
推薦閱讀: 論主數據的重要性(正確理解元數據、數據元) CDC+ETL實現數據集成方案 Java實現impala操作kudu 實戰kudu集成impala impala基本介紹 impala是cloudera提供的一款高效率的sql查詢工具,提供實時的查詢效果,官方測試性能比hive快10到100倍 ...
推薦閱讀:
impala基本介紹
impala是基於hive的大數據分析查詢引擎,直接使用hive的元資料庫metadata,意味著impala元數據都存儲在hive的metastore當中,並且impala相容hive的絕大多數sql語法。所以需要安裝impala的話,必須先安裝hive,保證hive安裝成功,並且還需要啟動hive的metastore服務
impala是cloudera提供的一款高效率的sql查詢工具,提供實時的查詢效果,官方測試性能比hive快10到100倍,其sql查詢比sparkSQL還要更加快速,號稱是當前大數據領域最快的查詢sql工具,
impala是參照谷歌的新三篇論文(Caffeine--網路搜索引擎、Pregel--分散式圖計算、Dremel--互動式分析工具)當中的Dremel實現而來,其中舊三篇論文分別是(BigTable,GFS,MapReduce)分別對應我們即將學的HBase和已經學過的HDFS以及MapReduce。
impala是基於hive並使用記憶體進行計算,兼顧數據倉庫,具有實時,批處理,多併發等優點
Kudu與Apache Impala (孵化)緊密集成,impala天然就支持相容kudu,允許開發人員使用Impala的SQL語法從Kudu的tablets 插入,查詢,更新和刪除數據;
impala的優點
1、 impala比較快,非常快,特別快,因為所有的計算都可以放入記憶體當中進行完成,只要你記憶體足夠大
2、 擯棄了MR的計算,改用C++來實現,有針對性的硬體優化
3、 具有數據倉庫的特性,對hive的原有數據做數據分析
4、支持ODBC,jdbc遠程訪問
impala的缺點
1、基於記憶體計算,對記憶體依賴性較大
2、改用C++編寫,意味著維護難度增大
3、基於hive,與hive共存亡,緊耦合
4、穩定性不如hive,不存在數據丟失的情況
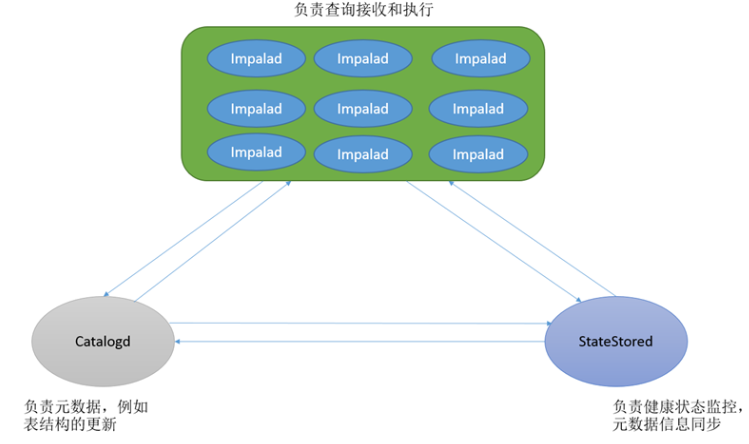
impala的架構以及查詢計劃
-
Impalad
-
基本是每個DataNode上都會啟動一個Impalad進程,Impalad主要扮演兩個角色:
-
Coordinator:
- 負責接收客戶端發來的查詢,解析查詢,構建查詢計劃
- 把查詢子任務分發給很多Executor,收集Executor返回的結果,組合後返回給客戶端
- 對於客戶端發送來的DDL,提交給Catalogd處理
-
Executor:
- 執行查詢子任務,將子任務結果返回給Coordinator
-
Coordinator:
-
基本是每個DataNode上都會啟動一個Impalad進程,Impalad主要扮演兩個角色:
-
Catalogd
- 整個集群只有一個Catalogd,負責所有元數據的更新和獲取
-
StateStored
- 整個集群只有一個Statestored,作為集群的訂閱中心,負責集群不同組件的信息同步
- 跟蹤集群中的Impalad的健康狀態及位置信息,由statestored進程表示,它通過創建多個線程來處理Impalad的註冊訂閱和與各Impalad保持心跳連接,各Impalad都會緩存一份State Store中的信息,當State Store離線後(Impalad發現State Store處於離線時,會進入recovery模式,反覆註冊,當State Store重新加入集群後,自動恢復正常,更新緩存數據)因為Impalad有State Store的緩存仍然可以工作,但會因為有些Impalad失效了,而已緩存數據無法更新,導致把執行計劃分配給了失效的Impalad,導致查詢失敗。
使用impala操作kudu整合
1、需要先啟動hdfs、hive、kudu、impala
2、使用impala的shell控制台
- 執行命令impala-shell
(1):使用該impala-shell命令啟動Impala Shell 。預設情況下,impala-shell 嘗試連接到localhost埠21000 上的Impala守護程式。要連接到其他主機,請使用該-i <host:port>選項。要自動連接到特定的Impala資料庫,請使用該-d <database>選項。例如,如果您的所有Kudu表都位於資料庫中的Impala中impala_kudu,則-d impala_kudu可以使用此資料庫。
(2):要退出Impala Shell,請使用以下命令: quit;

創建kudu表
內部表由Impala管理,當您從Impala中刪除時,數據和表確實被刪除。當您使用Impala創建新表時,它通常是內部表。
- 使用impala創建內部表:
CREATE TABLE my_first_table ( id BIGINT, name STRING, PRIMARY KEY(id) ) PARTITION BY HASH PARTITIONS 16 STORED AS KUDU TBLPROPERTIES ( 'kudu.master_addresses' = 'node1:7051,node2:7051,node3:7051', 'kudu.table_name' = 'my_first_table' );
在 CREATETABLE 語句中,必須首先列出構成主鍵的列。
- 此時創建的表是內部表,從impala刪除表的時候,在底層存儲的kudu也會刪除表。
-
drop table if exists my_first_table;
外部表
外部表(創建者CREATE EXTERNAL TABLE)不受Impala管理,並且刪除此表不會將表從其源位置(此處為Kudu)丟棄。相反,它只會去除Impala和Kudu之間的映射。這是Kudu提供的用於將現有表映射到Impala的語法。
使用java創建一個kudu表:
public class CreateTable { private static ColumnSchema newColumn(String name, Type type, boolean iskey) { ColumnSchema.ColumnSchemaBuilder column = new ColumnSchema.ColumnSchemaBuilder(name, type); column.key(iskey); return column.build(); } public static void main(String[] args) throws KuduException { // master地址 final String masteraddr = "node1,node2,node3"; // 創建kudu的資料庫鏈接 KuduClient client = new KuduClient.KuduClientBuilder(masteraddr).defaultSocketReadTimeoutMs(6000).build(); // 設置表的schema List<ColumnSchema> columns = new LinkedList<ColumnSchema>(); columns.add(newColumn("CompanyId", Type.INT32, true)); columns.add(newColumn("WorkId", Type.INT32, false)); columns.add(newColumn("Name", Type.STRING, false)); columns.add(newColumn("Gender", Type.STRING, false)); columns.add(newColumn("Photo", Type.STRING, false)); Schema schema = new Schema(columns); //創建表時提供的所有選項 CreateTableOptions options = new CreateTableOptions(); // 設置表的replica備份和分區規則 List<String> parcols = new LinkedList<String>(); parcols.add("CompanyId"); //設置表的備份數 options.setNumReplicas(1); //設置range分區 options.setRangePartitionColumns(parcols); //設置hash分區和數量 options.addHashPartitions(parcols, 3); try { client.createTable("person", schema, options); } catch (KuduException e) { e.printStackTrace(); } client.close(); } }
在kudu的頁面上可以觀察到如下信息:

在impala的命令行查看表:

當前在impala中並沒有person這個表
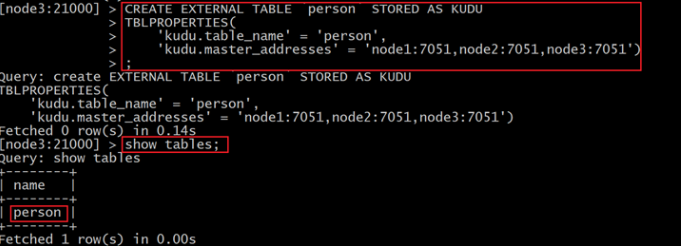
使用impala創建外部表 , 將kudu的表映射到impala上:
在impala-shell執行
CREATE EXTERNAL TABLE `person` STORED AS KUDU TBLPROPERTIES( 'kudu.table_name' = 'person', 'kudu.master_addresses' = 'node1:7051,node2:7051,node3:7051')
使用impala對kudu進行DML操作
將數據插入 Kudu 表
impala 允許使用標準 SQL 語句將數據插入 Kudu
