
導讀: 在電商推薦中,除了推送商品的圖片和價格信息外,文案也是商品非常重要的維度。基於編碼器解碼器範式的序列文本生成模型是文案挖掘的核心,但該種方法面臨著兩大技術挑戰:一是文案生成結果不可靠和生成質量不可控,無法滿足業務對電商商品文案內容可靠性的嚴格要求;二是序列文本生成模型經常面臨數據坍塌,比較容 ...

導讀: 在電商推薦中,除了推送商品的圖片和價格信息外,文案也是商品非常重要的維度。基於編碼器解碼器範式的序列文本生成模型是文案挖掘的核心,但該種方法面臨著兩大技術挑戰:一是文案生成結果不可靠和生成質量不可控,無法滿足業務對電商商品文案內容可靠性的嚴格要求;二是序列文本生成模型經常面臨數據坍塌,比較容易生成萬金油式的安全文案,文案內容本身的多樣性會越來越低,且無法捕捉語言本身的流行或演化趨勢。針對以上兩大挑戰,在以文案生成系統為核心的基礎上,引入了文案摘要清洗系統和文案質量評估系統,總結提出了一個通用的電商商品文案挖掘方案。今天將和大家分享京東電商平臺的電商商品文案挖掘的優化實踐,包括以下幾方面內容:
- 電商商品文案挖掘的挑戰和方案框架
- 電商商品文案摘要清洗系統的優化實踐
- 電商商品文案生成系統的優化實踐
- 電商商品文案質量評估系統的優化實踐
--
01 電商商品文案挖掘的挑戰和方案框架
1. 電商商品文案的應用場景
首先來看一下電商商品文案的應用場景。

電商商品文案不僅可以用於描述商品的獨特賣點,同時可以用於介紹商品的一些特質。根據電商商品文案的長度,可分為短文案和長文案。例如,15字的短文案可以體現茅臺酒、手機的賣點,同時也描述了商品的特點;百餘字的長文案可以描述眼霜、一本書等。
2. 電商商品文案挖掘的兩大挑戰
基於編碼器解碼器範式的序列文本生成模型可以用於文案挖掘,就是把商品的一些信息,例如標題、類別等進行模型投喂,然後直接拿某種類型的文案作為一個參考答案進行模型訓練和學習。毫無疑問,基於編碼器解碼器範式的序列文本生成模型,肯定是文案挖掘的核心,但是在業務實踐中,該種方法存在兩個方面的技術挑戰。

序列文本生成模型天然存在生成結果不可靠、生成質量不可控的問題,而京東電商平臺對電商商品文案的內容本身的可靠性有著相對嚴格的要求,這就面臨第一個技術挑戰:文本生成質量如何控制。
另一個問題是序列文本生成模型經常容易面臨數據坍塌。在業務實踐中觀察序列文本生成模型的結果,經常能看到:如果文本生成的業務場景比較複雜或者編碼解碼問題本身比較難,序列文本生成模型越傾向於生成那種頻率比較高、相對平均且安全的文案;而且該模型在推上線運行後,會學習它自己已經生成的線上文案,長此以往,該模型越會生成那種萬金油式的安全文案,線上文案的內容本身的多樣性會隨著系統的運行越來越低。另外,序列文本生成模型由於模型本身的設計,也不太容易捕捉語言本身的流行或者演化趨勢,比如一些新詞、新的流行語或時尚一點的東西,該模型都不太可能捕捉得到。這是電商商品文案挖掘的應用實踐中面臨的第二個巨大技術挑戰。
3. 電商商品文案挖掘方案框架
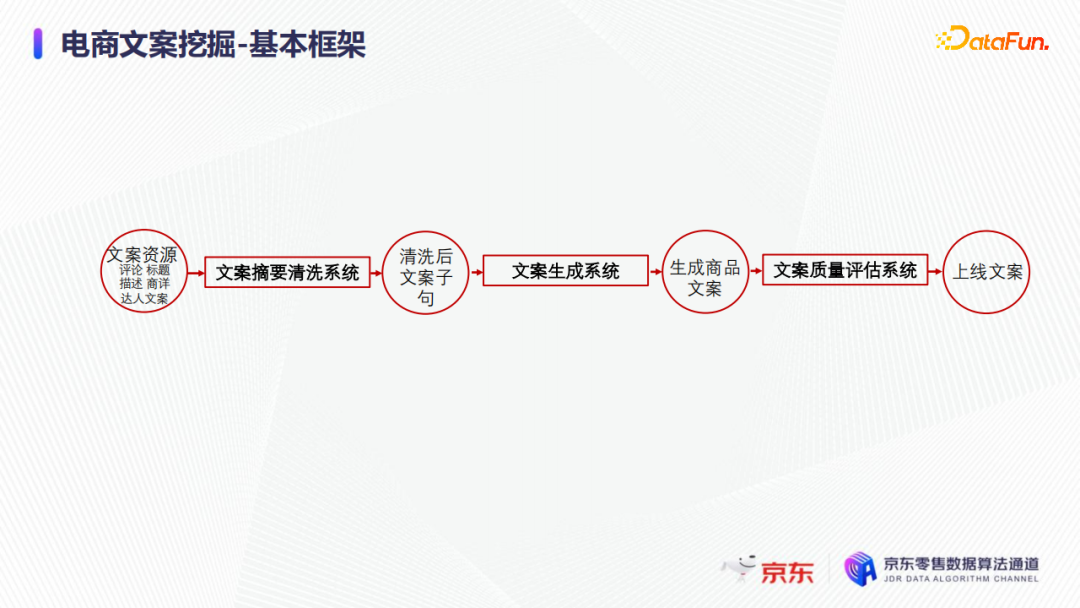
根據業務實踐,總結提出了一個通用的電商商品文案挖掘方案框架,如上圖所示,挖掘方案的核心是文案生成系統;在此基礎上針對文案挖掘的兩大技術挑戰,引入了文案摘要清洗系統和文案質量評估系統。
文案摘要清洗系統核心解決的是數據坍塌,沒有新的資源引入和沒有新的創作素材的問題,如果能夠將人工創作的一些素材片段引入到文案生成中,那麼自然有機會打破數據坍塌,不致使模型收斂到常用熱門的平均的表達形式上。
在電商平臺的商品文案中,常見的人工文案素材來源有哪些呢?
