
2. 資料庫操作 資料庫在創建以後最常見的操作便是 2.1 查詢 為了便於學習和理解,我們預先準備了兩個表分別是 表和 表兩個表的內容和結構如下所示 表的內容: | id | class\_id | name | gender | score | | | | | | | | 1 | 1 | 小明 | ...
2. 資料庫操作
資料庫在創建以後最常見的操作便是查詢
2.1 查詢
為了便於學習和理解,我們預先準備了兩個表分別是stduents表和classes表兩個表的內容和結構如下所示
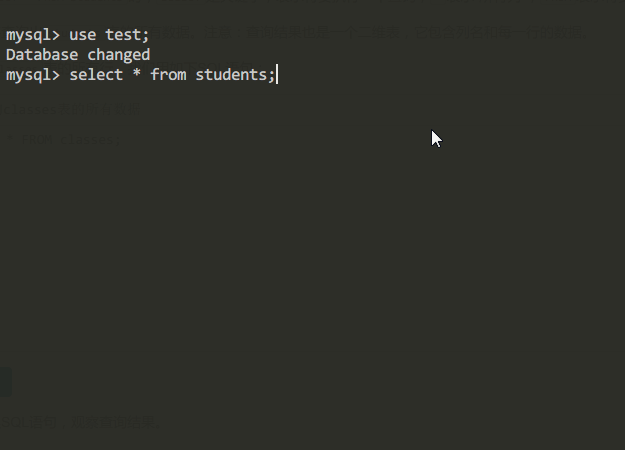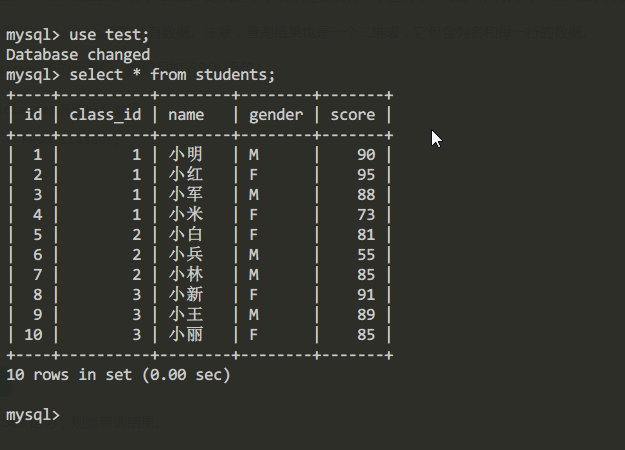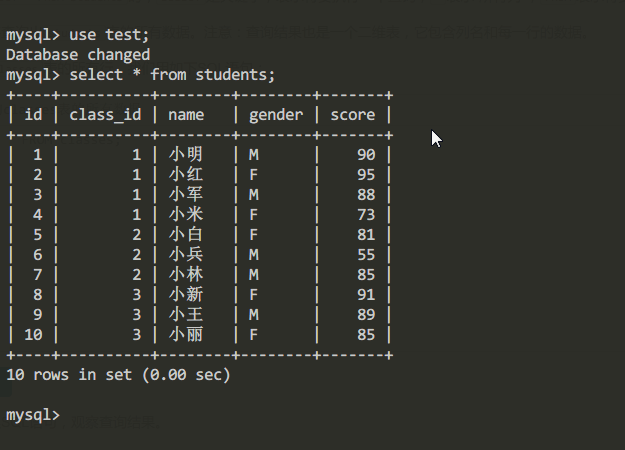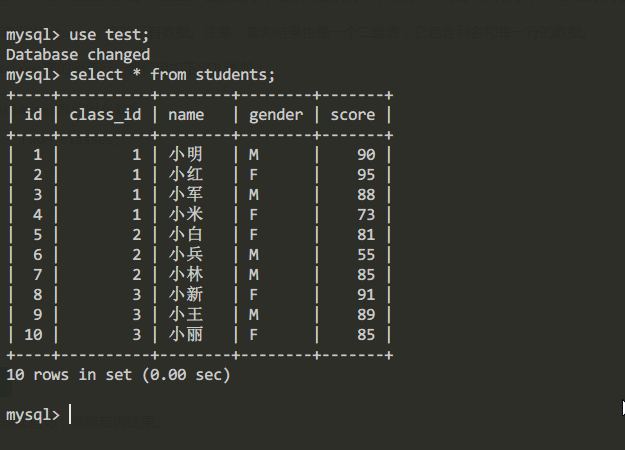
students表的內容:
| id | class_id | name | gender | score |
|---|---|---|---|---|
| 1 | 1 | 小明 | M | 90 |
| 2 | 1 | 小紅 | F | 95 |
| 3 | 1 | 小軍 | M | 88 |
| 4 | 1 | 小米 | F | 73 |
| 5 | 2 | 小白 | F | 81 |
| 6 | 2 | 小兵 | M | 55 |
| 7 | 2 | 小林 | M | 85 |
| 8 | 3 | 小新 | F | 91 |
| 9 | 3 | 小王 | M | 89 |
| 10 | 3 | 小麗 | F | 85 |
創建students表的SQL命令:
/*創建表的sql語句*/
CREATE TABLE students (
`id` int(11) NOT NULL AUTO_INCREMENT,
`class_id` int(11) DEFAULT NULL,
`name` varchar(10) DEFAULT NULL,
`gender` char(1) DEFAULT NULL,
`score` int(3) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*插入測試數據*/
INSERT INTO `students` VALUES ('1', '1', '小明', 'M', '90');
INSERT INTO `students` VALUES ('2', '1', '小紅', 'F', '95');
INSERT INTO `students` VALUES ('3', '1', '小軍', 'M', '88');
INSERT INTO `students` VALUES ('4', '1', '小米', 'F', '73');
INSERT INTO `students` VALUES ('5', '2', '小白', 'F', '81');
INSERT INTO `students` VALUES ('6', '2', '小兵', 'M', '55');
INSERT INTO `students` VALUES ('7', '2', '小林', 'M', '85');
INSERT INTO `students` VALUES ('8', '3', '小新', 'F', '91');
INSERT INTO `students` VALUES ('9', '3', '小王', 'M', '89');
INSERT INTO `students` VALUES ('10', '3', '小麗', 'F', '85');classes表的內容和結構:
| id | name |
|---|---|
| 1 | 一班 |
| 2 | 二班 |
| 3 | 三班 |
| 4 | 四班 |
創建classes表的SQL命令:
/*創建表的sql語句*/
