
本文由 網易雲 發佈。 作者:範鵬程,網易考拉海購 目錄 InnoDB表結構 B樹與B+樹 聚簇索引和二級索引 SQL執行順序 SQL優化建議 一些問題分析 參考資料 1. InnoDB表結構 此小結與索引其實沒有太多的關聯,但是為了便於理解索引的內容,添加此小結作為鋪墊知識。 1.1 InnoDB ...
本文由 網易雲 發佈。
作者:範鵬程,網易考拉海購
InnoDB是 MySQL最常用的存儲引擎,瞭解InnoDB存儲引擎的索引對於日常工作有很大的益處,索引的存在便是為了加速資料庫行記錄的檢索。以下是我對最近學習的知識的一些總結,以及對碰到的以及別人提到過的問題的一些分析,如有錯誤,請指正,我會及時更正。
目錄
InnoDB表結構
B樹與B+樹
聚簇索引和二級索引
SQL執行順序
SQL優化建議
一些問題分析
參考資料
1. InnoDB表結構
此小結與索引其實沒有太多的關聯,但是為了便於理解索引的內容,添加此小結作為鋪墊知識。
1.1 InnoDB邏輯存儲結構
MySQL表中的所有數據被存儲在一個空間內,稱之為表空間,表空間內部又可以分為段(segment)、區(extent)、頁(page)、行(row),邏輯結構如下圖:

- 段(segment)
表空間是由不同的段組成的,常見的段有:數據段,索引段,回滾段等等,在 MySQL中,數據是按照B+樹來存儲,因此數據即索引,因此數據段即為B+樹的葉子節點,索引段為B+樹的非葉子節點,回滾段用於存儲undo日誌,用於事務失敗後數據回滾以及在事務未提交之前通過undo日誌獲取之前版本的數據,在InnoDB1.1版本之前一個InnoDB,只支持一個回滾段,支持1023個併發修改事務同時進行,在InnoDB1.2版本,將回滾段數量提高到了128個,也就是說可以同時進行128*1023個併發修改事務。
- 區(extent)
區是由連續頁組成的空間,每個區的固定大小為1MB,為保證區中頁的連續性,InnoDB會一次從磁碟中申請4~5個區,在預設不壓縮的情況下,一個區可以容納64個連續的頁。但是在開始新建表的時候,空表的預設大小為96KB,是由於為了高效的利用磁碟空間,在開始插入數據時表會先利用32個頁大小的碎片頁來存儲數據,當這些碎片使用完後,表大小才會按照MB倍數來增加。
- 頁(page)
頁是InnoDB存儲引擎的最小管理單位,每頁大小預設是16KB,從InnoDB 1.2.x版本開始,可以利用innodb_page_size來改變頁size,但是改變只能在初始化InnoDB實例前進行修改,之後便無法進行修改,除非mysqldump導出創建新庫,常見的頁類型有:數據頁、undo頁、系統頁、事務數據頁、插入緩衝點陣圖頁、插入緩衝空閑列表頁、未壓縮的二進位大對象頁、壓縮的二進位大對象頁。
- 行(row)
行對應的是表中的行記錄,每頁存儲最多的行記錄也是有硬性規定的最多16KB/2-200,即7992行(16KB是頁大小,我也不明白為什麼要這麼算,據說是內核定義)
1.2 InnoDB行記錄格式
InnoDB提供了兩種格式來存儲行記錄:Redundant格式、Compact格式、Dynamic格式、Compressed格式,Redudant格式是為了相容保留的。
Redundant行格式(5.0版本之前的格式)