最為典型的人工文案素材就是商品的評論。電商用戶在購買了商品之後會評價,甚至有的用戶會撰寫很多很長的使用體驗;大家買東西的時候也會經常刷評論,看一看比較高質量的用戶評論所提示的信息。
另一個人工創作的文案素材來源就是商品標題和商品詳情頁的商品描述,其中在京東電商平臺上的商品詳情頁常是圖片搭配精美的廣告宣傳來展示的,因此需要提前做一些清洗加工,例如圖片文字的OCR,一些異常識別等,然後提取出人工所創作的文案素材,再合併上結構化的商品信息(標題、類別屬性等),最終輸入到文案生成模型中,用於生成商品的文案。
經生成模型生成的文案需要經過文案質量評估系統剔除不合格的文案。在文案質量評估系統的設計上有較高要求,即剔除不合格的文案後,需要達到人工審核後直接上線的要求。
以上就是電商商品文案挖掘方案的總體框架,接下來將分別介紹該方案框架如何在短文案和長文案中應用落地。
4. 電商商品文案挖掘方案的應用落地
(1) 案例一,短文案應用形式
首先以一個暖水袋的案例來介紹短文案的應用形式。
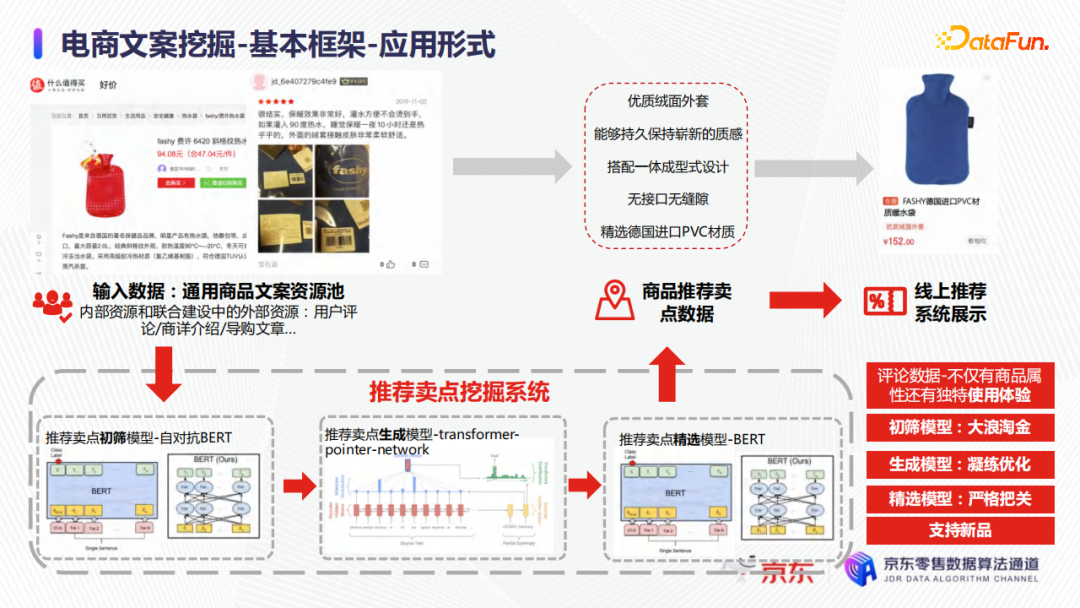
在上圖中的左上角,是一個用戶對某個暖水袋的評價:保暖效果非常好、灌水方便不燙手、外面的絨非常柔軟舒適等。為了最終生成短文案,可以把這整個一大長段的用戶評價,按標點符號先截成一些詞句,然後這些詞句經過一個初篩模型去判別哪些句子可以作為商品的賣點。例如,“灌入90度熱水”這個詞句是半截話,就不適合作為商品的賣點;“外面的絨套接觸皮膚非常柔軟舒適”就非常適合作為商品的賣點。有了這樣的詞句,電商商品文案的表達形式就更豐富,可以輸入到文案生成模型中去,上圖中的文案生成模型是一個傳統的transformer-pointer-network的深度學習模型,後面會介紹相關的優化實踐。最後通過精選模型的優質短文案,例如優質絨面外套,能夠持久保持嶄新的質感,無介面無縫隙等,會推送到線上去做展示。
總結來說,初篩模型就是要從大量不相關的文案詞句中摘取一些相關的文案,文案生成模型就是把初篩模型摘取出來的結果進行總結和凝練,精選模型是要把初篩和凝練的結果同時再做一個篩選和把關,最終得到滿足業務需求的結果。