CREATE TABLE `classes` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(5) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
/*插入測試數據*/
2.1.1基本查詢
查詢資料庫中某個表的所有內容:
SELECT * FORM <table_name>例如查詢students表中的所有內容
註意:
對於select語句來說,並不一定非要有from子句,例如如下語句
select 1+2;上述查詢會直接計算出表達式的結果。雖然SELECT可以用作計算,但它並不是SQL的強項。但是,不帶FROM子句的SELECT語句有一個有用的用途,就是用來判斷當前到資料庫的連接是否有效。許多檢測工具會執行一條SELECT 1;來測試資料庫連接。
2.1.2 條件查詢
定義:
大部分情況下,我們查詢一張表的時候並不想獲取一張表中的所有內容,而是想從所有記錄篩選出我們所需要,此時便需要我們在查詢過程中對查詢條件進行限制,這邊是條件查詢
條件查詢的語法:
SELECT * FROM <表名> WHERE <條件表達式>
例如查詢students表中分數大於等於80 (score>=80)的學生信息
查詢分數大於等於80的學生信息sql命令
SELECT * FROM students WHERE score >= 80;查詢結果

條件表達式中常用的查詢條件有如下這些
| 查詢條件 | 謂詞 |
|---|---|
| 比較 | =,>,<,>=,<=,!=,<>,!>,!<;NOT+前邊的比較符 |
| 確定範圍 | BETWEEN AND,NOT BETWEEN AND |
| 確定集合 | IN,NOT IN |
| 字元匹配 | LIKE,NOT LIKE |
| 空值 | IS NULL,IS NOT NULL |
| 多重條件(邏輯運算) | AND,OR,NOT |
2.1.3 多重條件查詢
在實際生產過程中我們查詢一個表可能查詢條件並不僅僅只有一個,此時我們便需要AND、OR和NOT來進行連接和限定。
<條件一> AND <條件二>:查詢結果既需要滿足<條件一>同時也需要滿足<條件二>。
例如查詢分數大於等於60且小於80的學生信息:
SELECT * FROM students WHERE score >=60 and score < 80; 查詢結果:

<條件一> OR <條件二>:查詢結果需要滿足條件一或者條件二。
例如查詢分數小於60或者大於等於80的學生信息:
select * from students where score <60 or score >= 80;查詢結果:

select * from students where score = 90;
select * from students where NOT score = 90;查詢結果:


2.2 投影查詢
有時我們在查詢一個表時,可能並不需要所有表的信息,而只是需要一個表的部分列,此時我們便可以通過SELECT 列1, 列2, 列3 FROM ...,讓結果集僅包含指定列。這種操作稱為投影查詢。
eg:查詢所有學生的姓名和班級信息
select name,class_id from students;查詢結果:

同時在查詢過程中我們可以對查詢後的屬性名稱設計別名,並且也可以指定結果列的順序(可以和原表的順序不同)。
使用SELECT 列1, 列2, 列3 FROM ...時,還可以給每一列起個別名,這樣,結果集的列名就可以與原表的列名不同。它的語法是SELECT 列1 別名1, 列2 別名2, 列3 別名3 FROM ...。
eg:將插敘結果中屬性名name改成student_name
select name student_name,class_id from students;查詢結果:

2.3查詢結果排序
細心的讀者可能已經發現:我們在之前所做的查詢最終的查詢結果都是按照id(或者class_id)的升序排列的,那麼我們如何來改變查詢結果的排序順序那?