- 欄位長度偏移列表:存儲欄位偏移量,與列欄位順序相反存放,若列長度小於255位元組,用一個位元組表示,若大於255位元組,用兩個位元組表示
- 記錄頭信息:固定用6位元組表示,具體含義如下:
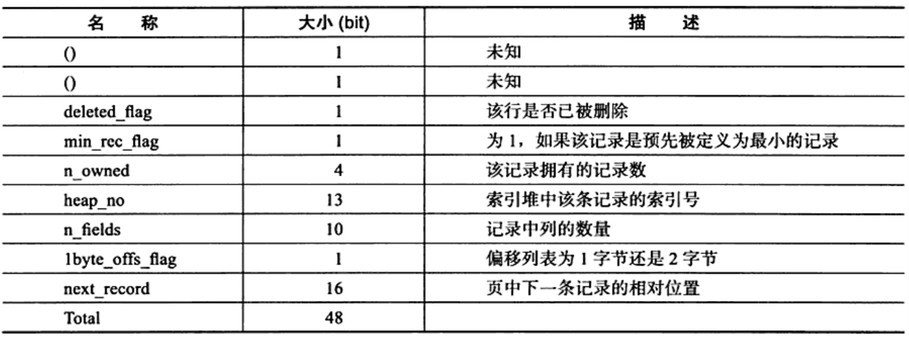
隱藏列:事務id和回滾列id,分別占用6、7位元組,若此表沒有主鍵,還會增加6位元組的rowid列。
Compact行格式(5.6版本的預設行格式)

- 變長欄位長度列表:此欄位標識列欄位的長度,與列欄位順序相反存放,若列長度小於255位元組,用一個位元組表示,若大於255位元組,用兩個位元組表示,這也是 MySQL的VARCHAR類型最大長度限製為65535
- NULL標誌位:標識改列是否有空欄位,有用1表示,否則為0,該標誌位長度為ceil(N/8)(此處是 MySQL技術內幕-InnoDB存儲引擎與官方文檔有出入的地方);
- 記錄頭信息:固定用5位元組表示,具體含義如下:

- 列數據:此行存儲著列欄位數據,Null是不占存儲空間的;
- 隱藏列:事務id和回滾列id,分別占用6、7位元組,若此表沒有主鍵,還會增加6位元組的rowid列。
Note: 關於行溢出,即Redundant格式、Compact格式存儲很長的字元串,在該欄位會存儲該字元串的前768個位元組的首碼(欄位超過768位元組則為變長欄位),並將整個字元串存儲在uncompress blob頁中。
Dynamic格式(5.7版本預設行格式)和Compressed格式
Dynamic格式和Compressed格式與Compact的不同之處在於對於行溢出只會在該列處存放20位元組的指針,指向該字元串的實際存儲位置,不會存儲768位元組首碼,而且Compressed格式在存儲BLOB、TEXT、VARCHAR等類型會利用zlib演算法進行壓縮,能夠以很高的存儲效率來存儲字元串。
1.3 InnoDB數據頁結構
《 MySQL技術內幕-InnoDB存儲引擎》書中對此有描述,但是應該不是太準確,書中有如下描述,此處不做詳細介紹,若有興趣請看此神書。

2. B樹與B+樹
B樹與B+樹通常用於資料庫和操作系統的文件系統中。NTFS, ReiserFS, NSS, XFS, JFS, ReFS 和BFS等文件系統都在使用B+樹作為元數據索引。B+ 樹的特點是能夠保持數據穩定有序,其插入與修改擁有較穩定的對數時間複雜度。
2.1 B樹
定義:
B樹(B-TREE)滿足如下條件,即可稱之為m階B樹:
- 每個節點之多擁有m棵子樹;
- 根結點至少擁有兩顆子樹(存在子樹的情況下);
- 除了根結點以外,其餘每個分支結點至少擁有 m/2 棵子樹;
- 所有的葉結點都在同一層上;
- 有 k 棵子樹的分支結點則存在 k-1 個關鍵碼,關鍵碼按照遞增次序進行排列;
- 關鍵字數量需要滿足ceil(m/2)-1 <= n <= m-1;
B樹插入
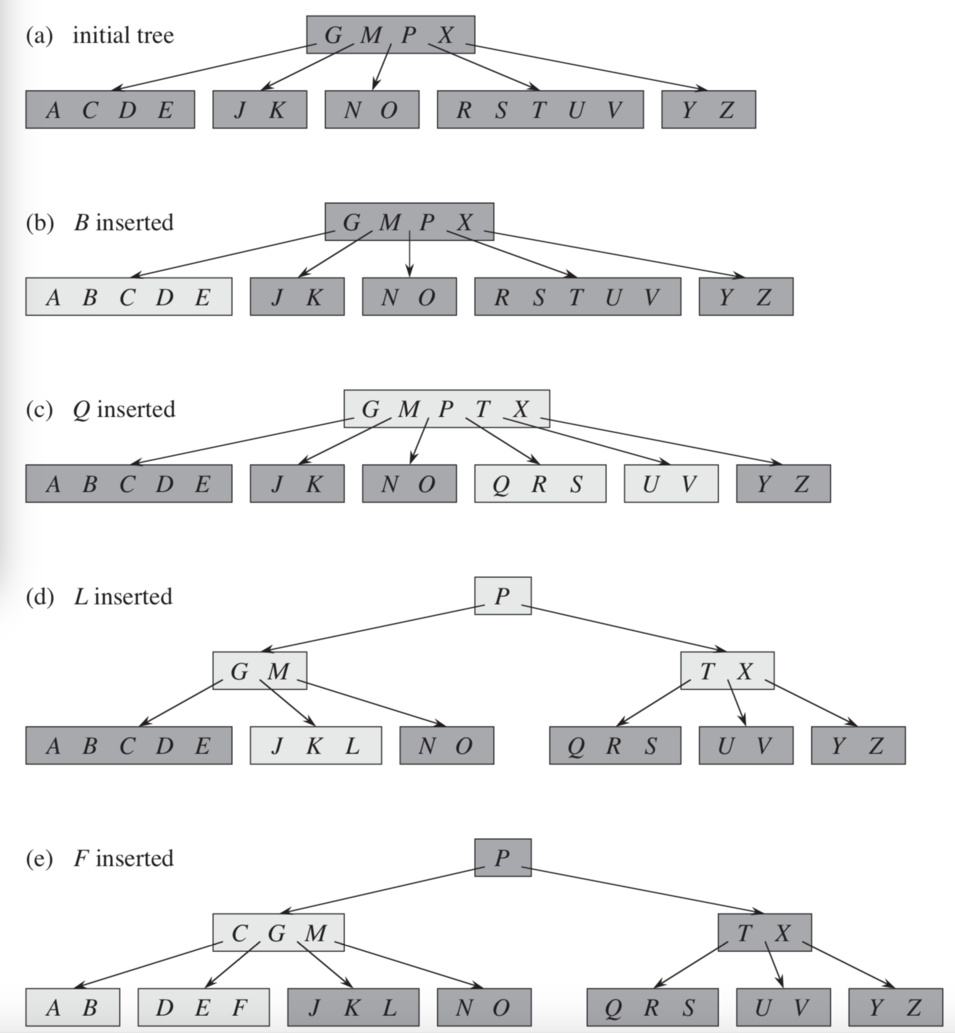
B樹刪除
2.2 B+樹
定義:
B+樹滿足如下條件,即可稱之為m階B+樹:
- 根結點只有一個,分支數量範圍為[2,m]
- 分支結點,每個結點包含分支數範圍為[ceil(m/2), m];
