數據對象,Oracle也把這種占用空間的數據對象統一稱為段。
段是為特定的數據對象(如表、索引、回滾等)分配的一系列數據區。段內的數據區可以不連續,並且可以跨越多個文件。
使用段的目的:用來保存特定對象。
數據段:數據段中保存的是表中的數據記錄,在創建數據表時,Oracle系統將為表創建數據段。當表中的數據量增大時,數據段的大小自然也隨著變化,數據段的增大過程是通過向其添加數據區來實現的。當創建一個表時,系統自動創建一個以該表的名字命名的數據段。
索引段:索引段中包含了用於提高系統性能的索引。一旦建立索引,系統自動創建一個以該索引的名字命名的索引段。
回滾段:也稱撤銷段,它保存了回滾條目,Oracle將修改前的舊值保存在回滾條目中。
臨時段:當執行創建索引、查詢等操作時,Oracle可能會使用一些臨時存儲空間,用於暫時性地保存解析過的查詢語句以及在排序過程中產生的臨時數據。
執行“Create Index”、“Select Order By”、“Select Distinct”、“Select Group By”等幾種類型的sql語句時,Oracle系統就會在臨時表空間中為這些語句的操作分配一個臨時段。在資料庫管理過程中,若經常需要執行上面這類sql語句,最好調整sort_area_size初始化參數來增大排序區,從而使排序操作儘量在記憶體中完成,以獲取更好的效率,但同時這對資料庫伺服器的記憶體空間提出了更大的要求。
資料庫存儲體繫結構
構成Oracle資料庫的文件類別
控制文件:資料庫物理結構信息和備份相關的元數據。
數據文件:資料庫用戶或應用程式數據,以及元數據和數據字典。
聯機重做日誌文件:用於進行資料庫的實例恢復。
參數文件:用於定義實例啟動時的配置。
口令文件:允許用戶使用sysdba、sysoper和sysasm角色遠程連接到實例並管理。
備份文件:用於進行資料庫恢復。
歸檔重做日誌文件:包含實例發生的數據更改(重做)的實時歷史記錄。使用這些文件和資料庫備份,可以恢復丟失的數據文件。
跟蹤文件:每個伺服器和後臺進程都可以寫入一個關聯的跟蹤文件。當進程檢測到內部錯誤時,會將有關該錯誤的信息轉儲到相應的跟蹤文件中。
預警日誌文件:改文件包含特殊的跟蹤條目。資料庫的預警日誌是一個按時間順序記錄消息和錯誤的日誌。
邏輯和物理資料庫結構
邏輯結構(用於展示oracle在操作系統中的物理文件組成情況):資料庫->表空間->段->區->Oracle數據塊
物理結構(用於描述oracle內部組織和管理數據的方式):數據文件->存儲系統(SAN,NFS,NAS,ASM,Exadata,RAW,文件系統)
數據塊(Data Blocks):是Oracle邏輯存儲結構中最小的邏輯單位,也是執行資料庫輸入輸出的最小存儲單位。 Oracle數據塊是操作系統塊的整數倍,Oracle數據塊有一定的標準大小(DB_BLOCK_SIZE);另外Oracle支持在同一個資料庫中使用多種大小的塊,與標準塊大小不同的就是非標準塊;
Oracle數據塊結構:塊頭、表目錄、行目錄、空餘空間和行數據
塊頭:存放數據塊的基本信息,如塊的物理地址、塊所屬的段的類型。
表目錄:存放表的相關信息。
行目錄:如果塊中有行數據存在,則這些行的信息將被記錄在行目錄中,這些信息包括行的地址。
空餘空間:空餘空間是一個塊中未使用的區域,這片區域用於新行的插入和已經存在的行的更新。
行數據:用於存放表數據和索引數據的地方,這部分空間已被數據行所占用。
通常將塊頭、表目錄、行目錄這3個部分組合起來稱為頭部信息,頭部信息區不存放數據,它存放整個塊的引導信息,起到引導系統讀取數據的作用。所以頭部信息若遭到破壞,則Oracle系統無法讀取這部分數據。空餘空間和行數據共同構成塊的存儲區,用於存放真正的數據。
數據區(Extent):也稱做數據擴展區是由一組連續的Oracle數據塊所構成的Oracle存儲結構,一個或多個數據塊組成一個數據區,一個或多個數據區組成一個段(Segment),當段(Segment)空間不足時Oracle系統會自動為該段分配一個新的數據區。數據區是Oracle存儲分配的最小單位。
使用數據區的目的:用來保存特定的數據類型的數據。
數據區是表中數據增長的基本單位,在Oracle資料庫中,分配存儲空間就是以數據區為單位的。一個Oracle對象包含至少一個數據區。設置一個表或索引的存儲參數包含設置它的數據區大小。
段(Segment):由一個或多個數據區組成,它不是存儲空間的分配單位,而是一個獨立的邏輯存儲結構,用於存儲表、索引或簇等占用空間的數據對象,Oracle也把這種占用空間的數據對象統一稱為段。
段是為特定的數據對象(如表、索引、回滾等)分配的一系列數據區。段內的數據區可以不連續,並且可以跨越多個文件。
使用段的目的:用來保存特定對象。
數據段:數據段中保存的是表中的數據記錄,在創建數據表時,Oracle系統將為表創建數據段。當表中的數據量增大時,數據段的大小自然也隨著變化,數據段的增大過程是通過向其添加數據區來實現的。當創建一個表時,系統自動創建一個以該表的名字命名的數據段。
索引段:索引段中包含了用於提高系統性能的索引。一旦建立索引,系統自動創建一個以該索引的名字命名的索引段。
回滾段:也稱撤銷段,它保存了回滾條目,Oracle將修改前的舊值保存在回滾條目中。
臨時段:當執行創建索引、查詢等操作時,Oracle可能會使用一些臨時存儲空間,用於暫時性地保存解析過的查詢語句以及在排序過程中產生的臨時數據。
執行“Create Index”、“Select Order By”、“Select Distinct”、“Select Group By”等幾種類型的sql語句時,Oracle系統就會在臨時表空間中為這些語句的操作分配一個臨時段。在資料庫管理過程中,若經常需要執行上面這類sql語句,最好調整sort_area_size初始化參數來增大排序區,從而使排序操作儘量在記憶體中完成,以獲取更好的效率,但同時這對資料庫伺服器的記憶體空間提出了更大的要求。