其實我們可以通過ORDER BY語句來進行查詢結果出順序的控制。
eg:按照score從小到大對結果進行排序
select * from students ORDER BY score;查詢結果:

預設的排序規則是ASC升序即從小到大,當然如果我們想要查詢結果是降序排列,我們可以通過加上DESC來進行進行降序結果輸出。
eg:將上邊的查詢結果按照score降序來進行輸出

2.4 分頁查詢
有時在查詢的過程中我們查詢的到的結果集比較大,而程式在處理和顯示這些數據時空間有限不能夠一下子完全顯示出來,此時便需要將查詢到的結果集分成不同的頁來進行顯示,這邊是分頁查詢。分頁查詢實際上也就是將大的數據集(比如幾萬條)進行拆分,分成若幹頁,比如1-100第一頁、101-200第二頁、201-300第三頁,以次類推。具體使用分頁查詢時我們需要通過LIMIT <M> OFFSET <N>子句對查詢結果集的大小以及頁數進行控制。我很還以students為例,首先查詢到它所有的結果集
查詢studnets表所有結果集的sql語句
select * from students;查詢結果:

現在我們將查詢到數據集進行分頁,
查詢第一頁的數據(每頁3條數據):
select * from students limit 3 offset 0;查詢結果為:
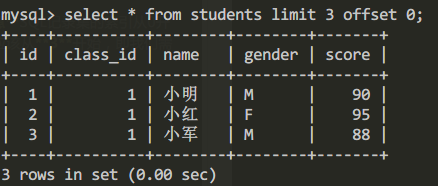
上述查詢limit 3 offset 0表示,結果集從0號記錄開始查詢。註意SQL記錄集的索引從0開始。如果需要查詢第2頁,我們需要跳過前邊的三條記錄,索引此時應該從3開始,即我們需要將offest設置為3。
查詢第2頁的結果集:
/*每頁顯示三條數據,獲取其中的第2頁*/
select * from students limit 3 offset 3;查詢結果:
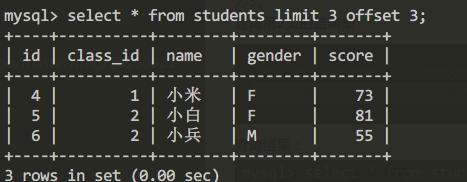
同樣的查詢第3頁的結果集時應該講offset設置為6;
查詢第3頁的結果集:
select * from students limit 3 offset 6;查詢結果:
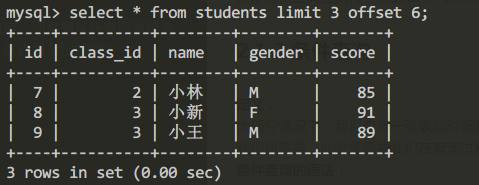
查詢第4頁的結果集:
select * from students limit 3 offset 9;查詢結果為:
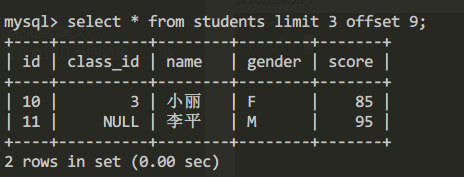
由於第4頁只有一條記錄所以查詢結果只顯示一條記錄。limit 3表示每頁最多“顯示三條記錄”。
由此可見我們在進行分頁查詢的時候最關鍵的問題是設計每頁需要顯示的結果集大小pageSize(這裡設置的是3),然後根據當前頁的索引pageIndex(需要查第幾頁的結果),確定limit以及offset的值:
limit一般設置為pageSizeoffset設置為pageSize*(pageIndex-1)
註意:
offset值的設置是可選的,如果只寫limit 3,DBMS不會報錯,而是預設認為是limit 3 offset 0。offset設置的值如果大於最大數量並不會報錯,而只是得到一個空的結果集- 在
MYSQL中,limit 3 offset 6還可以寫為limit 3,6 - 在使用
limit <m> offset <n>時隨著n的值越來越大,查詢的效率也會越來越低
2.5 聚集查詢