- 分支結點的關鍵字數量等於其子分支的數量減一,關鍵字的數量範圍為[ceil(m/2)-1, m-1],關鍵字順序遞增;
- 所有葉子結點都在同一層;
插入:
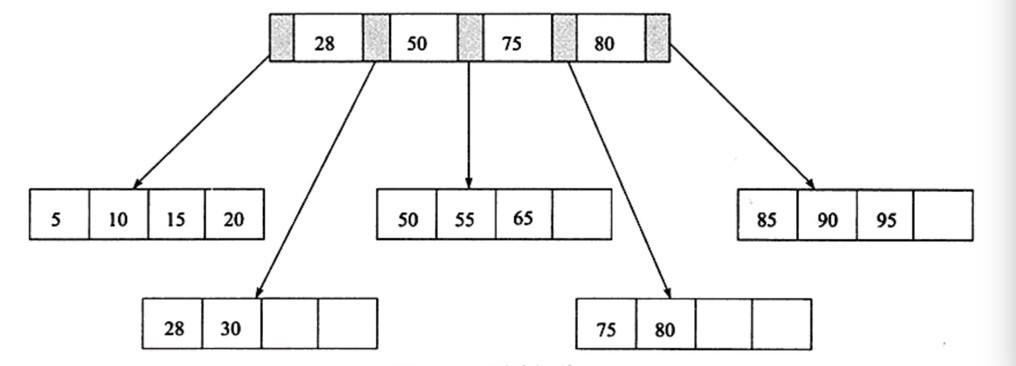
B+樹的插入必須保證插入後葉節點中的記錄依然排序,同時需要考慮插入B+樹的三種情況,每種情況都可能會導致不同的插入演算法,插入演算法入下圖:
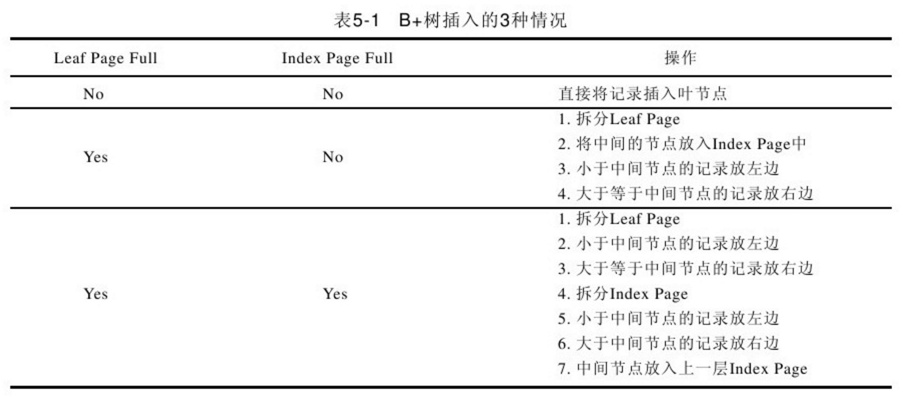
插入舉例(未加入雙向鏈表):
1、 插入28這個鍵值,發現當前Leaf Page和Index Page都沒有滿,直接插入。
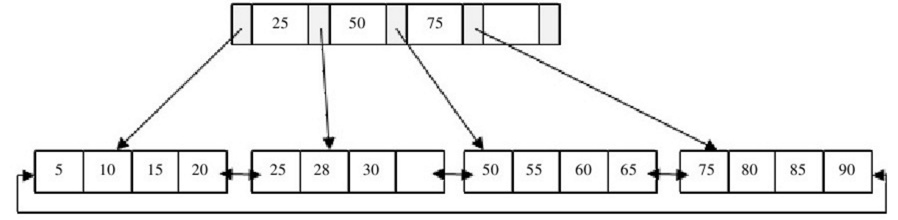
2、 插入70這個鍵值,Leaf Page已經滿了,但是Index Page還沒有滿,根據中間的值60拆分葉節點。

3、 插入記錄95,Leaf Page和Index Page都滿了,這時需要做兩次拆分
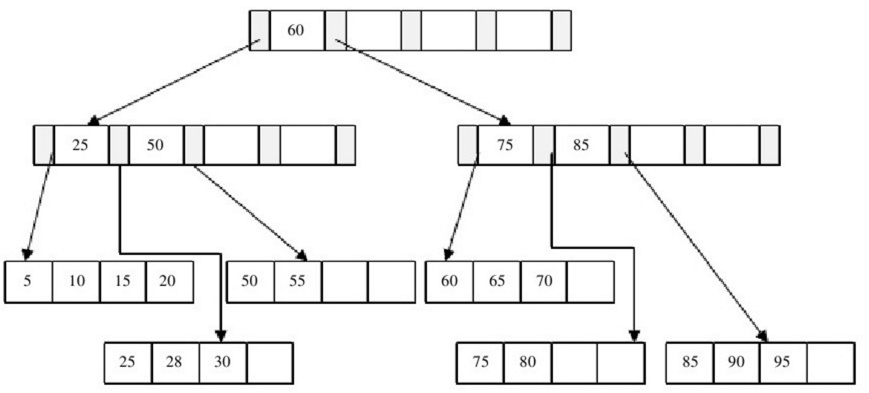
4、 B+樹總是會保持平衡。但是為了保持平衡,對於新插入的鍵值可能需要做大量的拆分頁(split)操作,而B+樹主要用於磁碟,因此頁的拆分意味著磁碟數據移動,應該在可能的情況下儘量減少頁的拆分。因此,B+樹提供了旋轉(rotation)的功能。旋轉發生在Leaf Page已經滿了、但是其左右兄弟節點沒有滿的情況下。這時B+樹並不會急於去做拆分頁的操作,而是將記錄移到所在頁的兄弟節點上。通常情況下,左兄弟被首先檢查用來做旋轉操作,在第一張圖情況下,插入鍵值70,其實B+樹並不會急於去拆分葉節點,而是做旋轉,50,55,55旋轉。

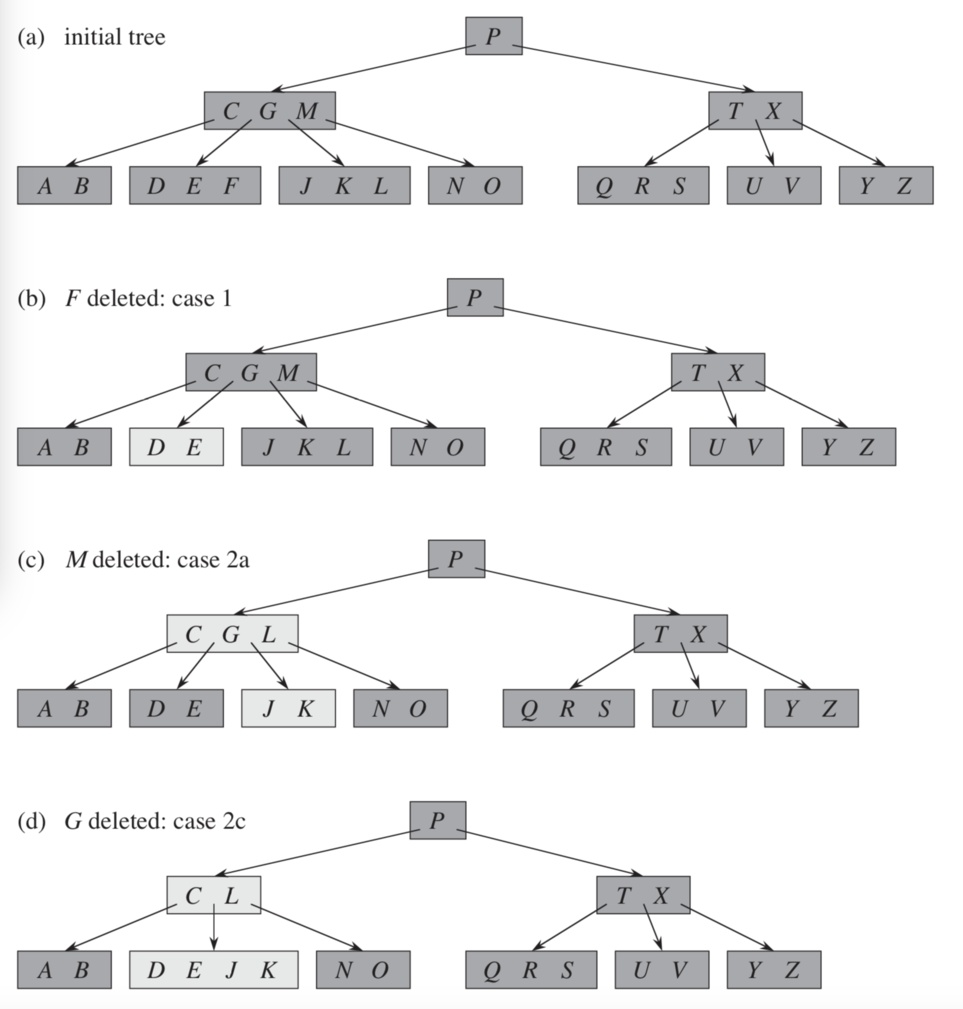
刪除:
B+樹使用填充因數(fill factor)來控制樹的刪除變化,50%是填充因數可設的最小值。B+樹的刪除操作同樣必須保證刪除後葉節點中的記錄依然排序,同插入一樣,B+樹的刪除操作同樣需要考慮下圖所示的三種情況,與插入不同的是,刪除根據填充因數的變化來衡量。

刪除示例(未加入雙向鏈表):
1、刪除鍵值為70的這條記錄,直接刪除(在插入第三點基礎上的圖)。
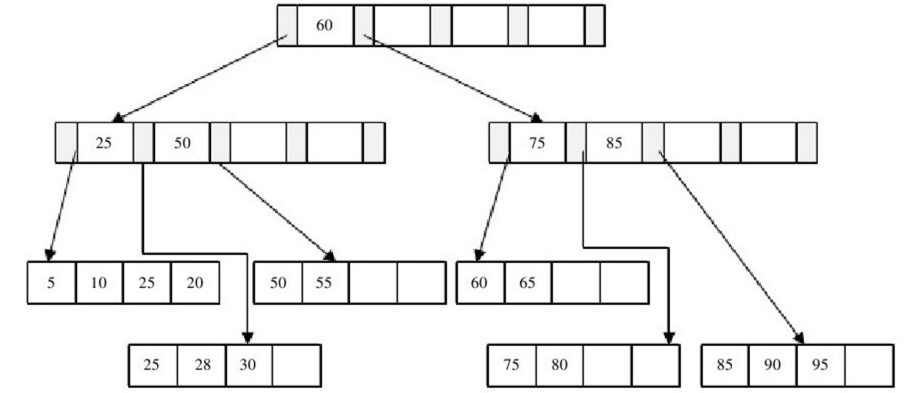
2、接著我們刪除鍵值為25的記錄,該值還是Index Page中的值,因此在刪除Leaf Page中25的值後,還應將25的右兄弟節點的28更新到Page Index中。
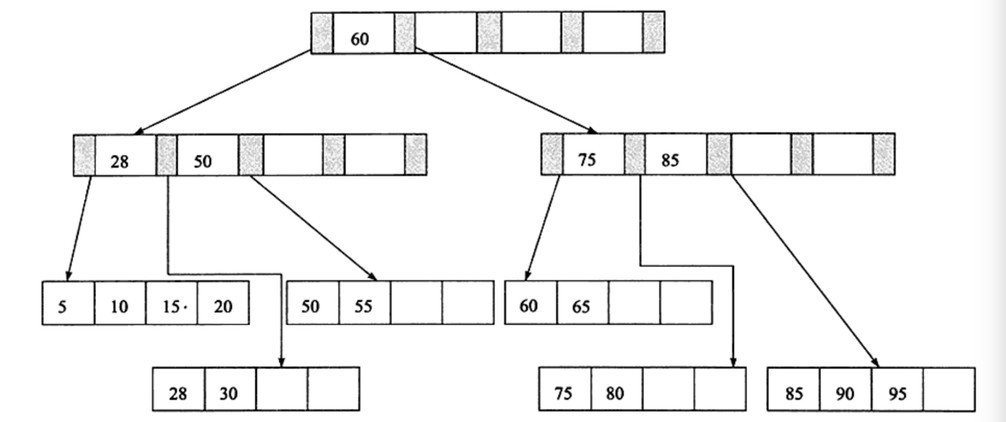
3、刪除鍵值為60的情況,刪除Leaf Page中鍵值為60的記錄後,填充因數小於50%,這時需要做合併操作,同樣,在刪除Index Page中相關記錄後需要做Index Page的合併操作。
B樹與B+樹區別:
以m階樹為例:
- 關鍵字不同:B+樹中分支結點有m個關鍵字,其葉子結點也有m個,但是B樹雖然也有m個子結點,但是其只擁有m-1個關鍵字。
- 存儲位置不同:B+樹非葉子節點的關鍵字只起到索引作用,實際的關鍵字存儲在葉子節點,B樹的非葉子節點也存儲關鍵字。
- 分支構造不同:B+樹的分支結點僅僅存儲著關鍵字信息和兒子的指針,也就是說內部結點僅僅包含著索引信息。
