大數據 概述 大數據是新處理模式才能具備更多的決策力,洞察力,流程優化能力,來適應海量高增長率,多樣化的數據資產。 大數據面臨的問題 怎麼存儲海量數據(kb,mb,gb,tb,pb,eb,zb) 怎麼對數據進行降噪處理(對數據進行清洗,使得數據變廢為寶,提取有用的數據,減少不必要的數據資源空間的釋放 ...
大數據
-
概述
-
大數據是新處理模式才能具備更多的決策力,洞察力,流程優化能力,來適應海量高增長率,多樣化的數據資產。
-
-
大數據面臨的問題
- 怎麼存儲海量數據(kb,mb,gb,tb,pb,eb,zb)
- 怎麼對數據進行降噪處理(對數據進行清洗,使得數據變廢為寶,提取有用的數據,減少不必要的數據資源空間的釋放)
-
處理方案
- hadoop 是一種分散式文件存儲系統來解決存儲的問題,其中hdfs用來解決數據存儲問題,mapReduce來解決如何進行建造處理
-
hadoop是什麼?
-
由來?
-
根據google發佈的3篇文章
-
google File System
-
Google MapReduce 獲得啟發 hadoop之父 Doug Cutting 用java語言解決大數據所面臨的問題
-
- 概述
- hadoop 是apache基金會的一款開源的分散式的基礎架構,它實現了高容錯率,乃至高吞吐量,低成本,由於hadoop用java語言編寫可以用在linux是非常可靠的,hadoop核心設計是hdfs和mapReudce以及Hbase分別對應這又google3篇文章,解決了大數據所面臨的問題
- hdfs 分散式文件存儲系統
- mapreduce 分散式計算框架 只需要少量的java代碼 就能實現分散式計算
- hbase 基於HDFS 的列式存儲的NoSql
- hadoop 是apache基金會的一款開源的分散式的基礎架構,它實現了高容錯率,乃至高吞吐量,低成本,由於hadoop用java語言編寫可以用在linux是非常可靠的,hadoop核心設計是hdfs和mapReudce以及Hbase分別對應這又google3篇文章,解決了大數據所面臨的問題
- hdfs
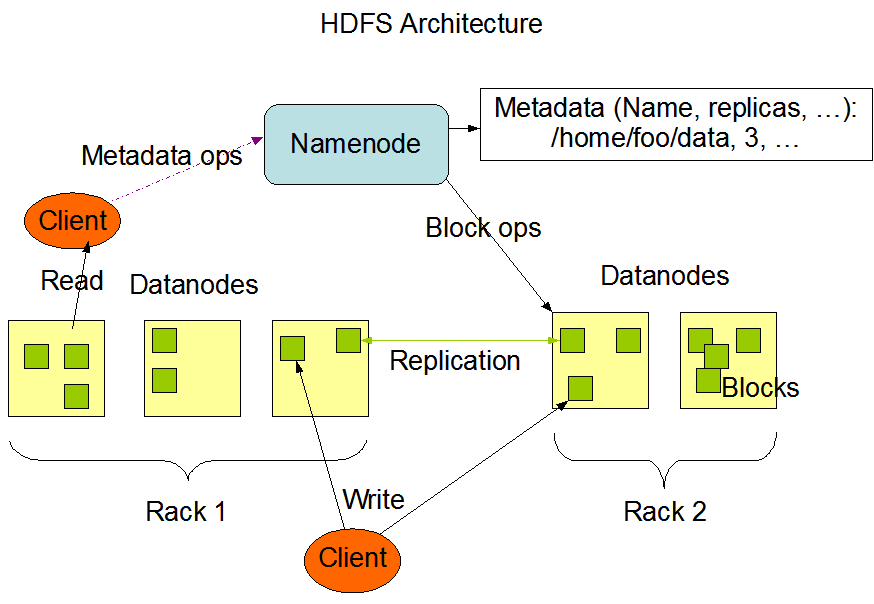
- 分散式文件存儲系統,其中有nameNode,dataNode,block,nameNode負責管理著dataNode,dataNode負責接收讀寫請求和nameNode協調工作,負責block快的創建和複製,nameNode存儲著元數據,datanode和block中的映射關係
-
-
- nameNode 存儲元數據 (用來描述數據的數據),負責管理dataNode 與dataNode 協調
- dataNode 負責nameNode的讀寫請求,用來存儲數據塊的節點,向nameNode報告自己的快信息
- block 數據快 hdfs 最小預設128mb 為一塊,沒一塊預設有3個副本
- rack 機架 用來放置存儲節點,提高容錯率,高吞吐量。優化存儲和計算
-
nameNode和SecondaryNameNode 之間的關係