在日常開發的某些應用場景中,我們並不需要獲得具體數據集,而只是想要獲得滿足條件的數據集的條數(例如:查詢班級表中男生的人數),此時便需要嵌套查詢。對於統計總數、平均數這類查詢來說,SQL已經為我們提供了專門的聚合函數,使用聚合函數進行查詢,我們便稱之為聚合查詢,仍然以查詢students表中男生的人數為例,我們可以通過SQL內置的count()函數來進行查詢。
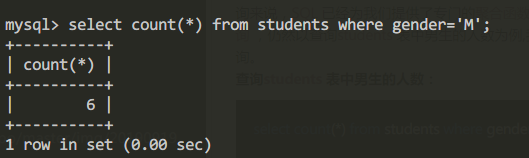
查詢students表中男生的人數:
select count(*) from students where gender='M';查詢結果:
當然除了count()函數之外SQL還提供瞭如下的聚合函數
| 函數 | 說明 |
|---|---|
| SUM | 計算某一列的合計值,該列必須為數值類型 |
| AVG | 計算某一列的平均值,該列必須為數值類型 |
| MAX | 計算某一列的最大值 |
| MIN | 計算某一列的最小值 |
註意:
MAX()個MIN()函數並不僅限於數值類型。如果字元類型,MAX()和MIN()會返回排序在最後邊和最前邊的字元- 如果
聚合查詢的結果沒有匹配到任何行,count()會返回0,而sum()、avg()、max()和min()會返回null。
2.6 多表查詢
select查詢不僅可以從一張表中查詢出結果,還可以同時在多張表中查詢出結果,其語法為:select * form <table 1>,<table 2>。
例如,從同時從students表和classes表中查詢出結果:
查詢所用sql語句:
select * from students,classes;查詢結果為:
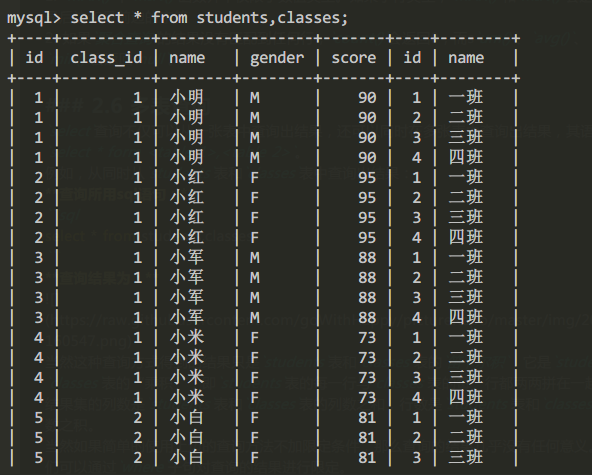
當然這種查詢方式得到的結果只是students表和classes表的笛卡爾積,它是students表和classes表的“乘積”,即students表的每一行與classes表的每一行都兩兩拼在一起返回。結果集的列數是students表和classes表的列數之和,行數是students表和classes表的行數之積。
當然如果簡單的使用上邊的查詢方法不加限定條件,那麼查詢的結果幾乎沒有任何意義。因此我們可以通過where子句對查詢的結果進行限定。
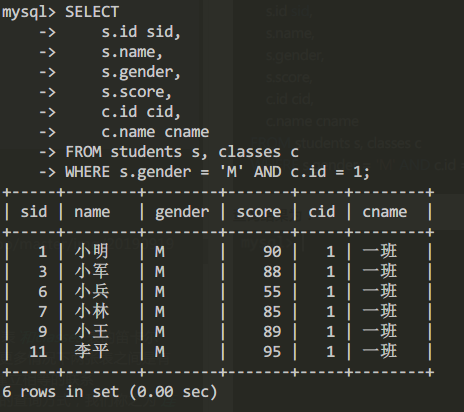
例如查詢男生且位於一班的信息
SELECT
s.id sid,
s.name,
s.gender,
s.score,
c.id cid,
c.name cname
FROM students s, classes c
WHERE s.gender = 'M' AND c.id = 1;查詢結果為:
2.7 連接查詢
在上一小結我們提到的連接查詢,所得到的結果只是兩個表stuents表和classes表的笛卡爾積,兩個表直接沒有任何的邏輯聯繫,而實際上我們進行多表查詢時更多情況下兩張表之間是有關係聯繫的,比如將students表中class_id和classes表中的id建立相等的聯繫stduents.class_id=classes.id,這種連接兩個表進行JOIN運算的的查詢方式,我們稱之為連接查詢。
連接查詢是我們在實際開發過程最常用的查詢方式,連接查詢在查詢過程中又分為自然連接查詢、內連接查詢、外連接查詢等。
