
hadoop的核心組件:hdfs(分散式文件系統)、mapreduce(分散式計算框架)、Hive(基於hadoop的數據倉庫)、HBase(分散式列存資料庫)、Zookeeper(分散式協作服務)、Sqoop(數據同步工具)和Flume(日誌手機工具) hdfs(分散式文件系統): 由client ...
hadoop的核心組件:hdfs(分散式文件系統)、mapreduce(分散式計算框架)、Hive(基於hadoop的數據倉庫)、HBase(分散式列存資料庫)、Zookeeper(分散式協作服務)、Sqoop(數據同步工具)和Flume(日誌手機工具) hdfs(分散式文件系統): 由client、NameNode、DataNode組成
- client負責切分文件,並與NameNode交互,獲取文件位置;與DataNode交互,讀取和寫入數據
- NameNode是Master節點,管理HDFS的名稱空間和數據塊映射信息,配置副本策略,處理客戶端請求
- DataNode是Slave節點,存儲實際數據,彙報存儲信息給NameNode
- DataNode與NameNode保持心跳,提交block列表
- 只存在記憶體中
- 持久化
- 啟動後, 元數據(metadate)信息載入到記憶體
- metadata的磁碟文件名為”fsimage”
- Block的位置信息不會保存到fsimage
- (journalNode的作用是存放EditLog的)edits記錄對metadata的操作日誌
- 接收客戶端讀寫
- 收集DataNode彙報的block列表信息
- 文件ownership, permissions(文件所有權、許可權)
- 文件大小, 時間
- (block列表,block偏移量)--->會持久化, 位置信息--->不會持久化(啟動時候由DataNode彙報過來)
- block每個副本位置(dataNode上報)
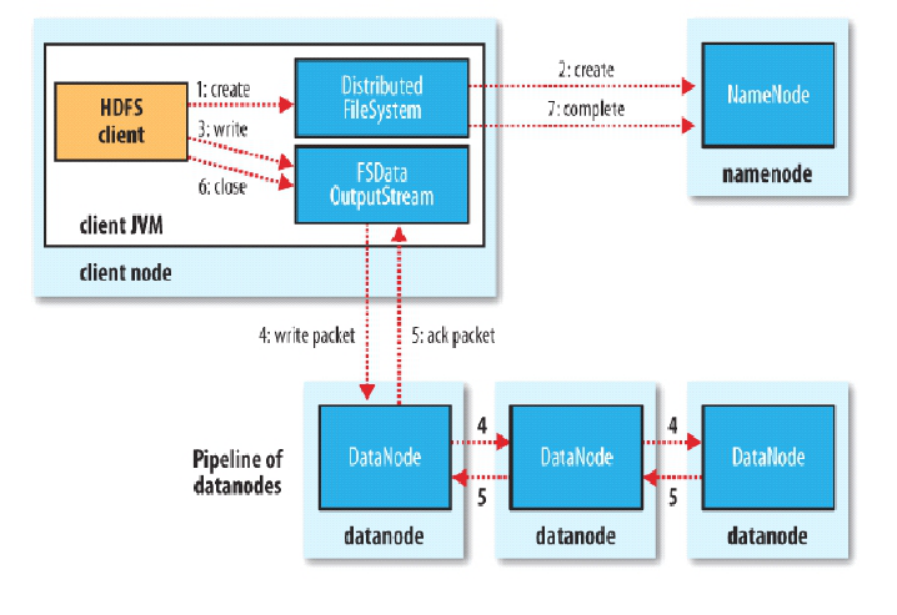
client切分文件與NanmeNode交互,獲取DataNode列表,驗證DataNode後連接DataNode,各節點之間兩兩交互,確定可用後, client以更小單位流式傳輸數據; Block傳輸數據結束後,DataNode向NameNode彙報Block信息,DataNode向Client彙報完成,Client向NameNode彙報完成,獲 取去下一個Block存放的DataNode列表,迴圈以上步驟,最終client彙報完成,NameNode會在寫流程更新文件狀態。 hdfs讀流程
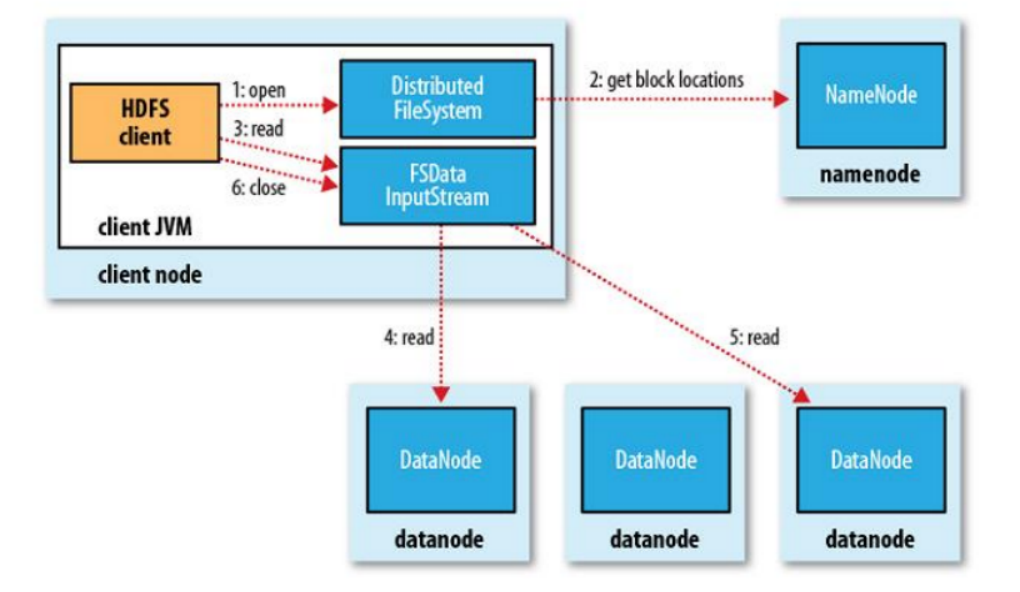 client與NameNode交互,獲取Block存放的DataNode列表(Block副本的位置信息),線性和DataNode交互,獲取Block,最終
合併為一個文件,其中,在Block副本列表中按距離擇優選取DataNode節點獲取Block塊。
mapreduce(分散式計算框架)
client與NameNode交互,獲取Block存放的DataNode列表(Block副本的位置信息),線性和DataNode交互,獲取Block,最終
合併為一個文件,其中,在Block副本列表中按距離擇優選取DataNode節點獲取Block塊。
mapreduce(分散式計算框架)

MR運行原理:
1、客戶端提交作業之前,檢查輸入輸出路徑,首先創建切片列表 反射出作業中設置的input對象,預設是TextInputFormat類 通過input類得到切片列表(getSpilits()方法) 最小值 minSize 預設為1,如果設置就取設置的值 最大值 maxSize 預設為long的最大值 根據輸入路徑取出文件,獲取每個文件的所有block列表,接著創建splits列表(包含文件名,偏移量,長度和位置信息) 切片大小根據最大最小值取,預設為block的大小 一個split對應一個map 提交作業到集群(submitJob()方法) 2、mapInput: input.initialize 輸入初始化 拿到taskContext(上下文) 創建mapper(預設為Mapper類,一般取用戶設置的) 獲取InputFomat類(輸入格式化的類) 獲取split 根據以上信息創建input(NewTrackingRecordReader) input初始化 獲取split的開始和結束位置和文件,開啟對文件的IO流,將起始偏移量個IO設置一下 如果不是第一個切片(split),每次讀取放棄第一行(跳過第一行數據),只有第一個切片才會讀取第一行數據 mapper.run 3、output: MapOutputBuffer初始化 