fsimage 元數據的備份 會被載入到記憶體當中去
edits 讀寫請求的日誌文件
nameNode 會在啟動的時候載入 fsimage 和 edits ,這2個文件不會憑空出現,所以要格式化nameNode
當用戶在操作文件時,由於edits的增加,導致了nameNode啟動會越來越慢,所以就出現了SecondaryNameNode 可以簡單來說,他是nameNode的一個副本,當到達檢查點的時候,也就是hdfs 預設 1個小時 或者 日誌操作量級達到100w條的時候,此時SecondaryNameNode會將fsimage和edits載入過來進行合併,此時,若是有讀寫請求過來的時候會被載入到一個叫edits-inprogess的文件進行記錄讀寫請求,fsimage和edits合併之後會成為一個新的fsimage,而此時edits-inprogess會改名為edits
-
- 小問題 : 為什麼 一個塊的大小預設是128mb
- 在hadoop 1x 的時候預設快的大小為64 但是隨著硬碟的變大 在hadoop2x的時候 快的大小 變成了128m ,此時預設最佳狀態是定址時間是傳輸速度的100/1
- 小問題 : 為什麼 一個塊的大小預設是128mb
- mapReduce
-
- 概念 : 分散式計算框架。用於大規模的數據計算,採用並行計算,充分的利用了dataNode的物理存儲機制,採用了(Map)映射(Reduce)規約,他極大的方便了程式員不會分散式並行編程的情況下,將自己的程式運行在分散式系統上 ,思想就是 將一個鍵值對 放在map 里 然後 使用Reduce 進行統籌規劃,保證所有的映射的鍵值隊中每一個共用的鍵組
- mapReduce最擅長做的就是分而治之 ;
- 分 就是把一個龐大複雜的任務分解成若幹個簡單的任務來處理,簡單的任務包含有3層
- 相對於原來的數據要大大縮小
- 所有的任務中並行計算,且互不幹擾
- 就近計算原則
- 治之 Reduce 負責對map計算的結果進行統籌彙總
- 要實現mapReduce 首先得藉助一個資源調度平臺 Yarn
-
- Yarn
-
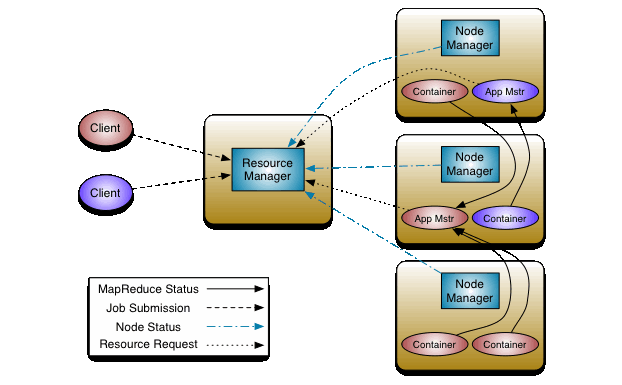
- 概念 Yarn 作為資源調度平臺 ,其中有一個最大的管理者,ResourceManager 負責著資源的統籌分配,還有各個節點的管理著,NodeManager 負責向ResourceManager進行資源狀態的報告,在NodeManager 中還有一個 MRAppMaster ,負責 申請計算資源,協調計算任務並和NodeManager一起執行監視任務
- ResourceManager 負責對集群的整體資源和計算做統籌規劃
- NodeManager 管理主機上的計算組員,負責報告自身的狀態信息
- MRAppMaster 負責向ResourceManager負責申請資源,協調計算任務
- YarnChild 做實際的計算任務
- Container 計算資源的抽象單位
-