自然連接查詢:在查詢過程中,我們將目標列中重覆的屬性列去掉這一過程我們稱之為自然連接查詢。
例如我們查詢所有學生信息(包括班級信息),其中信息如姓名、性別、id等信息都在students表中,而班級信息卻在classes表中,此時如果直接通過上一節的奪表查詢的查詢方法進行查詢。這樣查詢的結果會有許多重覆的結果值。此時我們便可以通過自然連接查詢的方式(限定students表和classes表的屬性關係)來進行查詢。
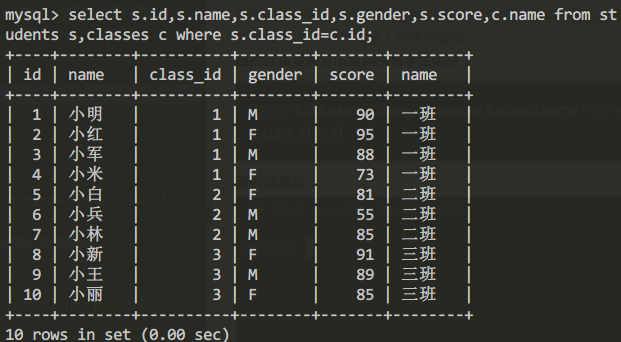
自然連接查詢方法查詢所有學生信息:
select s.id,s.name,s.class_id,s.gender,s.score,c.name from students s,classes c where s.class_id=c.id查詢結果為:
當然我們在查詢班級所有信息時我們也可以通過內連接查詢來獲取相同的查詢結果。
內連接查詢方式查詢所有學生信息:
select s.id,s.name,s.class_id,s.gender,s.score,c.name from students s inner join classes c on s.class_id=c.id;查詢結果為:
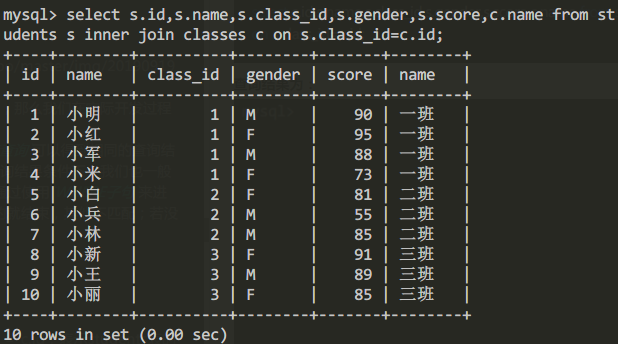
此時可能有人要問了,既然自然連接查詢和內連接查詢可以相同結果,那麼我們在實際開發過程中應該選擇哪種查詢方法?
針對這個問題,首先我們要明白雖然通過自然連接查詢以及內連接查詢可以得到相同的查詢結果,但是它們在底層的實現原理是不同的。一般來說能獲得相同的查詢結果條件下,我們也一般都是通過內連接來查詢的,因為內連接使用ON,而自然連接是通過使用WHERE子句來進行限定,而WHERE的效率沒有ON高(ON 指匹配到第一條成功的就結束,其他不匹配;若沒有,不進行匹配,而WHERE會一直匹配,進行判斷。)
註意: inner join查詢的寫法為:
- 先確定主表,仍然使用FROM <表1>的語法;
- 再確定需要連接的表,使用INNER JOIN <表2>的語法;
- 然後確定連接條件,使用ON <條件...>,這裡的條件是s.class_id = c.id,表示students表的class_id列與classes表的id列相同的行需要連接;
- 可選:加上WHERE子句、ORDER BY等子句。
那可能又有人問了“既然有外連接,那麼是否有內連接那?”答案是肯定的,我們暫且不說什麼是外連接,我們先通過一個例子來看下內連接和外連接之間的區別,我們還是查詢所有學生的信息,但是不同之處在於我們將內連接換成外連接。
通過外連接查詢所有學生信息:
SELECT s.id, s.name, s.class_id, c.name class_name, s.gender, s.score
FROM students s
RIGHT OUTER JOIN classes c
ON s.class_id = c.id;查詢結果為:
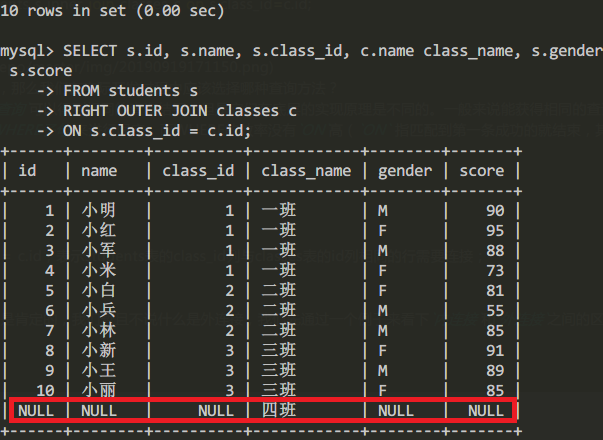
我們容易發現,此時的查詢結果比內連接方式多了一行,多出來的一行是“四班”,但是,學生相關的列如name、gender、score都為NULL。這也容易理解,因為根據ON條件s.class_id = c.id,classes表的id=4的行正是“四班”,但是,students表中並不存在class_id=4的行。