- 查詢不同(穩定):B樹在找到具體的數值以後,則結束,而B+樹則需要通過索引找到葉子結點中的數據才結束,也就是說B+樹的搜索過程中走了一條從根結點到葉子結點的路徑。
3. 聚簇索引和二級索引
3.1 聚簇索引
每個InnoDB的表都擁有一個索引,稱之為聚簇索引,此索引中存儲著行記錄,一般來說,聚簇索引是根據主鍵生成的。為了能夠獲得高性能的查詢、插入和其他資料庫操作,理解InnoDB聚簇索引是很有必要的。
聚簇索引按照如下規則創建:
- 當定義了主鍵後,InnoDB會利用主鍵來生成其聚簇索引;
- 如果沒有主鍵,InnoDB會選擇一個非空的唯一索引來創建聚簇索引;
- 如果這也沒有,InnoDB會隱式的創建一個自增的列來作為聚簇索引。
Note: 對於選擇唯一索引的順序是按照定義唯一索引的順序,而非表中列的順序, 同時選中的唯一索引欄位會充當為主鍵,或者InnoDB隱式創建的自增列也可以看做主鍵。
聚簇索引整體是一個b+樹,非葉子節點存放的是鍵值,葉子節點存放的是行數據,稱之為數據頁,這就決定了表中的數據也是聚簇索引中的一部分,數據頁之間是通過一個雙向鏈表來鏈接的,上文說到B+樹是一棵平衡查找樹,也就是聚簇索引的數據存儲是有序的,但是這個是邏輯上的有序,但是在實際在數據的物理存儲上是,因為數據頁之間是通過雙向鏈表來連接,假如物理存儲是順序的話,那維護聚簇索引的成本非常的高。
3.2 輔助索引
除了聚簇索引之外的索引都可以稱之為輔助索引,與聚簇索引的區別在於輔助索引的葉子節點中存放的是主鍵的鍵值。一張表可以存在多個輔助索引,但是只能有一個聚簇索引,通過輔助索引來查找對應的航記錄的話,需要進行兩步,第一步通過輔助索引來確定對應的主鍵,第二步通過相應的主鍵值在聚簇索引中查詢到對應的行記錄,也就是進行兩次B+樹搜索。相反通過輔助索引來查詢主鍵的話,遍歷一次輔助索引就可以確定主鍵了,也就是所謂的索引覆蓋,不用回表(查詢聚簇索引)。
創建輔助索引,可以創建單列的索引,也就是用一個欄位來創建索引,也可以用多個欄位來創建副主索引稱為聯合索引,創建聯合索引後,B+樹的節點存儲的鍵值數量不是1個,而是多個,如下圖:
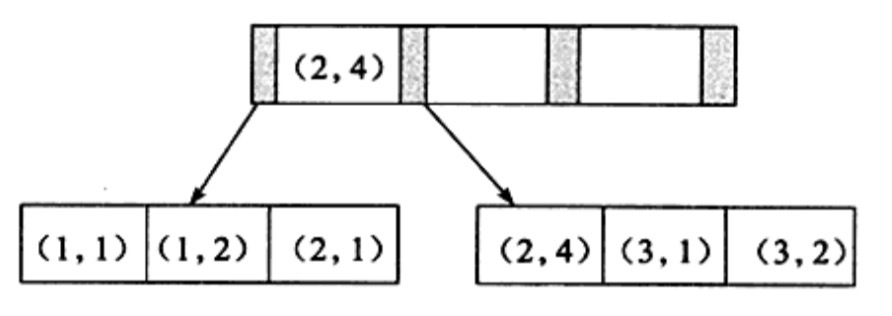
- 聯合索引的B+樹和單鍵輔助索引的B+樹是一樣的,鍵值都是排序的,通過葉子節點可以邏輯順序的讀出所有的數據,比如上圖所存儲的數據時,按照(a,b)這種形式(1,1),(1,2),(2,1),(2,4),(3,1),(3,2)進行存放,這樣有個好處存放的數據時排了序的,當進行
order by對某個欄位進行排序時,可以減少複雜度,加速進行查詢; - 當用
select * from table where a=? and ?可以使用索引(a,b)來加速查詢,但是在查詢時有一個原則,sql的where條件的順序必須和二級索引一致,而且還遵循索引最左原則,select * from table where b=?則無法利用(a,b)索引來加速查詢。 - 輔助索引還有一個概念便是索引覆蓋,索引覆蓋的一個好處便是輔助索引不高含行記錄,因此其大小遠遠小於聚簇索引,利用輔助索引進行查詢可以減少大量的IO操作。
4. SQL執行順序
以下的每一步操作都會生成一個虛擬表,作為下一個處理的輸入,在這個過程中,這些虛擬表對於用戶都是透明的,只用最後一步執行完的虛擬表返回給用戶,在處理過程中,沒有的步驟會直接跳過。