插入單個值
創建表
CREATE TABLE my_first_table ( id BIGINT, name STRING, PRIMARY KEY(id) ) PARTITION BY HASH PARTITIONS 16 STORED AS KUDU;
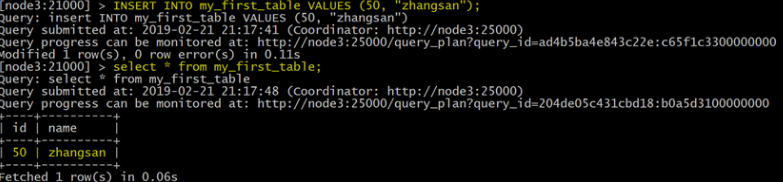
此示例插入單個行
INSERT INTO my_first_table VALUES (50, "zhangsan");
查看數據
select * from my_first_table
使用單個語句插入三行
INSERT INTO my_first_table VALUES (1, "john"), (2, "jane"), (3, "jim");

批量插入Batch Insert
從 Impala 和 Kudu 的角度來看,通常表現最好的方法通常是使用 Impala 中的 SELECT FROM 語句導入數據
INSERT INTO my_first_table
SELECT * FROM temp1;
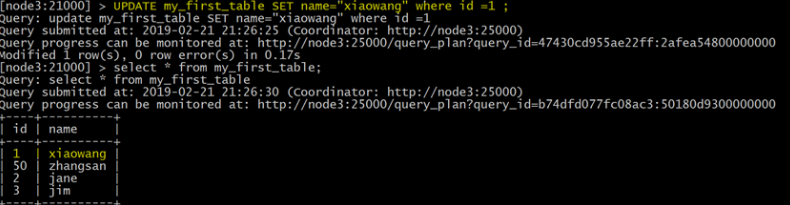
更新數據
UPDATE my_first_table SET name="xiaowang" where id =1 ;
刪除數據
delete from my_first_table where id =2;
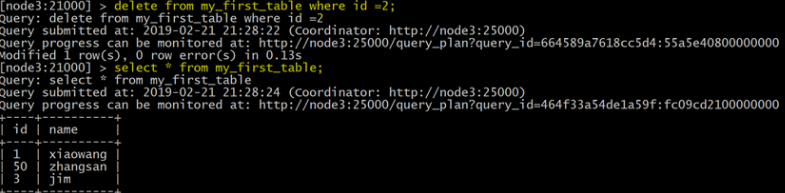
更改表屬性
開發人員可以通過更改表的屬性來更改 Impala 與給定 Kudu 表相關的元數據。這些屬性包括表名, Kudu 主地址列表,以及表是否由 Impala (內部)或外部管理。
Rename an Impala Mapping Table ( 重命名 Impala 映射表 )
ALTER TABLE PERSON RENAME TO person_temp;
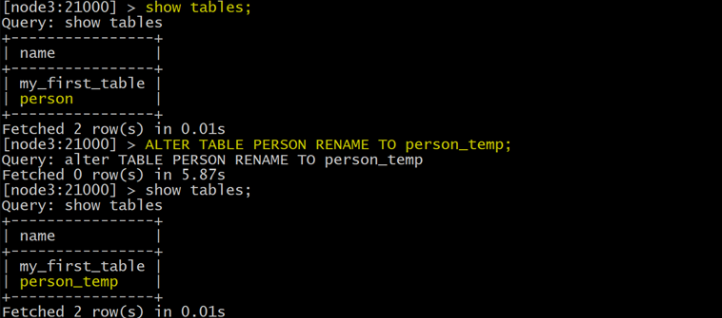
Rename the underlying Kudu table for an internal table ( 重新命名內部表的基礎 Kudu 表 )
創建內部表:
CREATE TABLE kudu_student ( CompanyId INT, WorkId INT, Name STRING, Gender STRING, Photo STRING, PRIMARY KEY(CompanyId) ) PARTITION BY HASH PARTITIONS 16 STORED AS KUDU TBLPROPERTIES ( 'kudu.master_addresses' = 'node1:7051,node2:7051,node3:7051', 'kudu.table_name' = 'student' );
如果表是內部表,則可以通過更改 kudu.table_name 屬性重命名底層的 Kudu 表
ALTER TABLE kudu_student SET TBLPROPERTIES('kudu.table_name' = 'new_student');
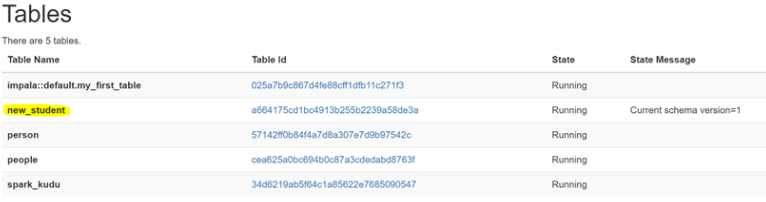
Remapping an external table to a different Kudu table ( 將外部表重新映射到不同的 Kudu 表 )
如果用戶在使用過程中發現其他應用程式重新命名了kudu表,那麼此時的外部表需要重新映射到kudu上
創建一個外部表:
CREATE EXTERNAL TABLE external_table STORED AS KUDU TBLPROPERTIES ( 'kudu.master_addresses' = 'node1:7051,node2:7051,node3:7051', 'kudu.table_name' = 'person' );
重新映射外部表,指向不同的kudu表:
ALTER TABLE external_table SET TBLPROPERTIES('kudu.table_name' = 'hashTable')
上面的操作是:將external_table映射的PERSON表重新指向hashTable表
Change the Kudu Master Address ( 更改 Kudu Master 地址 )
ALTER TABLE my_table SET TBLPROPERTIES('kudu.master_addresses' = 'kudu-new-master.example.com:7051');
Change an Internally-Managed Table to External ( 將內部管理的表更改為外部 )
ALTER TABLE my_table SET TBLPROPERTIES('EXTERNAL' = 'TRUE');