當然有RIGHT OUTER JOIN,就有LEFT OUTER JOIN,以及FULL OUTER JOIN。它們的區別是:INNER JOIN只返回同時存在於兩張表的行數據,由於students表的class_id包含1,2,3,classes表的id包含1,2,3,4,所以,INNER JOIN根據條件s.class_id = c.id返回的結果集僅包含1,2,3。RIGHT OUTER JOIN返回右表都存在的行。如果某一行僅在右表存在,那麼結果集就會以NULL填充剩下的欄位。LEFT OUTER JOIN則返回左表都存在的行。如果我們給students表增加一行,並添加class_id=5,由於classes1表並不存在id=5的行,所以,LEFT OUTER JOIN的結果會增加一行,對應的class_name是NULL:
先插入一個不含class_id的學生信息:
insert into stduents (id, name,gender,score) values(default,'李平','M',95);
select * from students;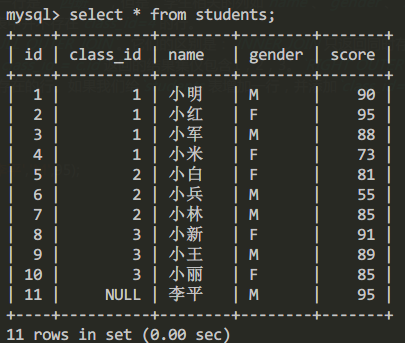
通過外連接查詢所有學生信息:
SELECT s.id, s.name, s.class_id, c.name class_name, s.gender, s.score
FROM students s
LEFT OUTER JOIN classes c
ON s.class_id = c.id;查詢結果為:
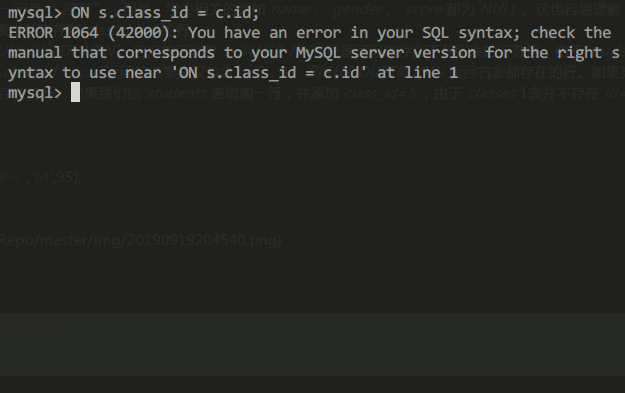
最後,我們使用FULL OUTER JOIN,它會把兩張表的所有記錄全部選擇出來,並且,自動把對方不存在的列填充為NULL:
SELECT s.id, s.name, s.class_id, c.name class_name, s.gender, s.score
FROM students s
FULL OUTER JOIN classes c
ON s.class_id = c.id;查詢結果:
| id | name | class_id | class_name | gender | score |
|---|---|---|---|---|---|
| 1 | 小明 | 1 | 一班 | M | 90 |
| 2 | 小紅 | 1 | 一班 | F | 95 |
| 3 | 小軍 | 1 | 一班 | M | 88 |
| 4 | 小米 | 1 | 一班 | F | 73 |
| 5 | 小白 | 2 | 二班 | F | 81 |
| 6 | 小兵 | 2 | 二班 | M | 55 |
| 7 | 小林 | 2 | 二班 | M | 85 |
| 8 | 小新 | 3 | 三班 | F | 91 |
| 9 | 小王 | 3 | 三班 | M | 89 |
| 10 | 小麗 | 3 | 三班 | F | 88 |
| 11 | 李平 | 5 | NULL | M | 95 |
註意:MYSQL是不支持FULL OUTER JOIN查詢的。
為了便於大家理解JON查詢,下邊我們用圖來表示各種查詢的關係:
假設查詢語句是:
SELECT ... FROM tableA ??? JOIN tableB ON tableA.column1 = tableB.column2;我們把tableA看作左表,把tableB看成右表,那麼INNER JOIN是選出兩張表都存在的記錄:
LEFT OUTER JOIN是選出左表存在的記錄:
RIGHT OUTER JOIN是選出右表存在的記錄:
FULL OUTER JOIN則是選出左右表都存在的記錄:




2.7 嵌套查詢
基於上邊幾節的描述常用的查詢方法都已基本囊括,但是某些情況下我們需要將一個查詢塊(一個SELECT-FROM-WHERE子句稱為查詢塊)嵌套在另一個查詢塊的 WHERE 子句或 HAVING 短語的條件中的查詢稱為嵌套查詢。例如:
通過嵌套查詢二班的學生信息:
select * from students where class_id in
(select id from classes where name='二班' );查詢結果:
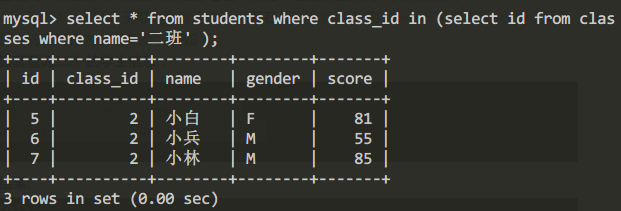
嵌套查詢可以使用戶使用多個簡單查詢構成複雜的查詢,從而增強SQL的查詢能力。以層層嵌套的方式來構造程式正式SQL中“結構化”的含義所在。在使用嵌套查詢的過程中根據子查詢的方式不同,我們將查詢分為下邊三大類:
2.7.1 使用IN謂詞的子查詢
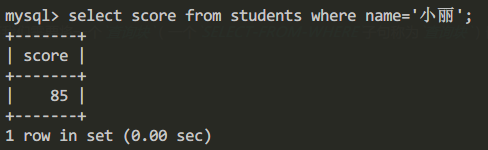
在嵌套查詢中,子查詢的結果往往是一個集合,所以謂詞IN是嵌套查詢中經常使用的謂詞。比如我們要查詢跟小麗同學考同樣分數學生的信息我們可以通過如下步驟來構造嵌套查詢。
- 首先確定小麗同學所考的分數:
查詢小麗同學所考的分數:
select score from students where name='小麗';查詢結果為:
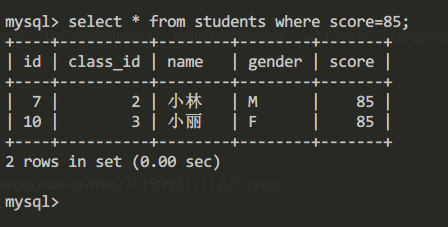
- 查詢
students表中所有score=85的學生信息:
查詢score=85的學生信息:
select * from students where score=85;查詢結果:
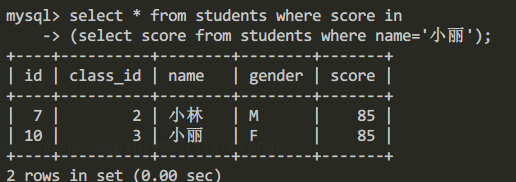
- 將第一步構造的查詢語句嵌套到第二句中構造
嵌套查詢。
查詢語句為:
select * from students where score in
(select score from students where name='小麗');查詢結果為:
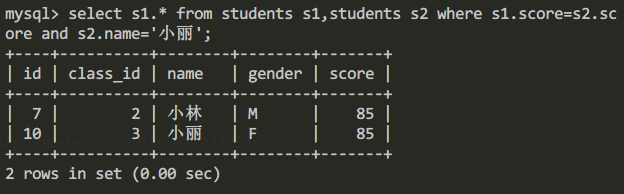
在這個例子程式中細心的同學會發現,子查詢的查詢條件是和父查詢是相互獨立的,對於此類查詢我們稱之為不相關子查詢。對於此種查詢我們實際上是可以通過連接查詢來獲取同樣的查詢結果的。例如上邊“查詢跟小麗同學考同樣分數學生的信息”,我們可以通過如下的SQL語句進行替代:
select s1.* from students s1,students s2 where s1.score=s2.score and s2.name='小麗';查詢結果:
由此可見實現同一個結果的查詢方式有很多種,但是不同方法查詢的效率確實不同的。這就是數據編程人員需要掌握的數據性能調優技術,後續時間充裕,我會對常用的mysql查詢的調優技術進行總結,此處便不進行詳盡闡述了。
2.7.2 帶有比較符號的子查詢