以下為邏輯上的執行順序:

(1) from:對左表left-table和右表right-table執行笛卡爾積(a*b),形成虛擬表VT1;
(2) on: 對虛擬表VT1進行on條件進行篩選,只有符合條件的記錄才會插入到虛擬表VT2中;
(3) join: 指定out join會將未匹配行添加到VT2產生VT3,若有多張表,則會重覆(1)~(3);
(4) where: 對VT3進行條件過濾,形成VT4, where條件是從左向右執行的;
(5) group by: 對VT4進行分組操作得到VT5;
(6) cube | rollup: 對VT5進行cube | rollup操作得到VT6;
(7) having: 對VT6進行過濾得到VT7;
(8) select: 執行選擇操作得到VT8,本人看來VT7和VT8應該是一樣的;
(9) distinct: 對VT8進行去重,得到VT9;
(10) order by: 對VT9進行排序,得到VT10;
(11) limit: 對記錄進行截取,得到VT11返回給用戶。
Note: on條件應用於連表過濾,where應用於on過濾後的結果(有on的話),having應用於分組過濾
5. SQL優化建議
索引有如下有點:減少伺服器掃描的數據量、避免排序和臨時表、將隨機I/O變為順序I/O。
可使用B+樹索引的查詢方式
- 全值匹配:與索引中的所有列進行匹配,也就是條件欄位與聯合索引的欄位個數與順序相同;
- 匹配最左首碼:只使用聯合索引的前幾個欄位;
- 匹配列首碼:比如like 'xx%'可以走索引;
- 匹配範圍值:範圍查詢,比如>,like等;
- 匹配某一列並範圍匹配另外一列:精確查找+範圍查找;
- 只訪問索引查詢:索引覆蓋,select的欄位為主鍵;
範圍查詢後的條件不會走索引,具體原因會在下一節進行介紹。
列的選擇性(區分度)
選擇性(區分度)是指不重覆的列值個數/列值的總個數,一般意義上建索引的欄位要區分度高,而且在建聯合索引的時候區分度高的列欄位要放在前邊,這樣可以在第一個條件就過濾掉大量的數據,有利用性能的提升,對於如何計算列的區分度,有如下兩種方法:
- 根據定義,手動計算列的區分度,不重覆的列值個數/列值的總個數;
- 通過 MySQL的carlinality,通過命令
show index from <table_name>來查看,解釋一下,此處的carlinality並不是準確值,而且 MySQL在B+樹種選擇了8個數據頁來抽樣統計的值,也就是說carlinality=每個數據頁記錄總和/8*所有的數據頁,因此也說明這個值是不准確的,因為在插入/更新記錄時,實時的去更新carlinality對於 MySQL的負載是很高的,如果數據量很大的話,觸發 MySQL重新統計該值得條件是當表中的1/16數據發生變化時。
但是選擇區分度高的列作為索引也不是百試百靈的,某些情況還是不合適的,下節會進行介紹。
MySQL查詢過程
當希望 MySQL能夠高性能運行的時候,最好的辦法就是明白 MySQL是如何優化和執行的,一旦理解了這一點,很多查詢優化工作實際上就是遵循了一些原則讓優化器能夠按照預想的合理的方式運行————《引用自高性能 MySQL 》