環形緩衝區的閾值0.8、大小(100M) 預設值 sorter :QuickSort演算法 反射獲取比較器 OutputKeyComparator 排序,溢寫,一些一次觸發一次combiner 溢寫達到3次的時候還會觸發一次combiner 通過反射獲取Partitioner類,預設為HashPartitoner write(k,v) collector.collect(key,value,partition) output.close() merger 如果numSplits<minSpillsForCombiner 判斷溢寫的次數是不是小於設置的合併的溢寫次數(預設是3),成立的話combiner 4、reduce: shuffle:copy sort:SecondarySort reduce 1、mapreduce shuffle (1)maptask的輸入是hdfs上的block塊,maptask只讀取split,block與split的對應關係預設是一對一 (2)進過map端的運行後,輸出的格式為key/value,Mapreduce提供介面partition,他的作用是根據maptask輸出的key hash後與 reduce數量取模,來決定當前的輸出對應到哪個reduce處理,也可以自定義partition (3)map運行後的數據序列化到緩衝區,預設這個緩衝區大小為100M,作用是收集這個map的結果,當數據達到溢寫比例 (預設是spill.percent=0.8)後,所定這80M的記憶體,對這80M記憶體中的key做排序(sort),maptask的輸出結果還可以往剩下的20M內 存中寫,互不影響。之後執行溢寫的線程會往磁碟中寫數據。每次溢寫都會產生一個溢寫小文件,map執行完後,會合併這些溢寫小文件, 這個過程叫Merge。 (4)如果客戶端設置了Combiner,那麼會優化MapReduce的中間結果,合併map端的數據(相當於reduce端的預處理),Combiner 不能改變最終的計算結果。 (5)reduce在執行之前就是從各個maptask執行完後的溢寫文件中拿到所對應的數據,然後做合併(Merge),最終形成的文件作為 reduce的輸入文件,這個過程是歸併排序。最後就是reduce計算,把結果放到hdfs上面。 hdfs參數調優| io.file.buffer.size:4096 (core-default.xml) | SequenceFiles在讀寫中可以使用緩存大小,可減少I/O次數;在大型Hadoop cluster,建議可設定為65536-131072 |
| dfs.blockes:134217728( hdfs-default.xml ) | hdfs中一個文件的Block塊的大小,CDH5中預設為128M;設置太大影響map同時計算的數量,設置較少會浪費map個數資源 |
| mapred.reduce.tasks(mapreduce.job.reduces):1 | 預設啟動的reduce數 |
| mapreduce.task.io.sort.factor:10 | reduce task中合併文件時,一次合併的文件數據 |
| mapred.child.java.opts:-Xmx200m | jvm啟動子線程可以使用的最大記憶體 |
| mapred.reduce.parallel.copies:5 | Reduce copy數據的線程數量,預設值是5 |
| mapreduce.tasktracker.http.threads:40 | map和reduce是通過http進行傳輸的,這個設置傳輸的並行線程數 |
| mapreduce.map.output.compress:flase | map輸出是否進行壓縮,如果壓縮就會多耗cpu,但是減少傳輸時間,如果不壓縮,就需要較多的傳輸帶寬。配合 mapreduce.map.output.compress.codec使用,預設是 org.apache.hadoop.io.compress.DefaultCodec,可以根據需要設定數據壓縮方式。 |
| mapreduce.tasktracker.tasks.reduce.maximum:2 | 一個tasktracker併發執行的reduce數,建議為cpu核數 |
| mapreduce.map.sort.spill.percent:0.8 | 溢寫比例 |
| min.num.spill.for.combine:3 | spill的文件達到設置的參數進行combiner |
| mapred.map.tasks.speculative.execution=true |
| mapred.reduce.tasks.speculative.execution=true |