(2) 案例二,長文案應用形式
接下來以下圖中的案例來介紹長文案的應用形式。
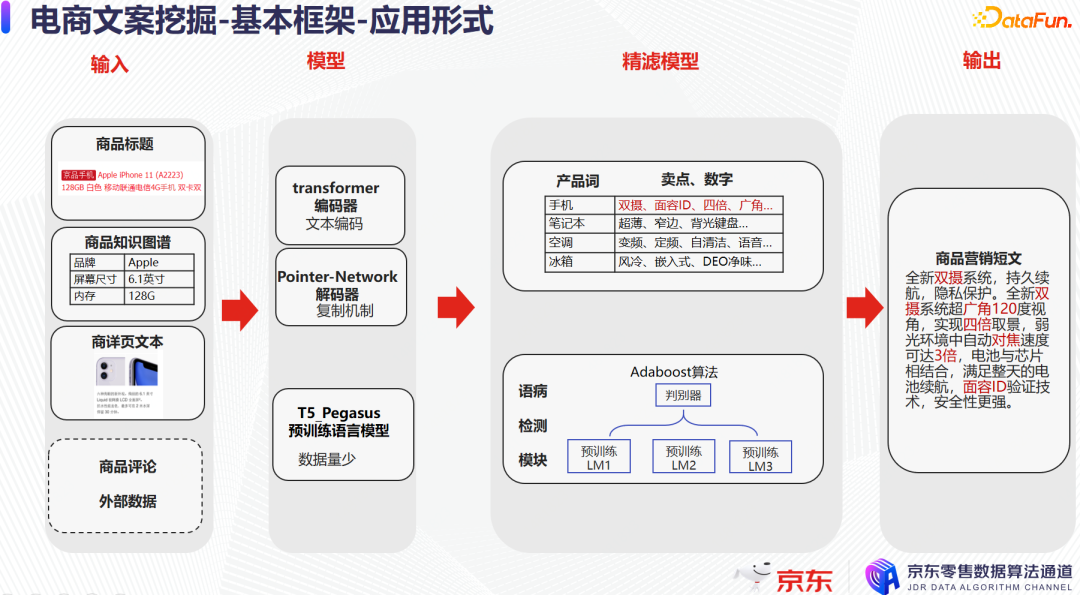
長文案相關的初篩模型是復用短文案的,以短詞句形式來抽取文案素材,作為文案生成模型的輸入。例如商品標題、商品屬性信息的知識圖譜、商品詳情頁和商品評論中抽取出的詞句片段,輸入到文案生成模型中。在精濾模型上,不僅會用總結的規則去剔除明顯出錯的一些內容,還會用多組語言模型去做投票比較和篩選,篩選出有明顯問題的文案;為了嚴格確保最終輸出到平臺的文案質量不會有問題,只要有一個語言模型認定當前的文案可能有問題,則直接剔除該文案。最後輸出到平臺上,如上圖中這樣一個百餘字左右的商品營銷短文。
介紹完電商商品文案挖掘的挑戰、方案總體框架及其應用落地形式,接下來將分別介紹三個系統(文案摘要清洗系統、文案生成系統、文案質量評估系統)的優化實踐。
--
02 電商商品文案摘要清洗系統的優化實踐
如前文介紹,文案摘要清洗系統是需要篩選和清洗商品的用戶評價或詳情頁OCR內容,從中抽取出相關的文案詞句作為文案生成模型輸入的文案素材。
1. 基於預訓練的自對抗篩選模型
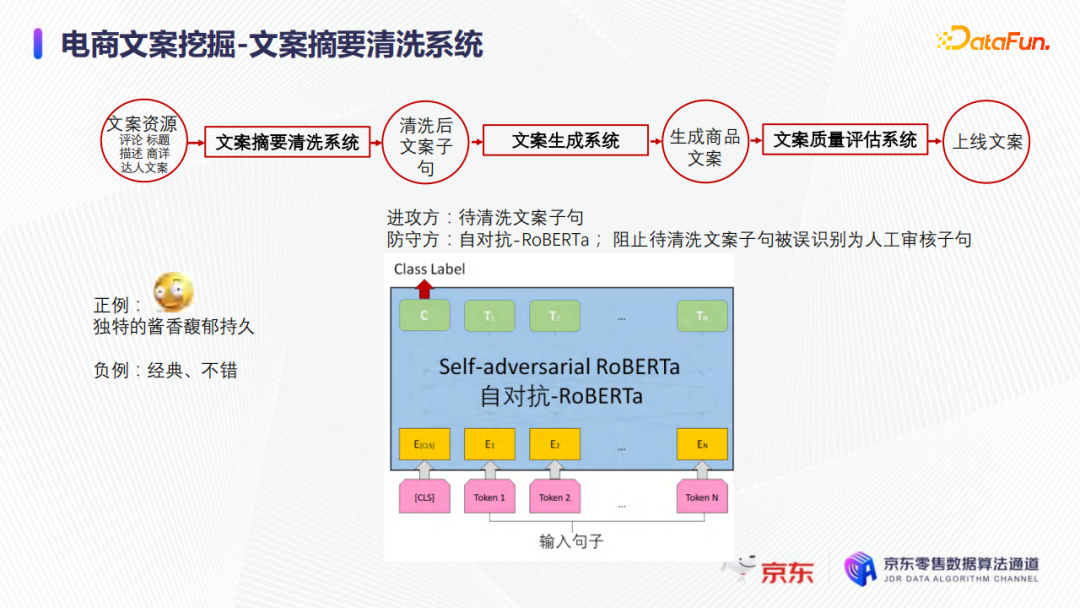
如上圖所示,以上是文案摘要清洗系統中的篩選分類模型。從模型結構上看,該模型實際上是一個預訓練模型,直接在預訓練模型上進行FINE-TUNE和分類;同時也是一個自對抗模型。比如啟動階段只有1000~10000之間的樣例,現在希望這個模型可以挖掘出這一類的文案,給出的這些樣例可以作為正例,但沒有負例,並且實際業務中也沒有那麼多資源用人工打標的方式去構造什麼樣文案是不滿足業務需求的負例。因此乾脆把所有待清洗的文案詞句都認為是負例,這樣模型就可以學習正例和負例。同時模型學習過程中,需要註意樣本的均衡,尤其要特別註意正負樣例的採樣和採樣的倍數,以保證模型不會學得太偏。因為是把所有待清洗的詞句都當作負例,負例數量是正例的十倍百倍都不止,所以需要把正例進行加權等處理,同時測試的時候,拿負例作為進攻方。