當想 MySQL實例發送一個請求時, MySQL按照如下圖的方式進行查詢:
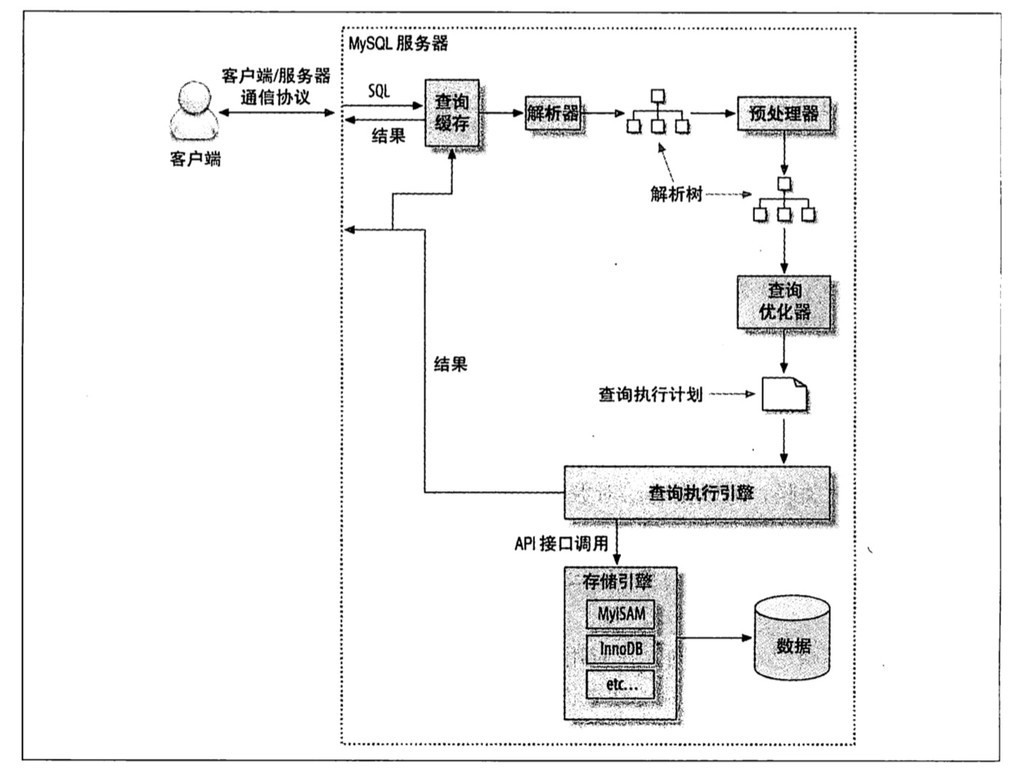
- 客戶端先發送一條查詢給伺服器;
- 伺服器先檢查查詢緩存,如果命中了緩存,則立刻返回給存儲在緩存中的結果,否則進入下一個階段;
- 伺服器端進行SQL解析、預處理,再由優化器生成對應的執行計劃;
- MySQL 根據優化器生成的執行計劃,調用存儲引擎的API來執行查詢;
- 將結果返回客戶端。
註意&建議
- 主鍵推薦使用整型,避免索引分裂;
- 查詢使用索引覆蓋能夠提升很大的性能,因為避免了回表查詢;
- 選擇合適的順序建立索引,有的場景並非區分度越高的列欄位放在前邊越好,聯合索引使用居多;
- 合理使用in操作將範圍查詢轉換成多個等值查詢;
- in操作相當於多個等值操作,但是要註意的是對於order by來說,這相當於範圍查詢,因此例如select * from t1 where c1 in (x,x) order by c2的sql是不走索引的;
- 將大批量數據查詢任務分解為分批查詢;
- 將複雜查詢轉換為簡單查詢;
- 合理使用inner join,比如說分頁時候。
6. 一些問題分析
這個部分是我在學習過程中產生的一些疑問,以及在工作中碰到的或者同事提起的一些問題,對此我做了些調研,總結了一下並添加了些自己的理解,如有錯誤還請指正。
索引分裂
此處提一下索引分裂,就我個人理解,在 MySQL插入記錄的同時會更新配置的相應索引文件,根據以上的瞭解,在插入索引時,可能會存在索引的頁的分裂,因此會導致磁碟數據的移動。當插入的主鍵是隨機字元串時,每次插入不會是在B+樹的最後插入,每次插入位置都是隨機的,每次都可能導致數據頁的移動,而且字元串的存儲空間占用也很大,這樣重建索引不僅僅效率低而且 MySQL的負載也會很高,同時還會導致大量的磁碟碎片,磁碟碎片多了也會對查詢造成一定的性能開銷,因為存儲位置不連續導致更多的磁碟I/O,這就是為什麼推薦定義主鍵為遞增整型的一個原因, MySQL索引頁預設大小是16KB,當有新紀錄插入的時候, MySQL會留下每頁空間的1/16用於未來索引記錄增長,避免過多的磁碟數據移動。
自增主鍵的弊端
對於高併發的場景,在InnoDB中按照主鍵的順序插入可能會造成明顯的爭用,主鍵的上界會成為“熱點”,因為所有的插入都發生在此處,索引併發的插入可能會造成間隙鎖競爭,何為間隙鎖競爭,下個會詳細介紹;另外一個原因可能是Auto_increment的鎖機制,在 MySQL處理自增主鍵時,當innodb_autoinc_lock_mode為0或1時,在不知道插入有多少行時,比如insert t1 xx select xx from t2,對於這個statement的執行會進行鎖表,只有這個statement執行完以後才會釋放鎖,然後別的插入才能夠繼續執行,但是在innodb_autoinc_lock_mode=2時,這種情況不會存在表鎖,但是只能保證所有併發執行的statement插入的記錄是唯一併且自增的,但是每個statement做的多行插入之間是不連接的。
優化器不使用索引選擇全表掃描
比如一張order表中有聯合索引(order_id, goods_id),在此例子上來說明這個問題是從兩個方面來說:
- 查詢欄位在索引中
select order_id from order where order_id > 1000,如果查看其執行計劃的話,發現是用use index condition,走的是索引覆蓋。
- 查詢欄位不在索引中
select * from order where order_id > 1000, 此條語句查詢的是該表所有欄位,有一部分欄位並未在此聯合索引中,因此走聯合索引查詢會走兩步,首先通過聯合索引確定符合條件的主鍵id,然後利用這些主鍵id再去聚簇索引中去查詢,然後得到所有記錄,利用主鍵id在聚簇索引中查詢記錄的過程是無序的,在磁碟上就變成了離散讀取的操作,假如當讀取的記錄很多時(一般是整個表的20%左右),這個時候優化器會選擇直接使用聚簇索引,也就是掃全表,因為順序讀取要快於離散讀取,這也就是為何一般不用區分度不大的欄位單獨做索引,註意是單獨因為利用此欄位查出來的數據會很多,有很大概率走全表掃描。
範圍查詢之後的條件不走索引
根據 MySQL的查詢原理的話,當處理到where的範圍查詢條件後,會將查詢到的行全部返回到伺服器端(查詢執行引擎),接下來的條件操作在伺服器端進行處理,這也就是為什麼範圍條件不走索引的原因了,因為之後的條件過濾已經不在存儲引擎完成了。但是在 MySQL 5.6以後假如了一個新的功能index condition pushdown(ICP),這個功能允許範圍查詢條件之後的條件繼續走索引,但是需要有幾個前提條件:
- 查詢條件的第一個條件需要時有邊界的,比如
select * from xx where c1=x and c2>x and c3<x,這樣c3是可以走到索引的; - 支持InnoDB和MyISAM存儲引擎;
- where條件的欄位需要在索引中;
- 分表ICP功能5.7開始支持;
- 使用索引覆蓋時,ICP不起作用。
set @@optimizer_switch = "index_condition_pushdown=on" 開啟ICP set @@optimizer_switch = "index_condition_pushdown=off" 關閉ICP
範圍查詢統計函數不遵循 MySQL索引最左原則
比如創建一個表:
create table `person`(
`id` int not null auto_increment primary key,
`uid` int not null,
`name` varchar(60) not null,
`time` date not null,
key `idx_uid_date` (uid, time)
)engine=innodb default charset=utf8mb4;
當執行select count(*) from person where time > '2018-03-11' and time < '2018-03-16'時,time是可以用到idx_uid_date`的索引的,看如下的執行計劃:

其中extra標識use index說明是走索引覆蓋的,一般意義來說是 MySQL是無法支持鬆散索引的,但是對於統計函數,是可以使用索引覆蓋的,因此 MySQL的優化器選擇利用該索引。
分頁offset值很大性能問題
