
1、環境說明 | 操作系統 | CentOS Linux release 7.4.1708 (Core) | | | : : | | Ambari | 2.6.x | | HDP | 2.6.3.0 | | Spark | 2.x | | Phoenix | 4.10.0 HBase 1.2 | 2 ...
1、環境說明
| 操作系統 | CentOS Linux release 7.4.1708 (Core) |
|---|---|
| Ambari | 2.6.x |
| HDP | 2.6.3.0 |
| Spark | 2.x |
| Phoenix | 4.10.0-HBase-1.2 |
2、條件
HBase 安裝完成
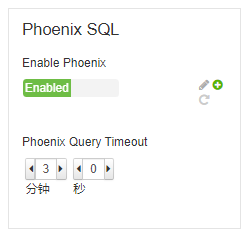
Phoenix 已經啟用,Ambari界面如下所示:
Spark 2安裝完成
3、Spark2 與 Phoenix整合
Phoenix 官網整合教程: http://phoenix.apache.org/phoenix_spark.html
步驟:
進入 Ambari Spark2 配置界面
找到
自定義 spark2-defaults並添加如下配置項:spark.driver.extraClassPath=/usr/hdp/current/phoenix-client/phoenix-4.10.0-HBase-1.2-client.jar spark.executor.extraClassPath=/usr/hdp/current/phoenix-client/phoenix-4.10.0-HBase-1.2-client.jar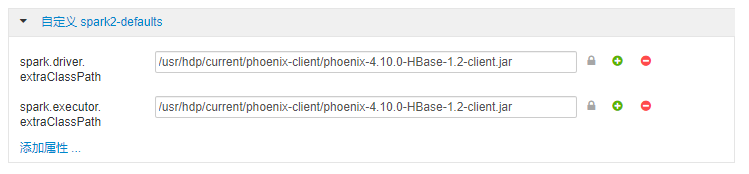
4、Yarn HA 問題
如果配置了Yarn HA, 則需要修改 Yarn HA 配置,否則spark-submit提交任務會報如下錯誤:
Exception in thread "main" java.lang.IllegalAccessError: tried to access method org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider.getProxyInternal()Ljava/lang/Object; from class org.apache.hadoop.yarn.client.RequestHedgingRMFailoverProxyProvider
at org.apache.hadoop.yarn.client.RequestHedgingRMFailoverProxyProvider.init(RequestHedgingRMFailoverProxyProvider.java:75)
at org.apache.hadoop.yarn.client.RMProxy.createRMFailoverProxyProvider(RMProxy.java:163)
at org.apache.hadoop.yarn.client.RMProxy.createRMProxy(RMProxy.java:94)
at org.apache.hadoop.yarn.client.ClientRMProxy.createRMProxy(ClientRMProxy.java:72)
at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.serviceStart(YarnClientImpl.java:187)
at org.apache.hadoop.service.AbstractService.start(AbstractService.java:193)
at org.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:153)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:56)
at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:173)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:509)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2516)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:922)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:914)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:914)
at cn.spark.sxt.SparkOnPhoenix$.main(SparkOnPhoenix.scala:13)
at cn.spark.sxt.SparkOnPhoenix.main(SparkOnPhoenix.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.i修改Yarn HA配置:
將原來的配置:
yarn.client.failover-proxy-provider=org.apache.hadoop.yarn.client.RequestHedgingRMFailoverProxyProvider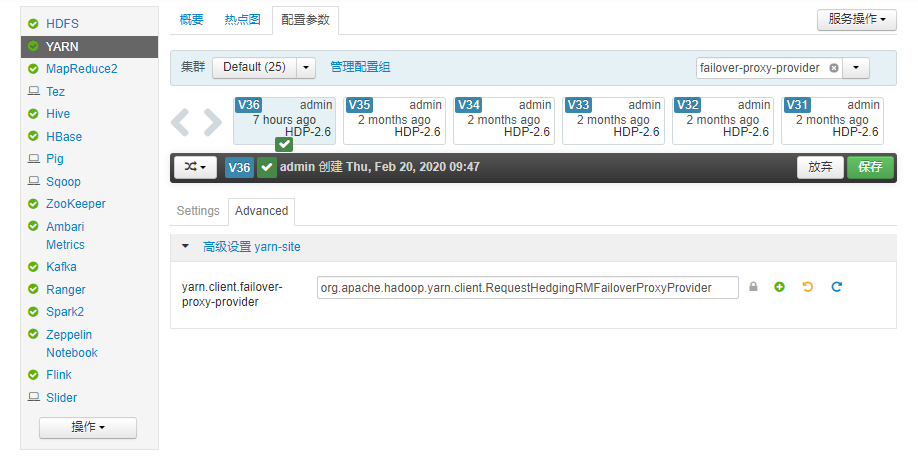
改為現在的配置:
yarn.client.failover-proxy-provider=org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider
如果沒有配置 Yarn HA, 則不需要進行此步配置