該模型不需要嚴格地區分正例和負例,如果能百分之百嚴格區分的話,那麼將得不到任何有效的結果,沒法從待清洗的詞句中篩選文案詞句;該模型是應該有差錯的,正是這些差錯才能最終篩選出有效結果,即一些和正例可能特別像的待清洗文案詞句,就會被模型識別為正例。在訓練的過程中,待清洗文案詞句被標記為負例;但在測試的時候,因為該模型不可能達到百分百的準確率,比如有2%的失誤,就會有2%的待清洗的文案詞句可能和正例特別像,就通過了該模型的篩選。以上就是利用對抗的思想去篩選出和正例可能特別像的待清洗文案詞句。
2. 採用級聯思想的文案篩選優化實踐
但如果只篩選一遍,比如有99%的準確率,1%的待清洗文案通過篩選,在實際業務中篩選出來的文案仍然是一個非常大的量級,同時依然包含了大量不滿足業務需求的文案詞句,例如負向情感問題、和商品不相關的問題等。因此採用了級聯的思想,連接多個模型,通過層層過濾、逐層篩選清洗的方式,篩選出質量非常高的文案詞句,如下圖所示。因為文案摘要清洗系統的原則是寧可錯殺,不可放過低質量的文案詞句。
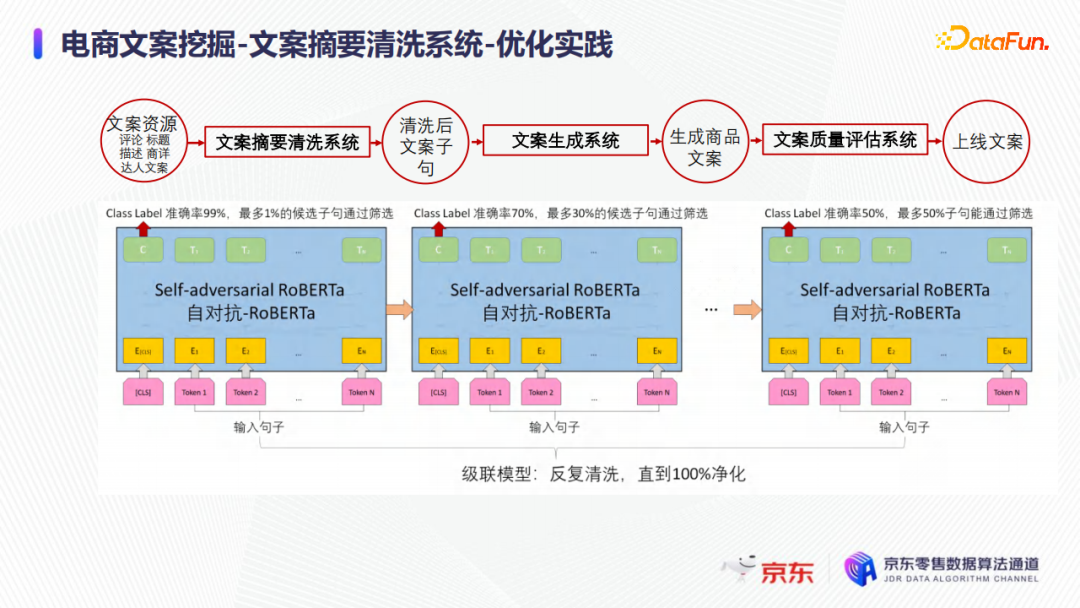
在實際業務中,雖然級聯的這些模型的結構和框架相同,但每個模型的訓練目標是不同的,例如有區分情感的,有區分和商品相關性的,並且初期的第一個階段,僅僅是做一個籠統的清洗,相當於是孔比較大的篩子,例如只要和人工採集的文案正樣本有一點不像的文案詞句,就會被剔除。
--
03 電商商品文案生成系統的優化實踐
在文案生成系統中,實際業務中使用了非常經典的transformer-pointer。
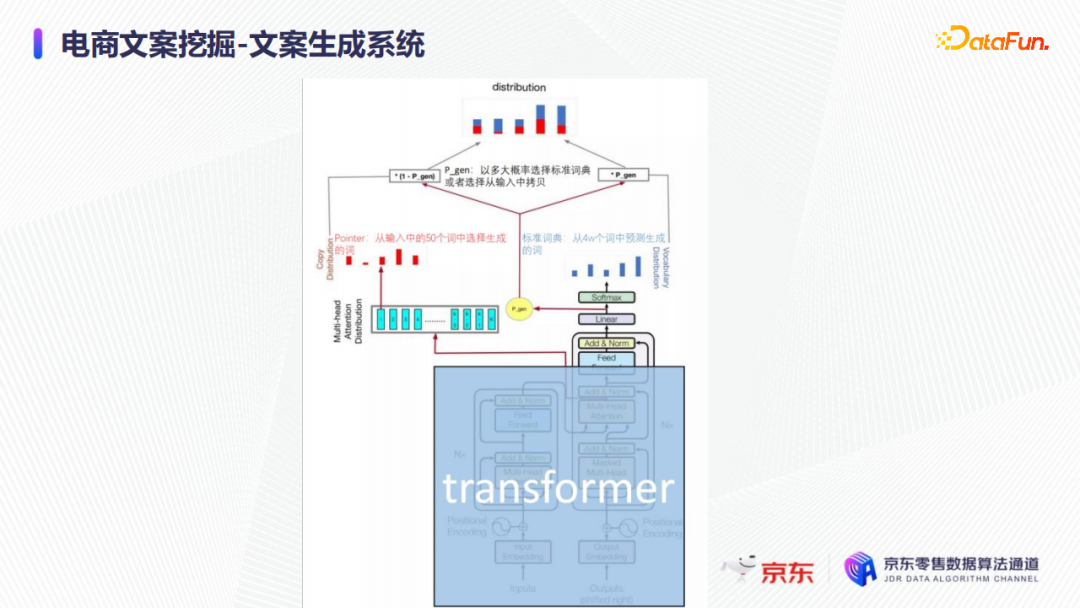
Transformer可以從標註的,比如四萬個詞或十萬個詞裡面,去預測文案生成的每一個詞串當中下一個詞可能是哪個;而Pointer就是從輸入的,比如50個詞或100個詞猜,因此引入Pointer之後,文案生成的難度大大降低,同時文案生成的效果也有比較大的提升。如上圖所示,如果只有右邊的標準transformer的話,文案生成的難度會大很多。