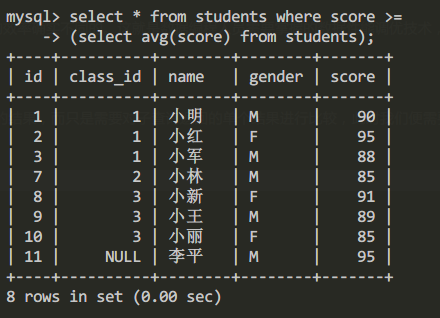
有時某些嵌套子查詢中,我們並不需要通過IN詳盡匹配子查詢中的結果,而只是需要對子查詢返回的單個結果進行比較,此時我們便需要使用比較運算符對查詢結果進行限定。比如我們查詢分數高於平均分的學生信息:
select id,class_id,name,gender,score from students s where score >=
(select avg(score) from students);查詢結果為:
註意:在使用比較符號時子查詢的應當只有一個否則,查詢結果是不正確的。
2.7.3 帶有ANY(SOME) 或者ALL位於的子查詢
子查詢的結果有一個時可以使用比較運算符,但是當返回值有多個時我們需要通過ANY(SOME)或者ALL等謂語以及和比較符號一起連用來對結果進行限定,常見的用法以及含義如下表所示
| 限定符 | 作用 |
|---|---|
| >ANY | 大於子查詢中的某個結果值 |
| >ALL | 大於子查詢的所有結果值 |
| <ANY | 小於子查詢結果中的某個值 |
| <ALL | 小於子查詢結果中的所有值 |
| >=ANY | 大於等於子查詢中的某個結果只 |
| >=ALL | 大於等於子查詢中的所有結果只 |
| <=ANY | 小於等於子查詢中的某個結果值 |
| <=ALL | 小於等於子查詢的所有結果值 |
| =ANY | 等於子查詢中的某個結果值 |
| =ALL | 等於子查詢中的所有結果值(通常沒有任何意義) |
| !=ANY | 不等於子查詢中的某個結果值 |
| !=ALL | 不等於子查詢中的所有結果值 |
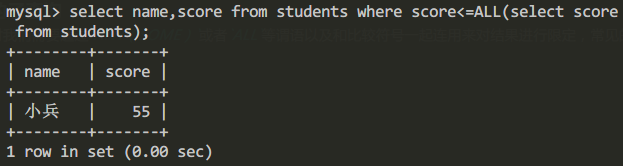
比如查詢所有學生中分數最低的學生的姓名和成績
select name,score from students where score<=ALL(select score from students);查詢結果為:
2.7.4 帶EXISTS的子查詢
EXISTS代表存在量詞。帶有EXISTS謂詞的子查詢不返回任何數據,只產生邏輯真“true”和邏輯假“flase”。
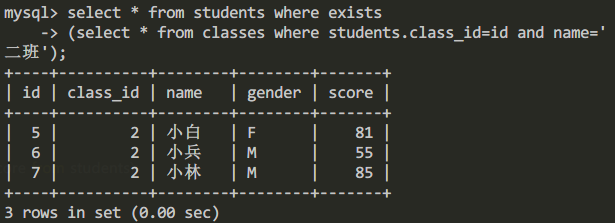
例如我們可以通過嵌套查詢,查詢二班所有學生的信息。
select * from students where exists
(select * from classes where students.class_id=id and name='二班');查詢結果:
註意:通過EXISTS引出的子查詢,其目標表達式通常都是使用*,因為帶有EXISTS的子查詢只返回真值或者假值,給出列名沒有任何意義。
2.8 基於派生表的查詢
其實子查詢有時候並不一定非要出現在WHERE子句中,還可以出現在FROM子句中,這是子查詢產生的臨時派生表成為朱查詢的查詢對象,這種查詢方式我們稱為基於派生表的查詢。
例如查詢所有學生的姓名信息我們通過派生表查詢方式實現:
select s1.name from
(select * from students) as s1查詢結果為:
當然我們在此處舉例子可能意義不大,僅僅只是為了說明EXITS子句的用法。具體在開發過程中EXISTS的具體使用,需要讀者自己去發掘和探索。