在 MySQL中,分頁當offset值很大的時候,性能會非常的差,比如limit 100000, 20,需要查詢100020條數據,然後取20條,拋棄前100000條,在這個過程中產生了大量的隨機I/O,這是性能很差的原因,為瞭解決這個問題,切入點便是減少無用數據的查詢,減少隨機I/O。 解決的方法是利用索引覆蓋,也就是掃描索引得到id然後再從聚簇索引中查詢行記錄,我知道有兩種方式:
比如從表t1中分頁查詢limit 1000000,5
- 利用inner join
select * from t1 inner join (select id from t1 where xxx order by xx limit 1000000,5) as t2 using(id),子查詢先走索引覆蓋查得id,然後根據得到的id直接取5條得數據。
- 利用範圍查詢條件來限制取出的數據
select * from t1 where id > 1000000 order by id limit 0, 5,即利用條件id > 1000000在掃描索引是跳過1000000條記錄,然後取5條即可,這種處理方式的offset值便成為0了,但此種方式通常分頁不能用,但是可以用來分批取數據。
索引合併
SELECT * FROM tbl_name WHERE key1 = 10 OR key2 = 20;
SELECT * FROM tbl_name WHERE (key1 = 10 OR key2 = 20) AND non_key=30;
SELECT * FROM t1, t2 WHERE (t1.key1 IN (1,2) OR t1.key2 LIKE 'value%') AND t2.key1=t1.some_col;
SELECT * FROM t1, t2 WHERE t1.key1=1 AND (t2.key1=t1.some_col OR t2.key2=t1.some_col2);
對於如上的sql在 MySQL 5.0版本之前,假如沒有建立相應的聯合索引,是要走全表掃描的,但是在 MySQL 5.1後引入了一種優化策略為索引合併,可以在一定程度上利用表上的多個單列索引來定位指定行,其原理是將對每個索引的掃描結果做運算,總共有:交集、並集以及他們的組合,但是索引合併並非是一種合適的選擇,因為在做索引合併時可能會消耗大量的CPU和記憶體資源,一般用到索引合併的情況也從側面反映了該表的索引需要優化。
7. 參考資料
- 《 MySQL技術內幕-InnoDB存儲引擎》:此書對於InnoDB的講解是比較全面而且細緻的,但是稍微有一點點老並且還有一點點錯誤地方,此書是基於 MySQL 5.6版本的,裡邊會混雜一些5.7的知識。
- 《 MySQL技術內幕:SQL編程》:值得一看。
- 《高性能 MySQL 第三版》:此書是一本 MySQL神書,裡邊有很多的 MySQL優化建議以及一些案例。
- 官方文檔:這個是比較權威而且是最新的文檔,缺點是篇幅很長,內容很多,而且還是純英文,在理解和閱讀速度上相對而言沒有中文來得快。
延伸閱讀:
瞭解 網易雲 :
網易雲官網:https://www.163yun.com/
新用戶大禮包:https://www.163yun.com/gift
網易雲社區:https://sq.163yun.com/