1. 引入超大規模預訓練語言模型的優化實踐
在業務實踐中,引入了超大規模預訓練語言模型來提升文案生成流暢度和多樣性。
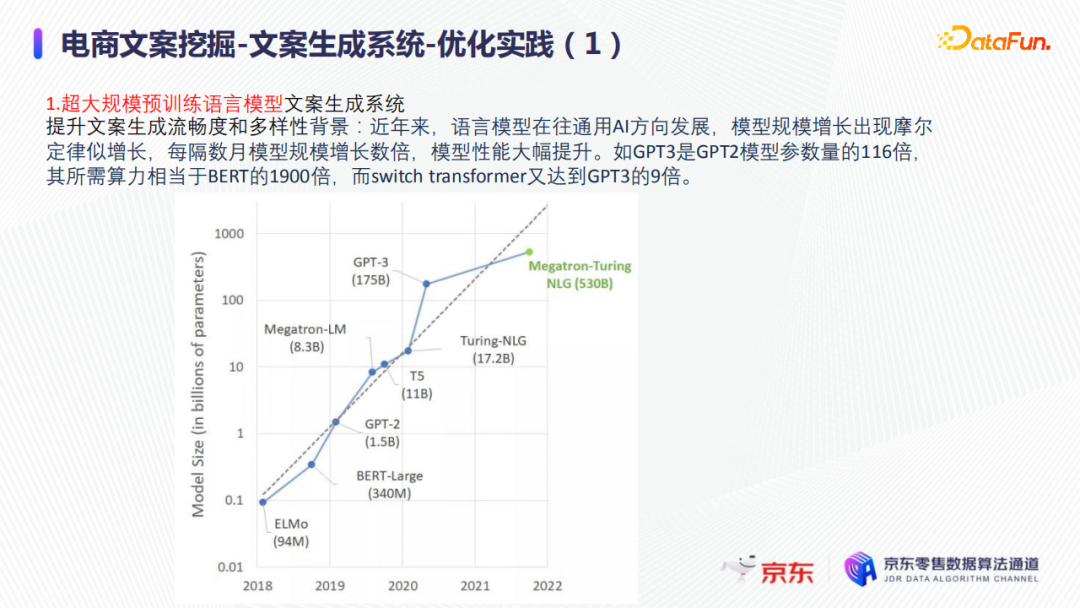
近幾年來,語言模型在往通用AI方向發展,模型規模增長出現摩爾定律似的增長,即每隔數月模型規模增長數倍,模型性能大幅提升,如上圖所示,GPT3是GPT2模型參數量的116倍,其所需算力相當於BERT的1900倍,而switch transformer又達到GPT3的9倍。現階段的實際業務仍然使用的是T5級別,相當於預訓練的大型transformer,並且是蒸餾之後的一個版本,規模上要小很多,也更實用。
超大規模預訓練的語言模型在業務實踐中主要帶來了哪些方面的收益呢?電商業務涉及到很多品類,比如有家電、服裝等等,如果對每一個品類都去設計一個模型,可能需要有30多個模型。使用超大規模預訓練的語言模型,可以使用一個模型搞定所有的品類。另一好處是針對一些小的品類。有一些小的品類,訓練樣本非常少,通常只能藉助遷移學習,用其他大的品類的數據來訓練模型,然後再用幾十條、上百條或者上千條極長尾的小品類去FINE-TUNE這個模型,這是一個妥協的方式,但超大規模預訓練的語言模型是在一個通用的語言模型上去做FINE-TUNE,則不需要另外再去FINE-TUNE。
2. 後驗式蒸餾提升中長尾商品文案生成效果的優化實踐
在電商場景下,中長尾商品特別多,並且商品的熱度分佈極其不均,二八效應非常顯著。例如,80%的商品都是沒有任何用戶評價,所有商品的平均用戶評論數大概是3~5,這意味著,只有少部分商品有上萬條,甚至幾十萬條評論,商品的長尾分佈現象極其嚴重。熱門商品的素材資源(用戶評論、問答等)豐富,熱門商品文案生成較為容易;但中長尾商品素材較少,中長尾商品文案生成較難。
藉助前面提到的超大規模預訓練的語言模型,可以緩解中長尾商品文案生成難的問題,但當線上無法採用那麼大的模型時,怎麼去解決這個問題呢?
在實際業務中進行如下優化:將熱門商品上如用戶評價等豐富的素材都用於訓練文案生成模型,然後將熱門商品文案生成模型的知識做蒸餾,後驗式蒸餾到中長尾商品文案生成模型中,也就是把熱門商品的用戶行為蒸餾到幾乎沒有用戶行為的商品上去,來提升中長尾商品文案的生成效果。
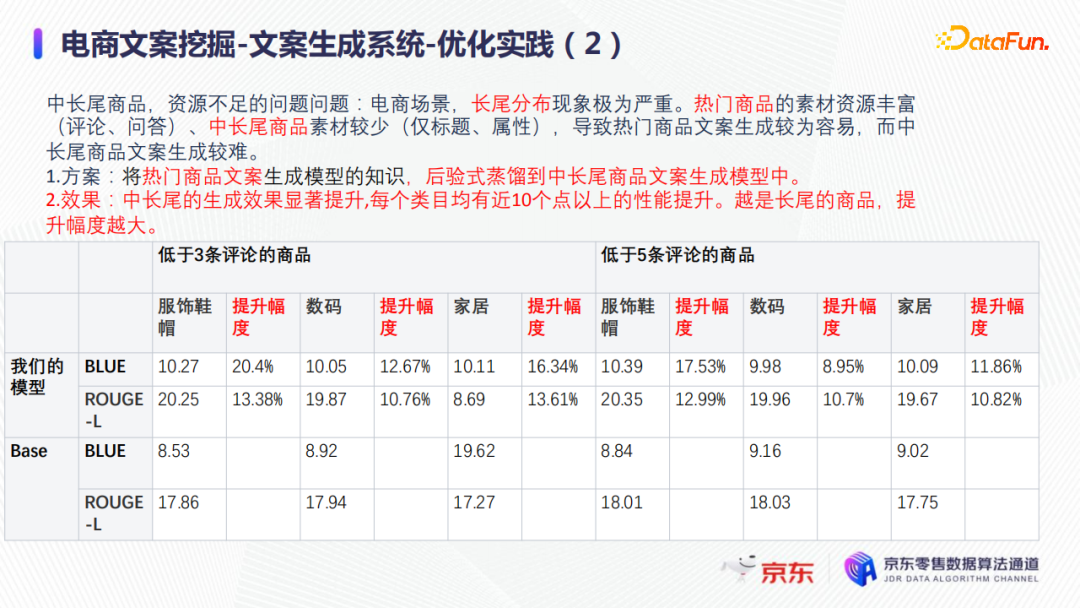
最終得到的實際效果如上圖所示:每個類目上的中長尾商品的生成文案質量都幾乎有10%以上的提升,並且越是長尾的商品,文案生成效果提升越為顯著。在短文案和長文案的具體挖掘應用實踐分別在已發表的兩篇文章中:
《(AAAI21) Probing Product Description Generation via Posterior Distillation》,
《(SIGIR20) User-Inspired Posterior Network for Recommendation Reason Generation》。
其中,在長文案的應用實踐中,還加入中間隱藏層的知識蒸餾,去降低信息短路,以提升知識蒸餾的效率,如下圖所示。
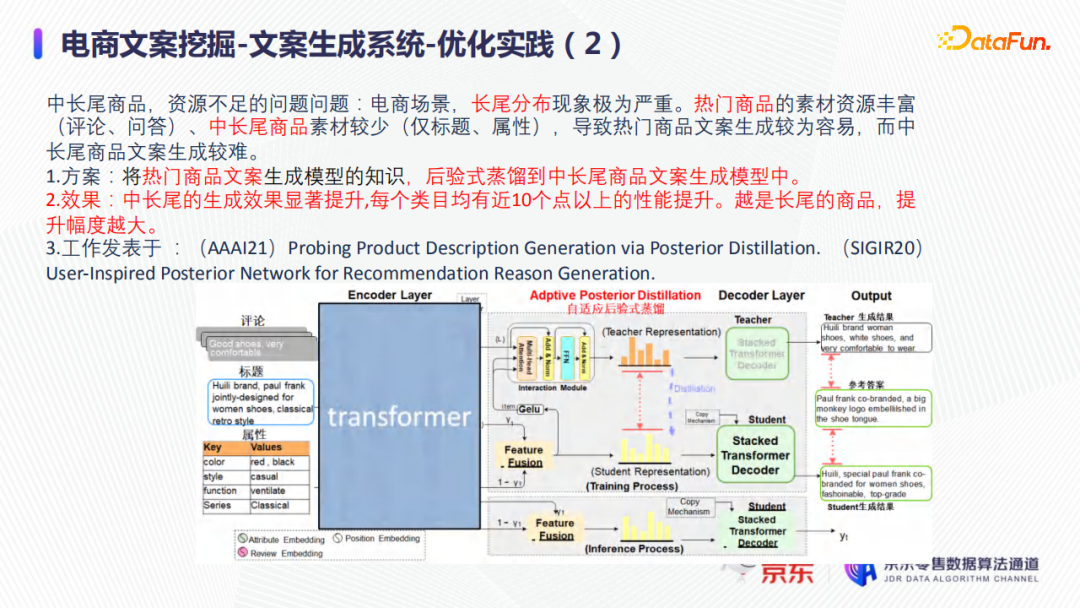
在短文案的應用實踐中,模型的知識蒸餾僅限於學習預測時候的分佈,但是應用於生成長文案的模型本身比較大,如果僅僅在輸出(Output)這一部分進行知識蒸餾提取的話,信息丟失比較多,因此必須多看幾個部分。
3. 基於參考模板的文案生成優化實踐
除了前面提到的小品類由於商品的熱度分佈不均沒有充分的訓練數據外,新的文案類型也常面臨著訓練數據不足,尤其對比那些經長時間的業務運轉已經累積了數百萬訓練數據的文案類型,起步階段的新文案類型可能只有百餘篇、千餘篇可用於訓練的文案。同時線上環境受限於計算資源,無法使用結構上特別複雜的模型,就沒有那麼強的能力生成優質的商品文案。
那要如何給一個新商品去生成優質的文案或新的文案類型呢?
首先找出類似商品的文案,參考這些文案,整理人工參考文案模板,並將參考文案模版做為文案生成模型中預測時的輸入,因此如下圖所示,在預測生成商品文案的詞串時,下一個詞將有三個來源:① 大概幾萬字的常用解碼詞典,② 約幾十個的類似商品的參考文案模板詞,③ 數百的商品文案生成的常規輸入,如品類、品牌、標題等。其中,類似商品的參考文案模板的引入大大降低了文案生成的難度,因為相當於模型提前看到了參考答案。
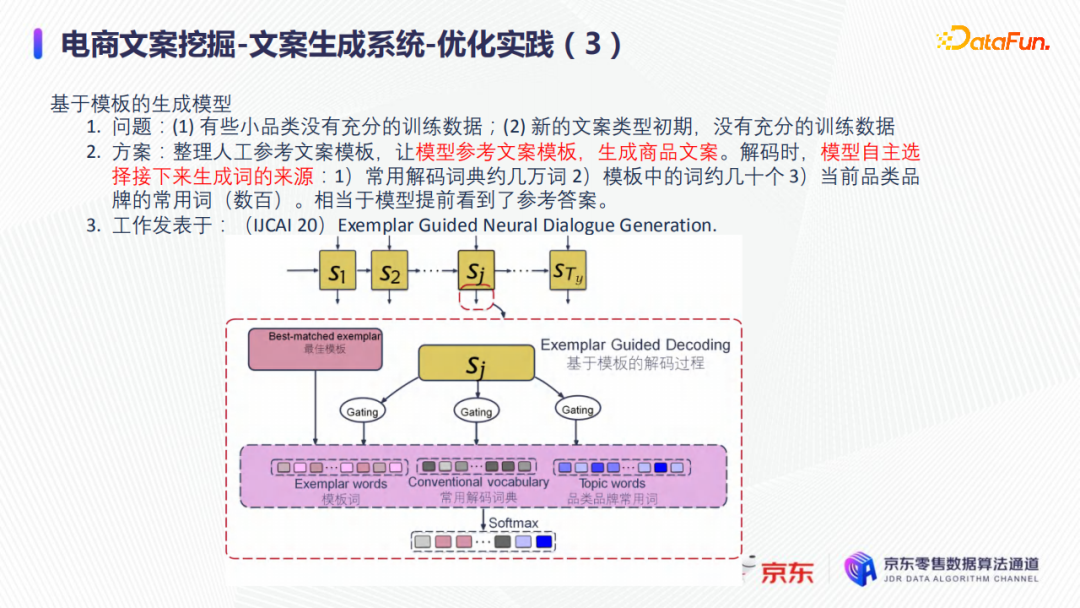
如果從本質上看,在模型框架上,非常像transformer-pointer模型,但相比於標準的transformer-pointer,增加了另外一個信息copy的來源:類似商品的參考文案模版詞,因此需要引入一個檢索模型;該檢索模型可以用外援的,也可以用in-value計算,也可以用向量召回的方式去做類似商品的文案的提取。
4. 基於訓練集增強的文案生成優化實踐
針對訓練數據不足,如下圖所示,進行了以下兩種方式的訓練集增強:一是利用同義詞替換從詞的角度做訓練數據量的增加;二是利用句子改寫,僅變換自己的表達形式,即同義不同表達方式,從句子的角度上做訓練集增強。在具體落地方案上,同義詞替換可以採用BERT Mask的方式;句子集上的替換,直接利用比較成熟的中英文互譯系統,將中文先翻譯成英文,再從英文翻譯成中文。
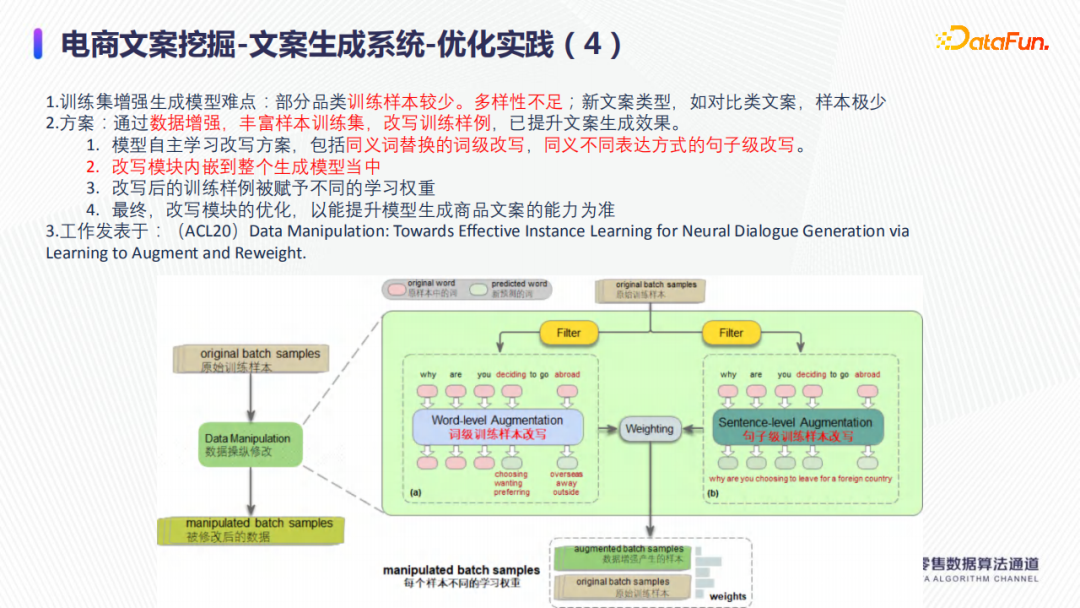
當然,無論是詞級別的樣本的數據增強,還是句子級別的樣本的數據增強,都可能是帶噪音的,因此在實際的應用中,需要給樣本賦予不同的學習權重。
簡單的做法,可以是增強的樣本的學習權重比較低,質量比較可靠的原始樣本學習權重相對高一點。
靈活一點的做法是引入一個驗證集去做測試,比如一個增強的樣本的初始學習權重和原始樣本的學習權重一樣,如果最終的性能表現在驗證集上測試表現更好,就維持該學習權重。如果最終的表現更差,則自動降低該增強的樣本的學習權重,來避免增強的樣本帶來的負面影響。因為做訓練集增強是希望生成模型可以學到不同類型的句子表達,如果帶來負面影響,則應降低其對效果的影響,訓練集增強優化始終以提升文案生成的能力為準。已發表論文做了詳細的闡述:《(ACL20) Data Manipulation: Towards Effective Instance Learning for Neural Dialogue Generation via Learning to Augment and Reweight》。
--
04 電商商品文案質量評估系統的優化實踐
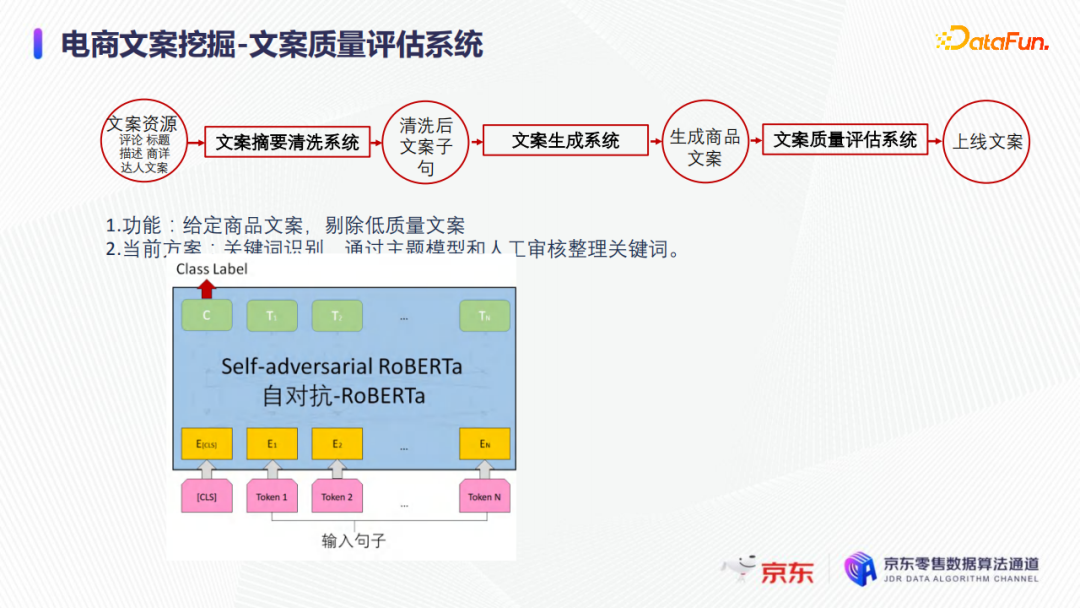
文案質量評估系統是要剔除生成的低質量文案,可以復用文案摘要清洗系統的基於判別的模式,如下圖所示。也可以用如GPT或者單純的預訓練語言模型等方式去判別句子的流暢度,或者通過主體模型和人工審核整理的關鍵詞或其他的各個方面去判別文案的質量。當然也可以結合不同模態的商品信息,進行文案質量評估。

今天的分享就到這裡,謝謝大家。
本文首發於微信公眾號“DataFunTalk”。


